




IT-beveiliging heeft altijd al een focus gehad op het voorkomen van dreigingen van hackers en interne fraudeurs. Als wij echter één ding hebben kunnen leren van eerder openbaar geworden cybercrime-incidenten, dan is het wel dat honderd procent beveiliging niet bestaat, maar ook dat daadwerkelijke inbraken veelal niet snel worden gedetecteerd. Organisaties dienen preventie randvoorwaardelijk in te richten, maar daarnaast ook detectie van en respons op cybercrime adequaat te regelen.
Beveiliging begint bij het bewustzijn van te beschermen waarden, het onderkennen van dreigingen, het vaststellen van rollen en verantwoordelijkheden, evenals het vaststellen van de volwassenheid die beveiligingsprocessen behoren te hebben. Daarna volgt de inrichting van een veilige IT-infrastructuur. Hoe kan echter beveiliging worden ingericht, zonder een overmaat aan maatregelen te introduceren?
Inleiding
Voor de komst van IT leek de wereld eenvoudig, alleen fysieke beveiliging was aan de orde. Organisaties die met hooggevoelige informatie omgingen, hanteerden (in beperkte mate) dataclassificatie en labeling (het markeren van dataclassificatie op documenten).
Met de komst van de eerste computers leek beveiliging zelfs nog eenvoudiger te kunnen worden, aangezien in centraal beheerde mainframes alleen applicaties via vooraf gedefinieerde functionaliteiten de data konden benaderen, en dan nog via strikte procedures. Met name transactionele data werd in deze mainframe-omgeving verwerkt.
Met de komst van pc’s veranderde de complexiteit van beveiliging wezenlijk. Gebruikers creëren en verwerken nu zelf data in documenten (files), en daarbij in het bijzonder non-transactionele data, en vaak betreft dit ook nog eens de meest gevoelige data.
Intussen zijn we al weer een stap verder. USB-sticks worden gebruikt voor het uitwisselen van gegevens, en helaas soms ook virussen en trojans. Via e-mail vindt phishing plaats, en worden gebruikers verleid programmatuur op de eigen pc te laten installeren. Eindgebruikers bewaren en verwerken zelfs documenten in de cloud.
Met de komst van sociale media en een nieuwe – jonge – generatie van gebruikers, gecombineerd met het benutten van privé-IT-middelen zoals smartphones en tablets binnen de eigen organisatie, lijkt het steeds onduidelijker of een afdoende niveau van IT-beveiliging is gerealiseerd.
Het is tijd voor bezinning. Kunnen we minder hard controls en meer soft controls hanteren? Welke eisen moeten echt aan beveiliging worden gesteld, waar moet beveiliging transparant in techniek worden geregeld, en waar moeten we kunnen steunen op beveiligingsbewustzijn van eindgebruikers, ontwikkelaars en beheerders? Regels voor IT-beveiliging zijn steeds uitgebreider en complexer geworden. Er zijn zelfs vaak meer regels dan gebruikers, beheerders en ontwikkelaars kennen. Het is dan ook tijd het moderne principe van ‘sturen met gevoel’ meer in te zetten voor data security.
Meer sturen met gevoel en daarmee bewustzijn is gewenst, vanwege de impact die een positieve cultuur (beveiligingsbewustzijn) en governance (organisatie, rollen en verantwoordelijkheden) kunnen hebben op data security, resulterend in adequate IT-beveiligingsprocessen en een veilige IT-infrastructuur (zie figuur 1).

Figuur 1. Oorzaak en gevolg.
In dit artikel worden dan ook de volgende onderwerpen behandeld, waarbij steeds wordt onderzocht of meer op gevoel kan worden gestuurd:
- beveiligingsbewustzijn;
- classificeren en labelen;
- beveiligingsmaatregelen in IT-processen en IT-infrastructuur;
- aantoonbaarheid van beveiliging.
Beveiligingsbewustzijn
Regelmatig stimuleren van beveiligingsbewustzijn stimuleert sturen met gevoel. Voor beveiligingsbewustzijn betekent dit, dat organisaties hieraan juist meer tijd en energie zouden moeten besteden, met als resultaat dat gebruikers en beheerders spontaan beter met data omgaan.
Gebruikers zelf lijken naïef: ‘Denken gebruikers nog wel genoeg na over het vereiste niveau van IT-beveiliging?’ Een goed voorbeeld is de introductie van smartphones en tablets in organisaties. Deze komen veelal binnen bij de Raden van Bestuur en dalen vervolgens af naar andere gebruikers in de organisatie. Vanwege gebruikersgemak en trendgevoeligheid is er het beeld dat organisaties dergelijke IT-middelen direct moeten kunnen gebruiken. Daarbij worden risico’s nogal eens (tijdelijk) geaccepteerd.
Bij het gebruik van smartphones en tablets is men zich echter niet altijd bewust van de waarde van de data die op deze IT-middelen worden opgeslagen en verwerkt, noch van de externe en interne dreigingen die aan de orde zijn.
Bij het nadenken over de waarde van data wordt veelal uitgegaan van de waarde van data voor de organisatie zelf. Het wordt echter steeds belangrijker bewust na te denken over data in het ecosysteem van samenwerkende organisaties. Denk bijvoorbeeld aan publiek geworden cybercrime, waarbij men het had voorzien op data buiten de aangevallen organisatie:
- Diginotar is aangevallen om digitale certificaten te creëren.
- RSA is aangevallen om SecurID-authenticatie-informatie te ontsluiten.
In het verleden is bij beveiliging de aandacht veelal gericht geweest op het aangeven van dreigingen, resulterend in angst en twijfel. Het blijkt echter belangrijk dat gebruikers meer leren nadenken over de waarden waarmee zij werken, en de waarden die daarmee dienen te worden beschermd. Dit vraagt om training in beveiligingsbewustzijn, die echter nauwelijks wordt gegeven. Als onderdeel van beveiligingsbewustzijn is aandacht gewenst voor het inschatten van waarden, het onderkennen van generieke beveiligingsvoorzieningen, en daarbij de beperkingen van beveiligingsvoorzieningen van IT-middelen.
Als onderdeel van de levenscyclus van data dient men het bewustzijn te versterken betreffende het omgaan met data security, opdat gebruikers en beheerders met data en systemen omgaan, als ware het hun eigen portemonnee met geld.
- Creëren. Overweegt een gebruiker voor welke stakeholders data van waarde is, en wat de omvang van deze waarde is? Kan men inschatten op basis van de onderkende waarde wie deze data mag kunnen inzien en/of bewerken? Is ook duidelijk welke metadata wordt gecreëerd, ofwel wat de documenteigenschappen zijn?
- Opslaan. Gegeven de waarde van data, is een gebruiker zich bewust waar de data mag worden opgeslagen, en of deze data dient te worden versleuteld (denk bijvoorbeeld aan het gebruik van faciliteiten zoals Dropbox)?
- Transporteren. Dient een gebruiker bij transport van data deze te versleutelen? Mag de data via e-mail of een USB-stick worden getransporteerd?
- Verwerken. Mag de data in de cloud worden verwerkt, moet de gebruiker hiertoe specifieke afspraken maken?
- Slapen. Is duidelijk wie eigenaar is van data als deze ‘slaapt’?
- Vernietigen. Zijn de vereisten van dataretentie bij gebruikers bekend? Is geborgd dat data tijdig of juist niet te vroeg wordt vernietigd?
Classificeren en labelen
Hooggevoelige data dient herkenbaar te zijn, data die intuïtief kan worden geclassificeerd, vraagt geen expliciete classificatie of labelen om daarmee zorgvuldig om te gaan. Dit maakt formeel classificeren en labelen voor de meeste data overbodig.
Onderkennen van classificatie
Slechts weinig gebruikers wordt gevraagd data te classificeren op basis van de waarde van de data, als een organisatie al dataclassificatie toepast. Organisaties die wel classificeren, hanteren veelal een zogenaamde BIV-classificatie (Beschikbaarheid, Integriteit en Vertrouwelijkheid), gericht op applicaties en minder op de data zelf.
Het classificeren van data kan op vele manieren plaatsvinden, en wordt veelal ervaren als complex en moeilijk te onderhouden. Daarom gebeurt classificeren van data in veel gevallen niet, onjuist of onvolledig. Bijgevolg vindt dan tevens geen expliciete labeling plaats. Daarmee is dan niet altijd herkenbaar voor derden wie de data mag inzien, laat staan waar deze mag worden opgeslagen en wanneer dient te worden besloten tot vernietiging.
Vaak bestaat er onbewust een perceptie van de gevoeligheid van data, op basis waarvan de distributie van data kan worden beperkt.
Het moge duidelijk zijn dat publieke media zoals Twitter, LinkedIn en Facebook slechts zijn bedoeld voor data die publiek mag zijn. Voor de data die binnen een organisatie wordt gebruikt, wordt de toegestane distributie al snel complexer. Het is aan te bevelen zo min mogelijk klassen van data te onderkennen, en klassen dusdanig te kiezen, dat deze voor gebruikers intuïtief zijn en ook functioneren als gebruikers deze niet spontaan onthouden. Denk in eenvoud bijvoorbeeld in klassen, door het hanteren van een onderscheidende huisstijl die door interne medewerkers duidelijk kan worden herkend. Op basis van de onderkende waarde (wat is het belang voor de organisatie, denk aan Intellectual Property, wat is de schade bij openbaar worden, etc.) kunnen de volgende klassen worden gehanteerd, die ondanks gebrek aan kennis hiervan door gebruikers spontaan zouden worden toegepast:
- publiek (bedoeld voor klanten en andere belanghebbenden);
- intern (bedoeld voor alle medewerkers, bij voorkeur niet extern te verspreiden);
- vertrouwelijk (bedoeld voor een specifieke kleine groep van personen, waarbuiten de data niet toegankelijk mag zijn);
- persoonlijk (veelal intuïtief, bedoeld voor een specifieke persoon, bijvoorbeeld HR-specifieke informatie).
Maak verschillen in classificatie vooral expliciet in situaties waarin het onderscheid in classificatie minder spontaan naar voren komt. Een voorbeeld is het gebruik van de classificaties ‘Intern’ en ‘Vertrouwelijk’.
Typen van data
Bij het classificeren van data kan verschillend worden omgegaan met gestructureerde en ongestructureerde data:
- Gestructureerde data wordt verwerkt door een applicatie en is veelal geclassificeerd door het classificeren van de verwerkende applicatie. Daarmee kan automatisch op rapportages vanuit de applicatie een classificatie worden afgedrukt. Een goed voorbeeld vormen salarisstroken aan personeelsleden, waarop het label ‘Persoonlijk’ kan worden gedrukt.
Een organisatie dient zich wel expliciet af te vragen of alle relevante gestructureerde data wel degelijk adequaat op de radar staan. Bij salarisstroken is duidelijk dat salarisgegevens persoonlijk zijn, deze gegevens staan dan ook op de radar. Er wordt echter ook vaak op gestructureerde wijze data opgeslagen, bijvoorbeeld via marketingwebsites, die niet de classificatie ‘Persoonlijk’ lijken te hebben, maar die deze classificatie feitelijk wel behoren te hebben. Denk hierbij ook aan beveiligingsincidenten waarbij privégegevens van klanten, zoals e-mail- en overige gegevens, publiek werden gemaakt door hackers van marketingwebsites. Terstond bleek dat privacygevoelige gegevens op straat lagen. Op deze wijze werd duidelijk dat deze data diende te zijn geclassificeerd als ‘persoonlijk’, met daarbij behorende afdoende beveiligingsmaatregelen.
Het is daarom aan te bevelen voor elke applicatie eerst een adequaat overzicht op te stellen van verwerkte data, en eerst deze data te classificeren, en pas daarna de applicatie zelf te classificeren.
Aangezien gestructureerde data voor de gebruikers wordt beheerd, is het zinvol deze daadwerkelijk te classificeren. - Ongestructureerde data is minder eenvoudig vast te stellen. Het is voor ongestructureerde data relevant dat gebruikers een besef hebben van de mate van beveiliging betreffende de door hen gebruikte IT-middelen (laptop, tablet, smartphone) en centrale IT-voorzieningen (file servers en andere shares) om gevoelige data op te slaan. Daarbij dient duidelijk te zijn wie welke data van welke gevoeligheid waar mag opslaan, en voor welke tijdsduur.
Aangezien ongestructureerde data door gebruikers zelf wordt beheerd, dient te worden gestimuleerd dat een gebruiker kan sturen met gevoel, ofwel de classificatie moet spontaan juist kunnen worden ingeschat bij het selecteren van in te zetten IT-voorzieningen zoals e-mail, tablets en fileservers.
Maatregelen in IT-processen en IT-infrastructuur
Beveiligingsvoorzieningen dienen zoveel mogelijk transparant in de generieke IT-voorzieningen te zijn gerealiseerd, hetgeen ook is wat een gebruiker intuïtief verwacht.
Beveiligingsvoorzieningen dienen zich te richten op maatregelen voor zowel preventie, als detectie en respons.
Bij het inrichten van beveiligingsmaatregelen verdient het aanbeveling uit te gaan van de verwachtingen van de eindgebruiker, en van de waarde van data waarmee veelal in de organisatie wordt gewerkt. Zo kan bij een researchafdeling worden uitgegaan van veelal hooggevoelige data zoals intellectueel eigendom, en bij een winkel van laaggevoelige data zoals product-, prijs- en verkoopinformatie. Een organisatie dient zich daarbij bewust te zijn van dreigingen die gericht zijn op de eigen organisatie, evenals indirecte dreigingen, in gevallen waarbij de organisatie een onderdeel is van een grotere keten.
Eenvoud kan bestaan uit het beperken van vereiste maatregelen (bijvoorbeeld niet afsluiten van USB-poorten), en ook uit het zonder meer toepassen van maatregelen, waardoor uitzonderingen geen complexiteitsverhogingen meer tot resultaat hebben (bijvoorbeeld standaard inrichten van veilige laptops met versleuteling van harddisks en gebruik van persoonlijke firewalls).
Een eenvoudig proces voor het realiseren en in stand houden van data security is in figuur 2 weergegeven. Eerst wordt risicogebaseerd geselecteerd welke beveiligingsmaatregelen zijn vereist. Vervolgens wordt compliance-gebaseerd vastgesteld of deze maatregelen in stand worden gehouden. Als dat niet zo blijkt te zijn, wordt een non-compliance expliciet maar risicogebaseerd opgevolgd.
Dit beveiligingsproces voor het realiseren van een veilige IT-dienst kan worden doorlopen zowel voor gestructureerde data als voor ongestructureerde data.
Bij gestructureerde data wordt gevoeligheid van de verwerkende applicatie vastgesteld, en worden daarop de beveiligingsmaatregelen aangepast.
Echter, bij ongestructureerde data kunnen mogelijk vele IT-diensten (IT-hulpmiddelen en applicaties) de data verwerken of opslaan. In het geval van ongestructureerde data wordt het beveiligingsproces dan ook niet voor data, maar voor generieke IT-diensten (zoals fileserver, smartphones en tablets, en internet storage services) doorlopen. Hierop kan ongestructureerde data (zoals e-mail) worden gelezen. Bij dergelijke IT-diensten dient daarom te worden uitgegaan van de mogelijkheid dat de hoogste classificatie van data wordt gelezen. Aan de hand van deze classificatie kunnen vervolgens beveiligingsmaatregelen worden geselecteerd. Afhankelijk van de gevoeligheid van data kunnen zwaardere beveiligingsvoorzieningen worden gekozen, zoals:
- gebruikersnaam en wachtwoord, óf een tweede vorm van authenticatie zoals een token;
- onversleutelde opslag op een beveiligde server, óf versleutelde opslag op dezelfde beveiligde server;
- standaardtablet voor gebruik e-mail, óf e-mail in een zogenaamde versleutelde sandbox-applicatie.
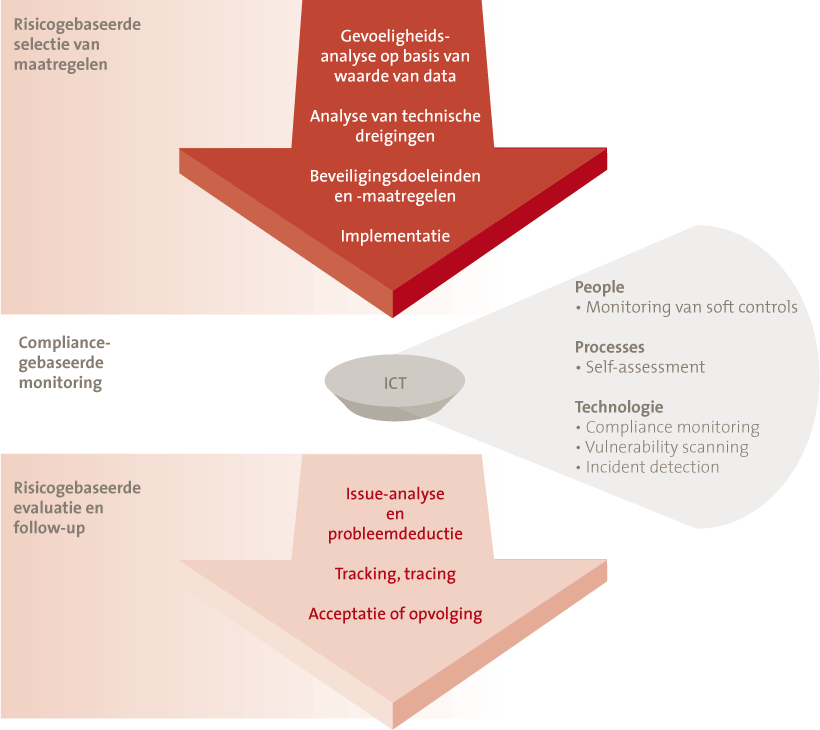
Figuur 2. Beveiligingsproces voor data en systemen.
Het selecteren van beveiligingsmaatregelen is eenvoudiger gezegd dan gedaan. Besef dat voor elke IT-dienst vier maatregelgebieden zijn te onderkennen (zie figuur 3).
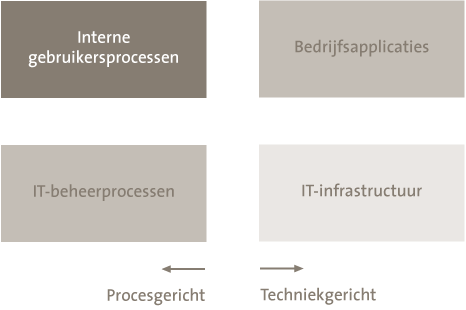
Figuur 3. Maatregelgebieden voor data security.
Van elk van deze maatregelen wordt een voorbeeld gegeven. Bij interne gebruikersprocessen kan een autorisatieproces aan de orde zijn om toegang te krijgen tot data. Binnen bedrijfsapplicaties kan een vierogenprincipe zijn gerealiseerd, en kan encryptie worden verzorgd. In de IT-infrastructuur kan beveiliging worden geregeld door het toepassen van stringente instellingen van beveiligingsparameters. Tot slot kan beveiliging via IT-beheerprocessen worden geborgd, door het inrichten van preventieve processen voor bijvoorbeeld patching en toegangsbeheer, evenals processen voor detectie en respons in geval van het overtreden van toegangsregels.
Aantoonbaarheid van data security
Juist bij transparantie van informatiebeveiliging is het zinvol periodiek onder de motorkap te controleren of het vertrouwen in data security terecht is.
Het 3-lines-of-defense-model stimuleert hierbij efficiëntie. Zelfcontrole helpt ook de tijdige detectie van beveiligingsrisico’s.
Juist als in de organisatie meer wordt gestuurd op gevoel, dient een organisatie zich ervan te vergewissen of adequate beveiligingsmaatregelen zijn getroffen, maar wel met mate.
Met het aantonen van adequate beveiliging op basis van het 3-lines-of-defense-model wordt geborgd dat eerstverantwoordelijken zelf hun verantwoordelijkheid dragen, en dit daarna efficiënt en effectief aantonen aan het management van een organisatie, dat daarmee zijn eigen verantwoordelijkheid kan dragen voor de door hem beheerde data, die van hemzelf en zijn klanten.
Hiermee wordt ook de efficiënte en effectieve inzet van afdelingen zoals IT, risk management, beveiliging en interne audit ondersteund.
Voorafgaand aan het aantonen van data security is het verstandig de scope vast te stellen: voor welke data of IT-dienst dient te worden aangetoond dat deze adequaat wordt beveiligd en voor welke data en IT-diensten juist niet? Is alle gevoelige data binnen de organisatie op de radar? Door periodiek voor de breedte van de organisatie datastromen te onderkennen, blijft gevoelige data op de radar. Denk bijvoorbeeld aan projectdata op fileservers, klantdata op een oude server waarvan de bijbehorende applicatie zonder dat men het weet nog actief is, ook al zijn er geen gebruikers meer, en denk aan data op oude media en in de cloud.
Bij scoping is het van belang uit te gaan van de waarde van de data, voor de eigen organisatie, voor andere stakeholders, en voor bijvoorbeeld hackers. Denk ook aan mogelijke effecten van een WikiLeaks, of de openbaring van data bij een inbraak.
Ontwikkeling van dreigingen in de keten en gestelde eisen
Organisaties hoeven niet altijd betrokken te zijn bij de ontwikkeling van dreigingen. Deze dreigingen kunnen ook buiten de eigen organisatie liggen. Zo hebben diverse organisaties in branches zoals beveiliging en transport moeten onderkennen dat bij uitval van GSM-netwerken, de eigen diensten aan klanten ook uitvallen.
Het is dan ook zinvol periodiek de ketens in kaart te brengen, en daarbinnen aan te tonen dat de eigen verantwoordelijkheden adequaat zijn genomen. In het geval van de afhankelijkheid van GSM-netwerken kan bijvoorbeeld de vraag worden gesteld of back-upvoorzieningen dienen te worden gerealiseerd.
Huidige compliance van maatregelen aan eerder gestelde eisen
Let erop dat bij het monitoren van compliance zowel procesgerichte als techniekgerichte maatregelen de aandacht krijgen (zie ook figuur 3). In de afgelopen jaren is vanuit efficiëntieoverwegingen en mogelijk zelfs kennisoverwegingen steeds meer de aandacht gericht op monitoring van processen. Daarmee wordt echter niet geborgd dat de juiste techniek in stand wordt gehouden. Monitoring van techniek vraagt expliciet de aandacht!
Risicoafweging huidige eisen en non-compliances
Op basis van monitoring wordt aangetoond of non-compliances aanwezig zijn. Een non-compliance kan worden geaccepteerd of gemitigeerd.
Steeds meer ontstaat de behoefte aan een dashboard van non-compliances en risico’s, opdat het management in staat is adequate keuzen te maken betreffende te accepteren en te mitigeren non-compliances, evenals de snelheid waarmee mitigeren van non-compliances zou moeten plaatsvinden. Pas bij deze risicoafweging op met kostenoverwegingen alleen, en zet kosten van beveiligen af tegen de te beschermen waarden!
Tot slot
In de toekomst is meer sturen met gevoel van belang, omdat het te complex en kostbaar blijkt om alle data security-maatregelen in regels te vatten en door gebruikers en beheerders te laten onthouden. Voor maatregelen waarop echt wordt gesteund, dat wil zeggen voor de gevoelige data en systemen, is het van belang deze maatregelen krachtig te borgen, maar ook de aantoonbaarheid van deze maatregelen te regelen en over de uitkomsten te rapporteren.
Daarom gelden voor de leiding van organisaties de volgende prioriteiten:
- Beveiligingsbewustzijn
- Besef dat het landschap verandert, dreigingen zijn actueel, beveiligingsmaatregelen leveren geen honderd procent zekerheid; dat is altijd zo geweest.
- Beveiligingsbewustzijn continu stimuleren, bijvoorbeeld door periodieke campagnes.
- Dataclassificatie en labeling
- Data security inrichten, specifiek voor de eigen organisatie, op basis van de onderkende waarde van data en systemen, en de rol van de organisatie in gerelateerde bedrijfsmatige ketens.
- Formele classificatie en labeling beperken.
- Beveiligingsmaatregelen
- Voorbeeldgedrag handhaven, bijvoorbeeld door voorzichtigheid te betrachten bij innovaties zoals smartphones en tablets. Voorkom dat de leiding van de organisatie deze middelen onveilig inzet en borg tijdig dat alleen veilige inzet mogelijk is.
- Wees niet penny wise and pound foolish, maar investeer bewust, bezuinig niet op het beheersen van grote risico’s. Denk bijvoorbeeld aan hulpmiddelen voor monitoring. Hiermee wordt het mogelijk gemaakt te controleren of essentiële beveiligingsmaatregelen adequaat worden toegepast.
- Aantoonbaarheid
- Pas het 3-lines-of-defense-model toe voor beveiliging. Met een hogere graad van volwassenheid van beheersing (blijkend uit aantoonbaarheid) wordt beveiligen efficiënter en tevens een gestructureerd en continu proces.