




In dit artikel staat datakwaliteit centraal. Veel bedrijven en organisaties zien datakwaliteit als een gegeven. Iets wat er van nature is. Andere organisaties hebben inmiddels ondervonden dat dit een verkeerde aanname is en dat datakwaliteit geen vanzelfsprekendheid is. Zij hebben datakwaliteitsprogramma’s opgezet omdat ze zich bewust zijn van het belang van goede data voor de efficiënte en effectieve aansturing van de bedrijfsvoering. Om goede datakwaliteit te kunnen bereiken is het nodig dat elke organisatie op gestructureerde wijze vastlegt wat wordt verstaan onder ‘goede’ data en op welke wijze wordt bewaakt dat de kwaliteit van data ook ‘goed’ blijft. De beschrijving van deze thema’s vormt de kern van dit artikel. Daarna wordt afgesloten met enkele aanbevelingen voor de opzet en inrichting van datakwaliteitsprogramma’s.
Inleiding
Datakwaliteit staat de laatste jaren in het middelpunt van de belangstelling bij bedrijven en organisaties. Het afgelopen decennium is de hoeveelheid data en databases waarin deze data zijn opgeslagen, enorm toegenomen. Door de lage opslagkosten van data en mogelijkheden om data nu in de ‘cloud’ op te slaan zal deze trend zich onverminderd voortzetten. Om deze databases te ontsluiten zijn grote investeringen gedaan in dure business intelligence software. De oplossing werd daarbij gezocht in de techniek. Voorbijgegaan werd aan de vraag of de in deze databases opgeslagen data wel van voldoende kwaliteit zijn. Inmiddels is het algemeen bekend en helaas ook geaccepteerd dat de kwaliteit van data in relationele databases matig tot slecht is. Bij één van de organisaties waar ik als adviseur actief was, werd door de leiding geaccepteerd dat de data in een database met 7 miljoen records gemiddeld vier tot vijf procent fouten bevatte. Als we ervan uitgaan dat elk record circa 20 velden bevatte en er in deze database dus 140 miljoen data geregistreerd waren, dan bevatte deze database dus potentieel circa 7 miljoen data waarvan de kwaliteit niet goed was.
Foute data zijn net een besmettelijk virus. Ze verspreiden zich in de organisatie, worden in andere databases opgenomen, dienen als referentiedata, of staan aan de basis van managementinformatierapportages. Met de toenemende omvang van databases neemt ook de omvang van inaccurate data toe. Het gevolg is dat inaccurate data verantwoordelijk zijn voor slechte bedrijfsbeslissingen, die inefficiënte en ineffectieve bedrijfsvoering tot gevolg hebben, waardoor bedrijven en organisaties vele miljoenen euro’s schade lijden. Nu het economisch minder voor de wind gaat zijn veel bedrijven op zoek naar kostenbesparingen en mogelijkheden om hun omzet te vergroten. De strekking van dit artikel is: stop met zoeken en start een datakwaliteitsprogramma! Het beheer van datakwaliteit is één van de belangrijkste thema’s in de informatietechnologie van de komende jaren[Zie ook een recente studie van de Hackett Group ‘The CFO’s Agenda: Finance Top Issues in 2011’, waarin wordt gesteld dat ‘data governance’ hoog op de agenda van de CFO staat. ].
In dit artikel wordt achtereenvolgens stilgestaan bij de vraag wat datakwaliteit is en wat de oorzaken zijn van slechte datakwaliteit. Vervolgens wordt ingegaan op het datakwaliteitsonderzoek als basis voor een organisatiebreed datakwaliteitsprogramma.
Datakwaliteit
Datakwaliteit laat zich het best omschrijven als ‘data die voldoet aan de eisen die een bedrijf of organisatie daaraan stelt’. Wat die eisen zijn, is dus afhankelijk van dat bedrijf of die organisatie. Of meer specifiek, van de aard en omvang van de bedrijfsvoering. Daarmee is duidelijk dat er geen algemeen raamwerk van eisen is dat voor ieder bedrijf van toepassing is. Waar het bij de ene organisatie vooral van belang kan zijn om tijdig data beschikbaar te hebben, om bijvoorbeeld snel op markttrends in te kunnen springen, zal het bij een andere organisatie geen probleem zijn om de data later beschikbaar te hebben zolang de data maar honderd procent juist zijn, zoals de specificaties voor grondstoffen en/of halffabricaten in een productieproces. Ook kunnen de verschillende bedrijfsprocessen andere eisen stellen aan de datakwaliteit. Waar de inkoop- en logistieke processen gericht zullen zijn op een optimaal proces met specifieke eisen aan leveranciers-, contract- en artikeldata, zal een verkoop- en marketingproces weer meer flexibiliteit van de klant-, order- en leveringsgegevens vragen.
In tabel 1 is een overzicht opgenomen van kwaliteitsaspecten.
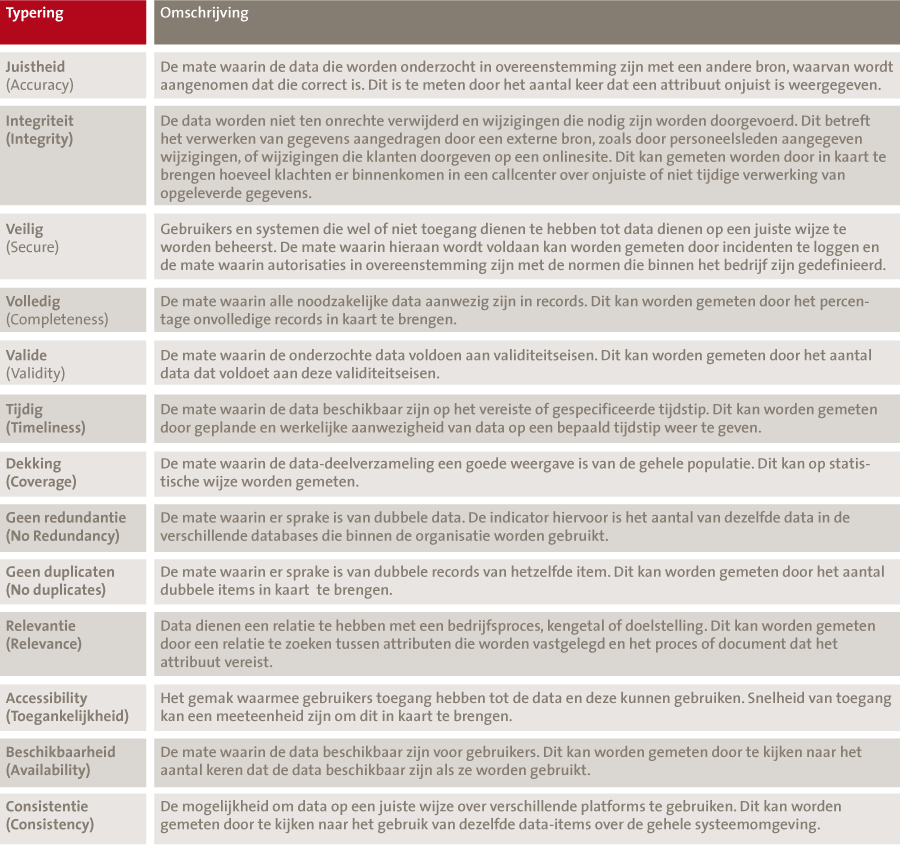
Tabel 1. Datakwaliteitsaspecten (bron: [Huan99]).
In de praktijk zullen bedrijven een meer pragmatische benadering kiezen en enkele van deze kwaliteitsaspecten van toepassing verklaren op de data in hun omgeving. Soms zijn de datakwaliteitseisen gerelateerd aan wet- en regelgeving. Binnen de financiële sector, specifiek voor de nieuwe kaderrichtlijn voor verzekeraars (Solvency II) bijvoorbeeld, zijn de volgende kwaliteitseisen vermeld: ‘appropriate’, ‘complete’ en ‘accurate’. Als het gaat om het naleven van eisen van informatiebeveiliging dan zijn de toepasselijke kwaliteitseisen veelal gerelateerd aan ‘vertrouwelijkheid’, ‘integriteit’ en ‘beschikbaarheid’. Later in dit artikel wordt stilgestaan bij de vraag op welke wijze bedrijven tot een raamwerk van kwaliteitseisen kunnen komen waarmee zij hun datakwaliteit kunnen borgen en kunnen monitoren.
Oorzaken van slechte datakwaliteit
Data zijn niet statisch. Data zijn voortdurend in beweging. Zij worden gecreëerd, aangepast, uitgewisseld, opgeslagen, vernietigd en dat soms in een tijdsbestek van enkele seconden. Elke actie heeft in potentie de dreiging in zich dat deze impact heeft op de kwaliteit van de data. Iedereen die met data werkt zal zich meerdere keren in zijn leven verwonderd hebben over het feit dat feitelijk voor juist gehouden data op zekere dag een waarde of vorm hebben aangenomen die niet strookt met de juistheid, zonder dat hij of zij daar zelf enige betrokkenheid bij heeft gehad. De oorzaken hiervoor zijn legio. Een eerste onderscheid kan worden gemaakt tussen actief en passief datagebruik. Bij actief datagebruik gaat het om processen die zich specifiek op de data richten. Hierbij kan worden gedacht aan dataconversie, systeemconsolidaties, handmatige data-invoer, batchinvoer, real-time-invoer, gegevensverwerking, dataopschoning en data-integratie. Passief datagebruik omvat onder meer: wijzigingen in het datagebruik die niet tot wijziging in de data zelf hebben geleid, systeem-upgrades, nieuwe vormen van datagebruik, het verlies van kennis, processen die worden geautomatiseerd. Zowel het actieve als het passieve gebruik van data door organisaties leidt tot verlies aan datakwaliteit. Zie hiervoor ook het voorbeeld in het kader. Wij kunnen dus concluderen dat datakwaliteit niet vanzelfsprekend is en dat datakwaliteit door diverse invloeden kan eroderen. Organisaties dienen daarom op een actieve manier datakwaliteit te borgen in hun processen. Het datakwaliteitsonderzoek helpt bij het vaststellen van de feitelijke datakwaliteit en het borgen daarvan in organisaties.
Zo kon het in 2009 voorkomen dat levenspartners van wie de één een inkomen had en de ander geen inkomen, en die al jaren een algemene heffingskorting van de Belastingdienst ontvingen, op zekere dag een navordering kregen omdat zij dit bedrag ten onrechte hadden ontvangen. Door een fout in het systeem van de Belastingdienst was de automatische koppeling tussen de door de partner betaalde belasting en de heffingskorting van de andere partner verdwenen.[Zie: http://www.elsevierfiscaal.nl/fiscaal-actueel/themas/navordering/blog/10/kan-de-belastingdienst-zich-zoveel-fouten-permitteren.]
Datakwaliteitsonderzoek
De doelstelling van een datakwaliteitsonderzoek is om ‘foutieve’ data te identificeren, de impact op de bedrijfsprocessen in te schatten en corrigerende acties uit te voeren.
Idealiter zouden organisaties geen fouten in hun databases willen hebben. In een ideale wereld zouden wij ons kunnen voorstellen dat wij in staat zouden zijn om alle data-elementen te onderzoeken en vast te stellen of zij ‘fout’ of ‘goed’ zijn. Er zijn in de praktijk ten minste twee oorzaken die dit verhinderen. Ten eerste zou je voor elk data-element in de database moeten gaan vaststellen wat de werkelijke waarde van dit element zou moeten zijn. Je hebt dan steeds een betrouwbare bron nodig waaraan de waargenomen waarde getoetst kan worden. Die bron is niet altijd voorhanden. En als die wel voorhanden is, dan doemt de tweede uitdaging op, namelijk dat het uitvoeren van de toets zoveel (handmatige) tijd kost, dat het niet loont om die uit te voeren. Als wij in de masterdata voor materialen een onderzoek willen uitvoeren of de leveranciersaanduiding van alle materialen juist is, dan zouden wij (bij gebrek aan een onafhankelijke bron) alle leveranciers moeten aanschrijven en voor elk individueel materiaal moeten nagaan of de door ons in het systeem vermelde typeaanduiding overeenkomt met die van de leverancier. Als we bedenken dat sommige bedrijven vele duizenden materialen in hun systemen hebben staan, dan is duidelijk dat dit niet op een efficiënte wijze is uit te voeren. Als we zouden willen onderzoeken of de adressen van onze leveranciers nog juist en volledig zijn, dan zouden we alle leveranciers kunnen contacten en desgewenst de KvK-gegevens raadplegen. Dit kost heel veel tijd.
Voor beide uitdagingen zijn deels oplossingen voorhanden. De belangrijkste oplossing is het gebruik van computers bij het uitvoeren van datakwaliteitsanalyses. Dit stelt ons in staat niet alleen grote hoeveelheden data snel aan de hand van kwaliteitscriteria te onderzoeken. Het stelt ons tevens in staat op geautomatiseerde wijze andere (betrouwbare) bronnen te raadplegen aan de hand waarvan wij de kwaliteit van onze data-elementen kunnen vaststellen. Voorbeelden hiervan zijn de al eerder vermelde KvK-bestanden, maar ook Dun & Bradstreet-adresbestanden, GS1 DAS[Zie: http://www.gs1.nl/support/gs1-das/.]. De inzet van automatisering en het raadplegen van onafhankelijke bronnen helpen bij het vergroten van de kwaliteit van data. Bronnen die als authentieke bron bekendstaan bieden daarbij de meeste toegevoegde waarde. Denk daarbij aan de Gemeentelijke Basisadministratie.
Het datakwaliteitsonderzoek verloopt in de regel volgens vijf in tabel 2 omschreven fasen.
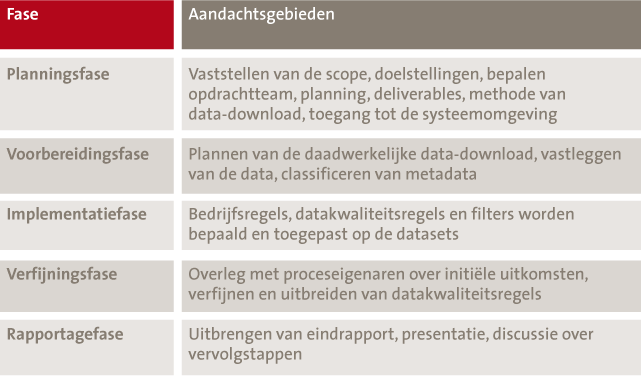
Tabel 2. De vijf fasen van datakwaliteitsonderzoek.
Hierna zal op elk van deze fasen worden ingegaan.
Planningsfase
Het bepalen van de scope van het datakwaliteitsonderzoek is een essentieel onderdeel. De te kiezen scope is mede afhankelijk van de doelstelling van het onderzoek. Grofweg kan onderscheid worden gemaakt tussen de in figuur 1 weergegeven doelstellingen.

Figuur 1. Doelstellingen van datakwaliteitsonderzoek.
Bewustwording
Veel organisaties weten niet of zij een datakwaliteitsprobleem hebben. Bij deze organisaties is geen sprake van een ingebedde datakwaliteitsfunctie en data-analyses en als dergelijke analyses al hebben plaatsgevonden, dan is dat gebeurd op ad-hocbasis. Er is geen structuur voor het periodiek en gestructureerd analyseren van datakwaliteit, daarover rapporteren en zo nodig correctieve acties nemen. Het initiatief om een datakwaliteitsonderzoek uit te voeren kan gezien worden als een ‘bewustwordingsfase’. Vanuit IT of vanuit de bedrijfsprocessen zijn er wel signalen dat er issues zijn met de kwaliteit van data. Een data-analyse wordt dan gezien als het instrument om bevestiging te krijgen voor de datakwaliteitsissues, waarmee de leiding overtuigd kan worden om een ‘datamanagementprogramma’ te starten.
Een voorbeeld hiervan betreft een recent uitgevoerd datakwaliteitsonderzoek voor een internationale organisatie. De CIO van deze organisatie onderkende dat de huidige datakwaliteit voor verstoringen in de processen zorgde, maar wist niet hoe groot ‘het probleem’ was. Verder had hij ook feiten nodig om de aard en omvang en de noodzaak tot het starten van een datakwaliteitsverbeteringsprogramma te onderbouwen. In het onderzoek zijn gegevens van materialen, klanten en leveranciers onderzocht op een aantal kwaliteitsaspecten. Het onderzoek heeft geleid tot een concreet stappenplan om de datakwaliteit te verhogen en initiatieven zijn opgestart voor een datamanagementprogramma.
(Master-)datamanagementprogramma
Organisaties hebben een (master-)datamanagementprogramma gestart. Als onderdeel van dit programma worden gedurende de looptijd van het project ‘metingen’ verricht op de kwaliteit van masterdata om na een nulmeting voortgaande vast te stellen of en zo ja, in welke mate de kwaliteit van masterdata gedurende het programma verbetert. Voor meer informatie over de opzet en uitvoering van een (master-)datamanagementprogramma zie [Jonk11].
Migratie naar nieuw systeem
Er is sprake van een grootschalig IT-vernieuwingsproject, waarbij data uit ‘legacy-systemen’ worden overgebracht naar een nieuwe geïntegreerde systeemomgeving. In dat geval dienen de over te zetten data te worden geharmoniseerd om in de nieuwe omgeving te kunnen worden gebruikt. Datakwaliteitsanalyses worden dan gebruikt om op basis van de kwaliteitseisen die aan de data in de nieuwe systeemomgeving worden gesteld, vast te stellen of de legacy-data aan deze eisen voldoen. Door het roterend uitvoeren van kwaliteitsonderzoeken, het opschonen van legacy-data en het weer opnieuw onderzoeken van de kwaliteit wordt zo toegewerkt naar een situatie waarin de te migreren dataset (zoveel mogelijk) voldoet aan de kwaliteitseisen van de nieuwe omgeving.
De datakwaliteitsanalyse waarvoor de aanleiding ligt in de wens om de organisatie bewust te maken van het hebben van datakwaliteitsissues, lijkt op het eerste gezicht ten aanzien van de scope, doorlooptijd en daarmee ook voor het budget een aantrekkelijke vorm. Er kan voor worden gekozen om een betekenisvol dataobject als uitgangspunt te nemen voor een kwaliteitsanalyse. Veelal wordt dan de nadruk gelegd op een object waarvan de sponsor het onbevestigde vermoeden heeft dat hier sprake is van datakwaliteitsissues. De scope wordt dan in nauw overleg bepaald op dit object. We zien vandaag de dag dat organisaties vooral worstelen met het actueel en consistent houden van masterdata voor materialen. Het zal dan ook niet bevreemden dat in de bewustwordingsfase veelal wordt gekozen voor dit dataobject. De volgende stap is dat, indien het budget en de doorlooptijd beperkt zijn, een outside-in view test kan worden uitgevoerd. Hierbij zal het datakwaliteitsteam zonder nadere verdieping in het bedrijfsproces en de toepasselijke bedrijfsregels (‘business rules’), maar met gebruikmaking van generieke kwaliteitsregels die zijn gebaseerd op ervaringen bij andere organisaties (‘better practice’-queries), geautomatiseerd een analyse uitvoeren op de dataset. Inderdaad is uit oogpunt van scope en budget dit een aantrekkelijk alternatief. De effectiviteit van deze vorm van datakwaliteitsanalyse is echter beperkt, aangezien de toegepaste ‘better practice’-filters over het algemeen zeer generiek zijn en alleen indien de organisatie nog in de beginfase van datamanagement staat relevante resultaten geven. Kwaliteitsaspecten die bij deze vorm onderzocht worden zijn bijvoorbeeld:
- niet-ingevulde attributen;
- dubbele namen, materiaaltypen, adresssen;
- onjuiste namen, adressen (bij gebruik van een gekoppeld adressenbestand).
Verder kan met behulp van ‘profiling’-technieken inzicht worden gekregen in de structuur van tabellen en datasets en waardepatronen in attributen (minimale en maximale waarde, gemiddelde, spreiding van het voorkomen in aantallen en percentage). De effectiviteit van dergelijke scans is ook beperkt. Bij gebrek aan een concrete norm voor datakwaliteit kan niet worden vastgesteld of de waargenomen waarden ‘goed’ of ‘fout’ zijn.
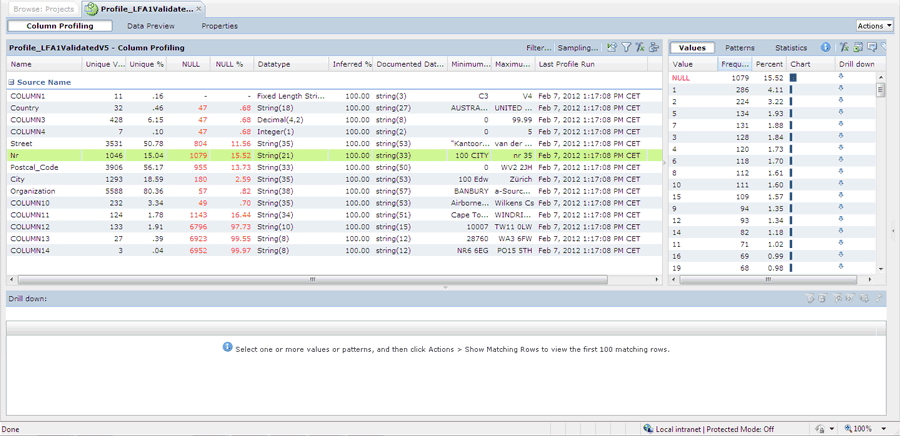
In dit voorbeeld is de tabel LFA1 (leverancier) uit een SAP-systeem onderzocht door middel van profilingtechnieken. Van het veld ‘nummer’ is een ‘profile’ gemaakt. Wat opvalt is dat in meer dan vijftien procent van alle records er geen waarde in dit veld is ingevuld. Dit kan aanleiding vormen om juist deze gevallen in overleg met de organisatie verder te bespreken.
Om de effectiviteit van een scan met beperkte doch zorgvuldig gekozen scope groter te maken is interactie tussen de data-analisten en de organisatie essentieel. Deze interactie is erop gericht om meer en betere bedrijfsregels boven tafel te halen, die dan vervolgens op de gekozen dataset kunnen worden toegepast. Vanuit kostenoogpunt heeft de interactie met de organisatie een sterk opdrijvende werking. Het onderzoeken en definiëren van bedrijfsregels is arbeidsintensief. Maar indien de bewustwordingsfase wordt beperkt tot één of enkele dataobjecten is het budget nog altijd lager dan wanneer alle relevante objecten in scope worden genomen. Het argument van beperking van het onderzoeksbudget valt echter vrijwel weg indien ervoor wordt gekozen om het onderzoek te richten op een deel van de data van het object. Bijvoorbeeld van een dataset van 50.000 artikelen worden alleen 100 artikelen onderzocht. Op het eerste gezicht lijkt dit een goedkopere oplossing dan het onderzoeken van alle materialen. Bedacht dient echter te worden dat het definiëren van de bedrijfsregels losstaat van het aantal records dat binnen een object wordt onderzocht. Het is zeer waarschijnlijk dat voor de dataset van 50.000 records dezelfde bedrijfsregels worden gebruikt als voor een deelverzameling van die dataset.
Als de aanleiding voor een datakwaliteitsonderzoek is gelegen in een organisatiebreed masterdatamanagementprogramma (MDM-programma), dan is de scope een directe afgeleide van de scope van dit programma. Richt het MDM-programma zich bijvoorbeeld op het masterdatabeheer van leveranciers-, klant- en materiaalgegevens, dan zal het datakwaliteitsonderzoek ook deze scope hebben. De doelstelling van het datakwaliteitsonderzoek is zoals hiervoor is vermeld het gedurende het programma aanleveren van informatie over de feitelijke datakwaliteit, om daarmee inzichtelijk te krijgen in hoeverre het programma effectief is. Vanuit kostenoogpunt is dit een omvangrijk programma. Alle elementen van het datakwaliteitsonderzoek komen hierbij aan de orde. Verder wordt lopende het programma ook aandacht besteed aan het opzetten van een datakwaliteitsbeheerorganisatie.
In het geval dat er sprake is van een IT-systeemintegratie, waarbij de doelstelling van het datakwaliteitsonderzoek is om vast te stellen in hoeverre datasets voldoen aan de kwaliteitseisen van de ontvangende systemen, is de scope vanzelfsprekend gerelateerd aan de objecten die worden gemigreerd.
Opdrachtteam
Onderdeel van de planningsfase is verder het bepalen van het opdrachtteam. Datakwaliteitsanalyses vragen samenwerking tussen technische specialisten en processpecialisten. De technische specialisten bezitten kennis en ervaring van tabelstructuren, het bouwen en analyseren van queries en data-analysetechnieken, zoals het interpreteren van uitkomsten en het herkennen van patronen. De processpecialisten zijn afkomstig uit het bedrijfsproces en hebben daarin een sturende rol. Hun aandeel in de data-analyse richt zich op het in samenspraak met de technische specialisten identificeren, uitwerken en testen van bedrijfsregels, die als kwaliteitsaspect in de datakwaliteitsanalyses worden gebruikt. IT is vaak betrokken om in aanvulling op de technische specialisten informatie te geven over tabelstructuren, de werking van het systeem en te zorgen voor het downloaden van de data.
Voorbereidingsfase
In de voorbereidingsfase kunnen de in figuur 2 weergegeven activiteiten worden onderscheiden.

Figuur 2. Activiteiten in de voorbereidingsfase.
Data laden
Het cyclisch uitvoeren van data-analyses, waarbij een dataset wordt bevraagd op een veelheid aan bedrijfsregels, kan invloed hebben op de performance van het systeem. Indien daarbovenop sprake is van een migratieprogramma, waarbij brondata door middel van een cyclisch proces worden aangepast in overeenstemming met kwaliteitseisen en net zolang worden doorgevoerd totdat een gewenst kwaliteitsniveau is bereikt, dan is duidelijk dat het uitvoeren van datakwaliteitsanalyses een afzonderlijke omgeving vereist. Dit wordt wel een ‘staging area’ genoemd[In zekere zin kan de ‘staging’ area worden vergeleken met de in de IT meer bekende term ‘OTAP’, die staat voor de afgescheiden omgevingen die een nieuw te ontwikkelen systeem doormaakt totdat het ‘live’ gaat (namelijk Ontwikkeling, Test, Acceptatie en Productie).]. Dit kan het best worden omschreven als een afgezonderde omgeving waarin een kopie van de productiedata wordt opgeslagen om hier datakwaliteits- en transformatieactiviteiten op uit te voeren. In de staging area kunnen naar hartenlust data worden aangepast, relaties worden gelegd en analyses worden uitgevoerd. Er is specifieke software nodig om een audit trail te kunnen leggen waarbij alle uitgevoerde wijzigingen op de brondata worden vastgehouden.
De download zelf wordt veelal door de IT-afdeling uitgevoerd, die de vereiste bevoegdheden heeft om tabellen te benaderen en die beschikbaar te maken voor de data-analisten.
Verzamelen bedrijfsregels
De kern van de datakwaliteitsanalyse ligt in het identificeren, analyseren en definiëren van goede bedrijfsregels. Hoe beter de bedrijfsregels, hoe beter de kwaliteitsanalyse en hoe beter de inzichten in de daadwerkelijke kwaliteit van de bedrijfsdata die worden gebruikt voor het nemen van bedrijfsbeslissingen.
De vraag is hoe aan goede bedrijfsregels kan worden gekomen. Hiervoor is al opgemerkt dat vooral intensieve interactie tussen de data-analisten en de procesmedewerkers tot een goed inzicht in en verdieping van de bedrijfsregels kan leiden. Het samen kijken naar de uitkomsten van ‘profiling’ van de dataset en het analyseren van patronen en trends leidt tot het identificeren van bedrijfsregels. Zo kan het analyseren van de verschijningsvormen van het attribuut ‘payment term’ (waarvan de algemene bedrijfsregel is ‘binnen 30 dagen’) leiden tot het inzicht dat binnen het bedrijf in bepaalde gevallen ook andere payment terms worden gehanteerd. Het zoeken naar de oorzaken (‘root cause analysis’) kan dan leiden tot het identificeren van de scenario’s waarin het is toegestaan om wel tot een andere payment term te komen. Bijvoorbeeld: ‘payment term binnen 60 dagen toegestaan als de klant vorig jaar een omzet heeft opgeleverd van x of hoger’.
Intensief samenwerken met procesmedewerkers is niet altijd voldoende om alle bedrijfsregels op tafel te krijgen. Er is niet altijd voldoende kennis van en ervaring met het bedrijfsproces aanwezig. Door verloop van personeel kan veel kennis zijn verdwenen. Er zijn ook andere potentiële bronnen waar de data-analist gebruik van kan maken. Daarbij kan worden gedacht aan technische documentatie. Data rulebooks (‘data dictionairies’) en datamodellen kunnen hier de helpende hand bieden. Goede rulebooks bevatten een bron van informatie over de tabelstructuur, gebruikte attributen, aard van die attributen (tekst, numeriek, alfanumeriek, verplicht, vrij), relaties met andere tabellen en attributen, eigenaar, bedrijfsregels en dergelijke. Datamanagementprojecten hebben vaak ook mede ten doel dergelijke rulebooks te actualiseren, of, zoals in onze praktijk niet zelden het geval is, te realiseren.
Datamodellen beschrijven de structuur van data en dan vooral de relatie tussen de verschillende objecten en attributen. Net als met rulebooks zijn datamodellen ook niet altijd voorhanden, dan wel zijn ze verouderd. Er bestaan verschillende soorten van datamodellen. Het gaat voorbij de strekking van dit artikel om hierop uitgebreid in te gaan. In de literatuurlijst kunt u meer informatie vinden over dit onderwerp.
Structureren documentatie
Tijdens een omvangrijk datakwaliteitsonderzoek wordt niet alleen gebruikgemaakt van bestaande rulebooks en datamodellen, het onderzoek produceert ook veel documentatie, die op gestructureerde wijze moet worden opgeslagen. Denk hierbij aan analyserapporten, mapping-documentatie, versies van geactualiseerde rulebooks. Het is belangrijk bij de start van het datakwaliteitsonderzoek een repository te maken waarin dergelijke documentatie op gestructureerde wijze kan worden opgeslagen. Dat vergemakkelijkt het terugzoeken en onderbouwen van voorstellen.
Implementatiefase
In de implementatiefase staat het identificeren, ontwikkelen en implementeren van bedrijfsregels centraal. Hiervoor is al een aantal malen het begrip ‘data profiling’ gevallen. Profiling kan het best worden omschreven als een verzameling methoden en technieken gericht op het onderzoeken van datasets met als doel inzicht te krijgen in de structuren van die dataset en de afhankelijkheden binnen en tussen datasets.
Ten opzichte van documentatie laat ‘profiling’ ons daadwerkelijk zien hoe de data zijn gestructureerd. Documentatie kan zijn verouderd en ook de inzichten die architecten of procesgebruikers met ons delen kunnen aan erosie onderhevig zijn. Een profile geeft de actuele status weer en kan daarmee een belangrijke bron zijn om richting te geven aan het datakwaliteitsonderzoek en aan de identificatie van bedrijfsregels. In de literatuur ([Mayd07]) worden de in figuur 3 genoemde soorten van data profiling onderkend.

Figuur 3. Soorten van data profiling.
Bedrijfsregels
In [Mayd07] worden de volgende soorten van bedrijfsregels onderscheiden:
- beperkingen in de waarde van attributen;
- regels met betrekking tot relationele integriteit;
- regels voor historische data inclusief beperkingen in tijdswaarden;
- regels voor statuswaarden van objecten en attributen;
- algemene afhankelijkheidsregels.
Op de inhoud van deze bedrijfsregels wordt hierna kort ingegaan.
Regels voor de waarde van attributen
Afhankelijk van de betekenis van een attribuut kan worden gesteld dat er een limiet zit aan de waarde die aan het veld kan worden toegekend. Zo is het uitgesloten dat aan het veld ‘leeftijd’ een waarde wordt toegekend die hoger is dan een bepaalde waarde of lager is dan nul. Bedrijfsregels die zich op de waarde van attributen richten beogen een beperking aan te brengen in toegestane waarden. Daarmee wordt voorkomen dat onjuiste waarden worden ingevuld, hetgeen de kwaliteit van de betreffende dataset verhoogt. Door het definiëren van een veld als ‘verplicht’ kan bijvoorbeeld worden voorkomen dat er geen waarde wordt ingevuld.
Eerder in dit artikel is een voorbeeld gegeven van de uitkomsten van een ‘data profile’ van leveranciersgegevens. Geïdentificeerd is dat het veld ‘straatnummer’ in een aantal gevallen geen waarde heeft. Het record ‘leverancier’ heeft echter ook nog het veld ‘postbusnummer’. Het kan zijn dat indien geen straatnummer is ingevuld, dat dan van de leverancier wel een postbusnummer bekend is. Een bedrijfsregel kan dan zijn dat óf het straatnummer is ingevuld, óf het postbusnummer, maar dat het niet toegestaan is dat beide velden leeg zijn.
Regels met betrekking tot relationele integriteit
Deze bedrijfsregels zijn gebaseerd op het uitgangspunt dat entiteiten (zoals ‘leverancier’, ‘afnemer’, ‘product’) in een relationele database en de attributen van deze entiteiten een zekere relatie tot elkaar onderhouden. Het meest bekende voorbeeld van dit soort bedrijfsregels betreft de regels die het uniek zijn van een record proberen te borgen. De vraag is bijvoorbeeld hoe wij zouden kunnen borgen dat een leverancier maar één keer in een database voorkomt. In het logisch datamodel is voor de entiteit ‘leverancier’, het ‘leveranciersnummer’ de zogenaamde ‘primary key’. In databaseontwerptermen de ‘identifier’ waarmee de uniciteit van een entiteit wordt geborgd. Echter, de bedrijfsregel dat elk leveranciersnummer maar eenmaal in de dataset mag voorkomen garandeert op zich niet de uniciteit van de leverancier. Hiervoor is het nodig dat naar de combinatie van enkele attributen wordt gekeken. In dit geval zou dat de combinatie van ‘leveranciersnummer’, ‘naam’, ‘adres’ en ‘btw-nummer’ kunnen zijn. Verschillende leveranciersnummers, maar dezelfde naam, adres en btw-nummer duiden op een dubbele invoer. Het doorzoeken van een dataset op dubbele leveranciers waarbij naar de combinatie van deze attributen moet worden gekeken, vraagt de aanwezigheid van zeer flexibele data-analysesoftware waarin zogenaamde ‘fuzzy logic’ wordt toegepast. Hierbij wordt op basis van vooraf gedefinieerde logica op basis van waargenomen data aangegeven of bepaalde data mogelijk fouten bevatten. (Voorbeeld: J. Janssen, J Janssen en J. Jansen zijn mogelijk dezelfde persoon, zeker als zij nog één of meer gemeenschappelijke kenmerken hebben.)
Regels voor historische data
Veel datasets bevatten historische data. Denk bijvoorbeeld aan orderhistorie, overzicht van oude vestigingsadressen van leveranciers, functies die personeelsleden hebben bekleed met bijbehorende salarissen. Zij hebben veelal alleen waarde als zij zijn voorzien van een datum waarop het geregistreerde gegeven betrekking heeft. Ten aanzien van bepaalde persoonsgegevens geldt zelfs dat zij dienen te worden verwijderd, als zij hun nut voor de organisatie hebben verloren. De combinatie van de datum met de aard van het vastgelegde gegeven levert bedrijfsregels op. Zo zal in een database met actieve materialen de datum waarop de prijs is vastgelegd, recent moeten zijn.
Regels voor statuswaarden
Objecten in een bedrijf kunnen een transitie doormaken en daarbij een bepaalde status aannemen. Zo kan het object ‘verzekerde’ bij een levensverzekeringsmaatschapppij bijvoorbeeld de volgende statussen hebben: ‘aanvraag’, ‘offerte’, ‘offertebeoordeling’, ‘keuring’, ‘acceptatie’, ‘actief’, ‘beëindigd’. Het moge duidelijk zijn dat de aard van deze statussen en de voorwaarden waaronder een status kan veranderen informatie kan opleveren voor bedrijfsregels (bijvoorbeeld: een verzekerde kan maar één status hebben, voor acceptatie is het nodig dat er een keuring is uitgevoerd, etc.). Het geheel van de logische volgorde van statussen, het aantal statussen dat een object kan hebben in de tijd gezien en de relaties die statussen met elkaar onderhouden, kan zeer complex zijn. Het is veelal noodzakelijk om deze relaties in een model tot uitdrukking te brengen om de bedrijfsregels te bepalen.
Afhankelijkheidsregels
Afhankelijkheden tussen attributen komen voor in bedrijfsregels voor historische data en bedrijfsregels voor statuswaarden, zoals hiervoor kort beschreven. Maar deze twee vormen van bedrijfsregels dekken daarmee niet alle mogelijke afhankelijkheden tussen attributen af. In aanvulling daarop zijn er ook nog andere afhankelijkheden tussen attributen, die relevant zijn voor de kwaliteit van een dataset die wij onderzoeken. Een vorm van een dergelijke bedrijfsregel doet zich bijvoorbeeld voor indien eenzelfde attribuut in verschillende databases voorkomt. Bijvoorbeeld het adres van een afnemer komt zowel voor in het CRM-systeem als in het factureringssysteem. De waarden van het attribuut ‘adres’ zouden wel hetzelfde moeten zijn. Deze afhankelijkheid kan dan worden omgezet in een bedrijfsregel.
Verfijningsfase
Het is niet makkelijk om goede en toereikende bedrijfsregels te ontwerpen. Het toepassen van ‘better practice’-regels is niet zonder risico. Ze zijn niet specifiek toegeschreven op de bedrijfsomgeving waarop het assessment wordt uitgevoerd. Alhoewel zij toepasbaar kunnen zijn op een groot aantal omgevingen, kunnen zij bij een enkele omgeving juist tot een verkeerde uitkomst leiden. Verkeerd in dit verband betekent dat zij ten onrechte tot het identificeren van ‘foutieve’ data leiden, dan wel dat zij foutieve data niet identificeren. Bijvoorbeeld betalingen zijn aangemerkt als dubbel wanneer de bankrekening van de ontvangende partij, de referentie naar een order of contract en het bedrag hetzelfde zijn. Echter, reguliere betalingen voor een abonnement kunnen hierdoor ook onterecht als dubbel worden geclassificeerd. Er dient dus goed rekening te worden gehouden met de specifieke bedrijfsregels.
De verfijningsfase is erop gericht initiële resultaten door te nemen met procesprofessionals om daarmee de toegepaste regels te verfijnen. Data-analisten ontberen veelal de specifieke proceskennis om profiling- en andere analyse-uitkomsten goed te kunnen interpreteren. Procesprofessionals zijn bij de dagelijkse uitvoering van het proces betrokken. Zij zijn betrokken bij het tot stand komen van bedrijfstransacties die in het systeem worden vastgelegd, evenals bij het aanmaken en wijzigen van masterdata. Vaak zijn zij ook betrokken bij procesoptimalisaties, waarbij op het snijvlak van proces en systeem wordt gezocht naar mogelijkheden om het proces sneller en beter te laten lopen. Al deze activiteiten maken dat de procesprofessional een diepgaand inzicht heeft in de wijze waarop het proces is opgezet en uitgevoerd. Hij of zij is bij uitstek geëquipeerd om de uitkomsten van de analyses te interpreteren, te valideren en de bedrijfsregels verder aan te scherpen.
Rapportagefase
Aan het eind van de verfijningsfase resteert een optimale set van bedrijfsregels die op de objecten binnen de scope van het onderzoek kunnen worden toegepast. Bij toepassing geeft dit een optimaal beeld van de kwaliteit van onderzochte data, met duidelijke identificatie van de ‘fouten’ die zich hierin bevinden. Er zijn nu verschillende mogelijkheden:
- De bedrijfsleiding besluit de scope van het datakwaliteitsonderzoek uit te breiden met relevante en kritieke objecten die in eerste aanleg buiten de scope waren gebleven. Vervolgens wordt besloten de geconstateerde tekortkomingen in de dataset te repareren.
- De uitkomsten maken onderdeel uit van een bedrijfsbreed onderzoek naar de kwaliteit van datamanagement. De tekortkomingen roepen de vraag op hoe deze zijn ontstaan. Het brede onderzoek kan hier informatie over geven en bijvoorbeeld identificeren dat de governanceprocessen voor verbetering vatbaar zijn, dat de onderhoudsprocessen voor masterdata en daarin opgenomen beheersingsmaatregelen moeten worden verbeterd en dat technische documentatie ontbreekt. In die zin kan het datakwaliteitsonderzoek en de aanvullende bevinding uit het bedrijfsbrede onderzoek aanleiding zijn om een bedrijfsbreed masterdatamanagementprogramma te starten.
- Indien de datakwaliteitsanalyse deel uitmaakt van een systeemimplementatie zullen de uitkomsten worden gebruikt om de legacy-data op te schonen alvorens zij naar de doelomgeving worden gemigreerd.
Conclusie
Veel organisaties zijn zich niet bewust van het belang van datakwaliteit voor het uitvoeren van bedrijfsprocessen en voor het verschaffen van managementinformatie over de uitkomsten van die bedrijfsvoering. In dit artikel heb ik een inleiding verzorgd op het thema ‘datakwaliteit’ en het uitvoeren van het datakwaliteitsonderzoek. Aangezien bedrijfsdata de basis vormen voor het nemen van besluiten is het voor de effectiviteit daarvan belangrijk dat de kwaliteit van die data goed is. Het definiëren en toepassen van de juiste datakwaliteitsregels neemt een centrale plaats in bij het datakwaliteitsonderzoek. De komende jaren zullen een toename laten zien van data-analisten, data-analysesoftware en bedrijven en organisaties die op structurele wijze invulling gaan geven aan datakwaliteitsbeheer.
Literatuur
[Huan99] Huang, Lee and Yang, Quality Information and Knowledge, Prentice Hall, 1999.
[Jonk11] R.A. Jonker et al., Effective Master Data Management, Compact, 2011/0.
[LeBl08] Andrew LeBlanc, Enterprise Data Management with SAP Netweaver MDM, Galileo Press / SAP press, 2008.
[Mayd07] Arkady Maydanchik, Data quality assessment, Technics Publications LLC, 2007.