




De wereld wordt overspoeld met gegevens; internetgebruikers laten met iedere muisklik of ‘tweet’ een klein beetje meer van zichzelf zien; GPS-ontvangers en andere sensoren worden aan steeds meer apparaten en producten toegevoegd om geautomatiseerd gegevens te verzamelen; en transacties worden op een steeds gedetailleerder niveau vastgelegd. Deze ontwikkeling biedt organisaties ongekende mogelijkheden om waardevolle informatie over klant, markt en product te benutten. Maximale waarde uit deze gegevens wordt echter pas behaald als organisaties in zowel technische als organisatorische zin in staat zijn zettabytes en petabytes aan data daadwerkelijk in te zetten voor het behalen van de strategische voordelen.
Inleiding
In het boek The Hitchhiker’s Guide to the Galaxy (1979), wordt een supercomputer het antwoord gevraagd op ‘The Ultimate Question of Life, the Universe, and Everything’, het even belangwekkende als relevante antwoord na 7½ miljoen jaar rekenen: 42.
Hoewel toentertijd fictie, lijkt een dergelijke supercomputer nu toch wel erg dichtbij te komen. Begin 2011 deed een supercomputer van IBM genaamd Watson mee aan een speciaal opgezette versie van de Amerikaanse tv-quiz Jeopardy! met als tegenstanders twee voormalige Jeopardy!-recordhouders. De vragen werden in tekstvorm aangeboden en konden elk denkbaar onderwerp omvatten. Bijvoorbeeld werd er gevraagd: ‘Harriet Boyd Hawes was the first woman to discover & excavate a Minoan settlement on this island’. Watson wist met behulp van 2.880 processorkernen, 500 GB ongestructureerde data waaronder de Engelse versie van Wikipedia en 3.000 voorspellende modellen sneller dan zijn tegenstanders de vraag te interpreteren en het goede antwoord op te snorren: Kreta! Op deze wijze werd een groot aantal vragen door Watson sneller opgelost dan door zijn menselijke opponenten ([IBM]).
In de praktijk wordt deze supercomputer nu aangedragen voor een aantal relevante toepassingen. Zoals het scannen van vakliteratuur ten behoeve van medische specialisten. Door slimmer gebruik te maken van alle beschikbare data, verwachten ook veel organisaties een competitief voordeel te behalen ten opzichte van concurrenten: zij verwachten hierdoor beter en sneller geïnformeerd te worden over klanten, marktontwikkelingen en interne processen en kunnen daardoor sneller en beter (strategische) beslissingen nemen.
Deze verwachting wordt door twee trends versterkt. Ten eerste zal de hoeveelheid en diversiteit aan beschikbare en te analyseren gegevens voor organisaties exponentieel toenemen. Ten tweede wordt de informatie die uit deze data te winnen is dermate belangrijk, dat organisaties zelfs hun bestaansrecht kunnen verliezen op het moment dat deze data niet ten volle benut wordt. De paraplunaam voor de technieken om met deze grote hoeveelheden en diversiteit aan data om te kunnen omgaan, is Big Data.
Wat is Big Data?
De term Big Data wordt gebruikt om data op extreme schaal aan te duiden en de daarbij behorende technieken. Het concept Big Data is niet hetzelfde als ‘heel veel data’. Big Data heeft betrekking op grote hoeveelheden data die intensief gebruikt worden waarbij de traditionele methoden om deze data te managen problemen opleveren. Traditionele relationele databaseconcepten zijn niet ontworpen om ongestructureerde gegevens te beheren en te analyseren en kunnen ook slecht omgaan met omgevingen waarin data gedistribueerd is opgeslagen. Om het onderscheid tussen data en Big Data te kunnen maken, zijn er drie dimensies die gebruikt kunnen worden om de schaal van data te meten:
- snelheid (velocity): snelheid van in- en uitstroom van data in een dataset, zowel in lees- als in schrijfbewerkingen;
- volume: hoeveelheid beschikbare data op een gegeven moment;
- variëteit (variety): mate van verschil in dataformaat (nummers, tekst, afbeeldingen, video, audio).
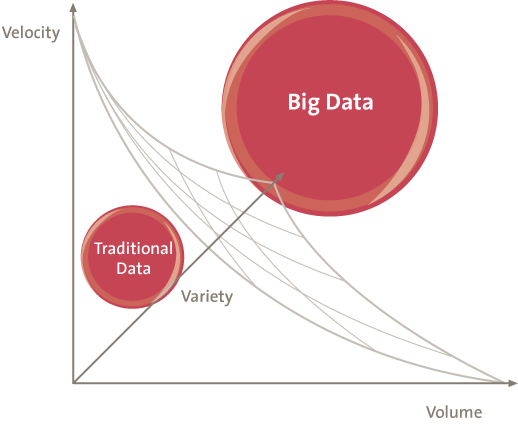
Figuur 1. De schaal van data.
Voorbeelden van dergelijke data op grote schaal zijn ongestructureerde weblogs, beveiligingscamera’s, video’s op YouTube, metadata met betrekking tot het gebruik van internet, koop- en zoekgedrag van klanten in een (internet) winkel en combinaties van deze bronnen. Het is gebruikelijk om een stijging van de omvang van de data of het aantal opvragingen te compenseren door de capaciteit uit te breiden door bijvoorbeeld nieuwe harde schijven of extra servers toe te voegen. Echter, het marginale nut van extra hardware bij dergelijke situaties kan zeer beperkt zijn. Dit geldt als data vaak verandert of bij vrijwel continue stromen van informatie zoals meetwaarden van sensoren, twitterberichten of beveiligingscamera’s en bij toepassingen met een groot aantal gebruikers tegelijkertijd (websites maar ook bedrijfsapplicaties kunnen duizenden simultane gebruikers hebben). In dergelijke situaties valt meer te winnen met een efficiëntere aansturing en coördinatie door (database)software dan met investeringen in hardware en bandbreedte.
Technieken en methoden
Het CAP-theorema van Brewer ([Brew00]) geeft aan dat een gedistribueerde database (verdeeld over meerdere servers) per definitie slechts aan twee van de drie criteria kan voldoen (zie figuur 2).
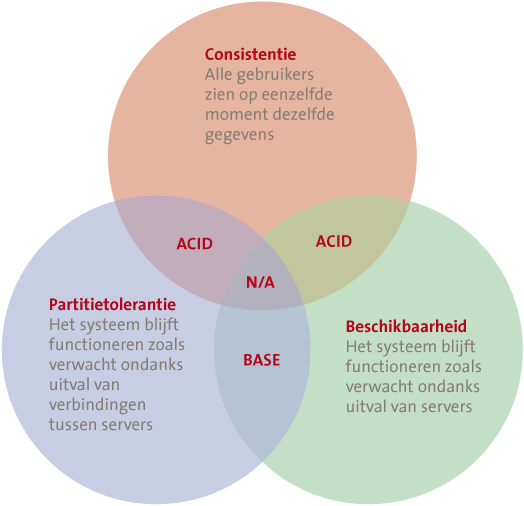
Figuur 2. CAP-theorema.
Het is momenteel zo dat het meest gebruikte type database de relationele database is. Dit type database scoort goed op consistentie en beschikbaarheid. Een relationele database bestaat uit tabellen waarbij elke tabel informatie bevat over een bepaald onderwerp zoals Klanten of Bestellingen. De volledige adresgegevens van een klant worden normaliter niet bij elke bestelling opnieuw vastgelegd. In plaats daarvan wordt naast het product, het aantal en de gewenste leverdatum van het product een extra kolom aan de tabel Bestellingen toegevoegd. In die extra kolom staat een indexnummer dat verwijst naar een bepaalde regel in de tabel Klanten met daarin gegevens over de klant zoals het adres.
Om te waarborgen dat geen onduidelijkheden of tegenstrijdigheden in de database ontstaan worden veranderingen (aanvullingen, verwijderingen of aanpassingen) verwerkt volgens de vier basisprincipes van relationele databases: Atomacy, Consistency, Isolation en Durability (ACID). Deze principes houden het volgende in:
- Atomacy. Een bewerking wordt volledig doorgevoerd of helemaal niet.
- Consistency. Verwijzingen in de database moeten kloppen. Als een bestelling naar een klant verwijst dan kan de klant pas verwijderd worden als eerst de bestellingen zijn verwijderd.
- Isolation. De transacties worden los van elkaar uitgevoerd, zodat gebruikers elkaar niet beïnvloeden. Als een overzicht van alle klanten in Amsterdam en van alle klanten in Utrecht wordt gevraagd mag het niet zo zijn dat gelijktijdig een andere gebruiker voor een klant de plaats Utrecht in Amsterdam verandert waardoor één klant in beide lijstjes voorkomt. Die andere gebruiker is of eerder (klant komt in lijstje Amsterdam) of later (klant komt in lijstje Utrecht).
- Durability. Transacties zullen na voltooiing niet meer verdwijnen, ook niet bij een systeemcrash of stroomuitval.
Door alleen transacties te accepteren die voldoen aan deze eigenschappen wordt gezorgd dat de database als geheel consistent is en om kan gaan met tijdelijke communicatiestoringen tussen onderdelen (harddisks, servers) van de database. In traditionele databases met grote hoeveelheden data en intensief gebruik worden de werklast en de opslag veelal verdeeld over meerdere fysieke schijven of servers. Dit vergt extra stappen om de ACID-eigenschappen voor transacties af te dwingen. Records dienen veelvuldig tijdelijk gelocked te worden voorafgaand aan een bewerking, hierdoor moeten andere processen wachten en daalt de performance.
Het alternatief voor ACID zijn de BASE-principes (Basically available, Soft-State en Eventually consistent). Kern is dat de verschillende decentrale onderdelen van de database transacties laten plaatsvinden en pas later dit onderling synchroniseren. Databases gebaseerd op de BASE-principes scoren op de aspecten Beschikbaarheid en Partitie Tolerantie. Hierdoor bestaat een kans op conflicten. Er kunnen verschillende mechanismen toegepast worden om hier in de praktijk mee om te gaan en de impact te verminderen, maar het probleem kan niet geheel weggenomen worden. Aangezien echter de mogelijkheden om een informatievraag (query) te kunnen opdelen bij Big Data van groot belang zijn, zal BASE in die situaties veelal prevaleren boven ACID. Rekencapaciteit en opslag kunnen beter opgedeeld worden waardoor de toegevoegde waarde van additionele hardware groter is. Een vergelijking van deze beide concepten is te vinden in figuur 3.
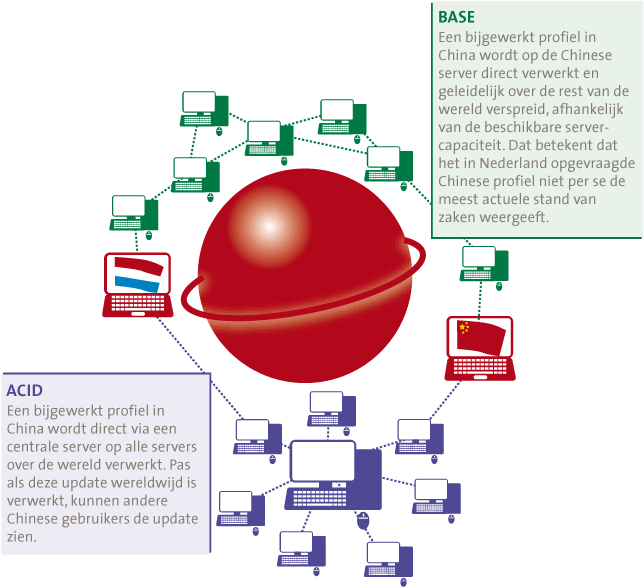
Figuur 3. BASE tegenover ACID in een profielenwebsite.
Alternatieven voor de relationele database: NoSQL
Ter vervanging van het relationele (SQL) databasemodel met volledige handhaving van de ACID-principes worden verschillende alternatieven toegepast. De meeste van deze systemen zijn ontsproten aan één van de grote webdiensten. De systemen zijn veelal in reactie op performanceproblemen ontwikkeld met de aard van de gegevens die ze verwerken als uitgangspunt. In plaats van een relationeel databasemodel gebruiken ze andere technieken.
Hieronder gaan we kort in op databases op basis van een key-value store en op basis van het BigTables-concept. Andere alternatieve methoden zijn databases op basis van graventheorie (geschikt voor analyse van sociale netwerken en voor transportnetwerken) en document stores voor opslag van documenten.
Een key-value store kent een top-downstructurering van gegevens die aan XML doet denken (zie figuur 4 voor een voorbeeld). Voor een database met genealogische gegevens kan dat handig zijn want de voorvaderen en de nazaten inclusief relevante gegevens zoals huwelijken en geboortedata staan dicht bij elkaar.
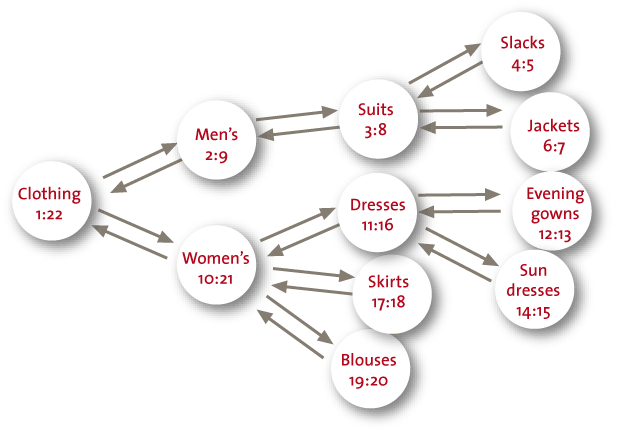
Figuur 4. Voorbeeld key value store.
Hbase is een implementatie van het Google BigTable-systeem. Tabellen zijn multidimensionaal terwijl een relationele database slechts twee dimensies kent (rijen en kolommen). Big Tables worden fysiek opgeknipt in delen van ca. 200MB. Die delen zelf kunnen verspreid worden over een nagenoeg oneindig aantal harddisks en servers. Speciale META1-indexen geven aan waar deze delen gevonden kunnen worden. Centraal voor alle gebruikers is alleen de META0-index die de locaties van de verschillende META1-indexen bevat. Aangezien de aard van de dataverzoeken aan META0 zeer kort en simpel is (‘Waar staat de meta1-index voor tabel Klant?’), zal de snelheid van de META0 niet snel de bottleneck vormen. Voor de rest is het gehele model volledig schaalbaar als de database op één van de drie genoemde aspecten Velocity, Volume of Variety toeneemt. De Google BigTable is onder andere voor YouTube gebruikt ([Cuon07]). Een verschil met Cassandra is dat de analysemethoden meer lijken op de SQL van relationele databases.
Big Data analytics
Naast het beheren van Big Data wordt er pas echte waarde toegevoegd nadat door middel van analyses de informatie uit de beschikbare data gehaald is. Er zijn twee redenen te identificeren waarom analyse op Big Data afwijkt van analyse op traditionele (relationele) data. De eerste heeft te maken met de extreme schalen waarin Big Data zich bevindt, denk terug aan de eerdergenoemde 3 V’s. Zo is de data over het algemeen gedistribueerd en vaak ook gedupliceerd opgeslagen en zal er geen of minder gebruik worden gemaakt van relationele databases. Deze verschillen in aard en opslag van Big Data ten opzichte van traditionele data leiden ertoe dat er nieuwe technieken nodig zijn om op een zinvolle manier informatie uit de beschikbare gegevens te extraheren.
Hiernaast ziet ook de voorbereiding voor het uitvoeren van analyses er anders uit dan bij traditionele business intelligence (BI). Waar bij traditionele BI de nadruk zal liggen op het modelleren van de data conform een vooraf gedefinieerd datamodel, zal bij Big Data analytics de nadruk veel meer liggen op statistische modelvalidatie ten behoeve van de analyse zelf. Hierdoor zal het initieel opzetten van een nieuwe analyse relatief veel tijd kosten terwijl een herhaling van dezelfde analyse op nieuwe data sneller zal verlopen. Dit zal een andere aanpak in de gehanteerde data-analysemethodologie vereisen. Naast dat er nieuwe methoden nodig zijn voor het gehele data-analyseproces (van dataselectie en acquisitie tot het testen van hypothesen en rapporteren hierover), zullen we ons hier richten op technieken die gebruikt kunnen worden om analyses op beschikbare data uit te voeren en niet zozeer op de overige processen in een data-analysetraject ([McKi11]). Naast de hier genoemde technieken bestaan er nog vele andere mogelijkheden, het gaat te ver deze allemaal te beschrijven.
Natuurlijke taalverwerking
Natuurlijke taalverwerking, of in het Engels Natural Language Processing (NLP), is een verzamelbegrip voor technieken die gebruikt worden om (menselijk) taalgebruik te doorgronden. Deze techniek is erg geschikt om analyses uit te voeren op de enorme hoeveelheden aan ongestructureerde, geschreven informatie zoals e-mailverkeer, wetenschappelijke artikelen of internetblogs. Gebaseerd op een vooraf gedefinieerde vraag over een stuk tekst, kan met behulp van deze technieken een antwoord verkregen worden. Denk hierbij bijvoorbeeld aan een sentimentanalyse op Twitter. Wanneer de naam van een bedrijf of product in een tweet genoemd wordt, kan op basis van de omliggende woorden vastgesteld worden of het een positieve of negatieve reactie betreft en zelfs de heftigheid hiervan. Een ander veld waarin deze techniek aan populariteit begint te winnen is het scannen van e-mails van personeelsleden om potentiële fraudepatronen of andere integriteitsschendingen te identificeren. Eén van de aspecten bij een bedrijfsfraude is het motief. Het scannen van e-mails op zinnen zoals ‘halen verkooptarget’ of ‘bonus’ kan indicaties opleveren voor fraudegevallen.
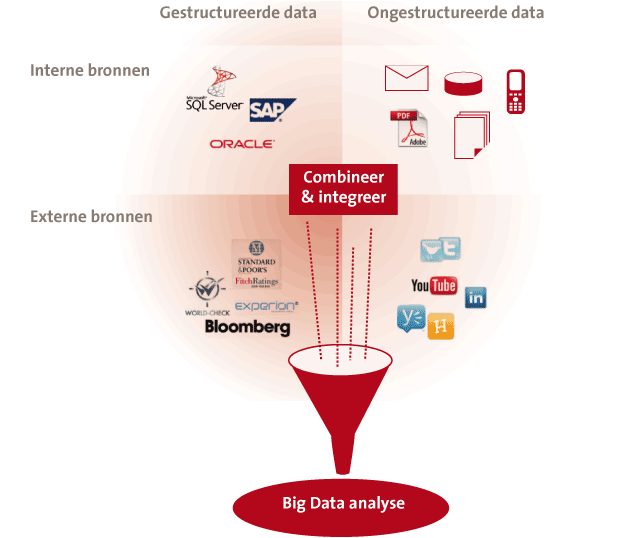
Figuur 5. Big Data analyse.
Netwerkanalyses
Een ander type analyses zijn de netwerk- of clusteranalyses. Netwerkanalyses richten zich bijvoorbeeld op sociale netwerken en omvatten technieken die gebruikt worden om relaties en karakteristieken van de relaties tussen knooppunten in een netwerk in kaart te brengen. Denk hierbij aan informatiestromen door een sociaal netwerk in de vorm van tweets of berichten van een gebruiker aan een andere gebruiker. Wanneer door middel van dit type analyses netwerken in kaart worden gebracht, is het mogelijk om te bepalen welke personen in een netwerk het meest invloedrijk zijn, of hoe een bepaald sentiment jegens een product zich ontwikkelt. Voor marketingdoeleinden is dit zeer waardevolle kennis.
Een andere vorm van netwerkanalyse betreft de neurale netwerkanalyse. Hierbij worden op biologische neurale netwerken, zoals het menselijk brein, gebaseerde algoritmes ontwikkeld en toegepast op data. Doel hiervan is om niet-lineaire patronen in data te ontdekken, zoals identificatie van ontevreden high-value klanten of frauduleuze verzekeringsclaims.
Buiten de digitale wereld kan gedacht worden aan de camera’s die de voetgangersstromen op Koninginnedag door de nauwe straten van Amsterdam vastleggen. De omvang van die stromen hangt af van het gedrag van bijna één miljoen individuen. Net zoals bij het surf- en koopgedrag volgt elke gebruiker een ander pad, toch verbergt deze data patronen en onderlinge afhankelijkheden. Op basis van deze patronen kunnen maatregelen genomen worden om deze mensenmassa te sturen.
Voorspellende analyses
Deze techniek is gebaseerd op statistische berekeningen waarbij het doel is om de waarschijnlijkheid van een bepaalde uitkomst te berekenen gegeven één of meer inputvariabelen. Dit soort technieken kan toegepast worden om toekomstig gedrag van klanten te voorspellen gegeven een wijziging in bijvoorbeeld de winkelinrichting. Een hierin veelgebruikte techniek is de regressieanalyse. Hierbij wordt een statistisch model ontwikkeld om de waarde van een afhankelijke variabele te voorspellen op basis van één of meer onafhankelijke variabelen. Een andere techniek, ontsprongen uit het veld van kunstmatige intelligentie, is ‘Association Rule Learning’ ([Fu00]). Het doel van deze techniek is vast te stellen welke combinatie van factoren het meest waarschijnlijk leidt tot een bepaald resultaat. Denk bijvoorbeeld aan een analyse op verkopen in een supermarkt. In het verleden is op basis van deze techniek gebleken dat de kans erg groot is dat mensen die luiers kopen hiernaast ook bier zullen kopen.
Visualisatie van resultaten
Om de hoeveelheden data op een praktische manier weer te geven, is goede visualisatie van de analyseresultaten van groot belang. Waar bij traditionele data-analyse in veel gevallen volstaan kan worden met tabellen of eenvoudige tweedimensionale grafieken, zijn er voor de presentatie van analyseresultaten van Big Data analyses nieuwe technieken ontwikkeld. In het algemeen kan gesteld worden dat het doel van Big Data analytics is inzicht te verschaffen in meerdere dimensies of correlaties binnen een dataset en dat deze tevens veelal een voorspellend karakter in de vorm van kansverdelingen omvatten. Hoewel Big Data analytics-output dezelfde vorm kan aannemen als traditionele BI-output, zal het onderscheidend vermogen van Big Data het beste naar voren komen wanneer gebruik wordt gemaakt van sterk gevisualiseerde presentaties. Mede doordat eindgebruikers van de resultaten van Big Data waarschijnlijk nog verder van de gegevens afstaan en hierdoor minder gevoel met de beschikbare onderliggende gegevens ontwikkeld zullen hebben. Om dit mogelijk te maken, zijn technieken ontwikkeld zoals Tag Clouds, Heat-Maps, History Flows (gebruikt om bijvoorbeeld de bijdrage van auteurs in artikelen te volgen) en Spatial Information Flows (resultaten van een analyse worden op een kaart geprojecteerd om bijvoorbeeld goederenstromen inzichtelijk te maken). De oude stelregel dat een plaatje meer zegt dan duizend woorden (of in dit geval 1000 petabytes) gaat voor Big Data zeker op.
Toepassingen van Big Data
De ‘Obama 2012’-campagne
Voor de Amerikaanse presidentsverkiezingen van 2012 heeft Barack Obama een team van wetenschappers om zich heen verzameld dat werkt aan het tot de verbeelding sprekende ‘Project Dreamcatcher’. Doel van dit project is het vaststellen wat (potentiële) kiezers bezighoudt. De ‘dromen’ van kiezers worden letterlijk gevangen door gebruik te maken van persoonlijke verhalen van kiezers of via social media zoals Facebook of Twitter. De exacte methoden waarmee deze gegevens vertaald worden in stemgedrag van kiezers blijven in de beslotenheid van het campagneteam. Gedacht moet echter worden aan het distilleren van persoonlijke opvattingen met betrekking tot bepaalde ‘hot topics’ en het koppelen van deze gegevens met overige persoonlijke informatie zoals NAW-gegevens, hobby’s en interesses of zelfs informatie zoals inkomensgroepen of krantenabonnementen. De bronnen van al deze gegevens kunnen bestaan uit commercieel beschikbare consumentengegevens, Facebookprofieldetails, ingevulde webformulieren of opgenomen (telefoon)gesprekken met kiezers. Een koppeling tussen al deze beschikbare informatie zal het campagneteam helpen te voorspellen waar een kiezer gevoelig voor is en wat het meest waarschijnlijke stemresultaat zal zijn. Hiernaast kan uitermate precies bepaald worden in welke vorm een boodschap aangeboden moet worden om het meest effectief te zijn, alleen al door het volgen van het klikgedrag van websitebezoekers.
Financiële instellingen
Terwijl toezichthouders op steeds gedetailleerder niveau inzicht eisen in transacties, posities en risico’s van financiële instellingen, bestaat ook bij financiële instellingen zelf een steeds grotere behoefte aan informatie over processen, klanten en transacties om voorspellingen te kunnen doen over toekomstig gedrag van klanten, optimale prijsstrategieën, fraudepatronen, mogelijkheden tot procesoptimalisatie en risico-ontwikkelingen.
Op basis van een Big Data benadering van de beschikbare gegevens kan er een wereld aan mogelijkheden opengaan. Denk bijvoorbeeld aan verbeteren van de voor financiële instellingen verplichte ken-uw-klantprocessen door analyses uit te voeren op ongestructureerde social-mediagegevens en deze te relateren aan intern beschikbare demografische en historische gegevens over bestaande klanten. Hiernaast kunnen nauwkeurige voorspellingen over bijvoorbeeld kredietwaardigheid, kredietrisico’s (Basel III) en voorzieningen (Solvency II) op klantniveau gedaan worden. Door een combinatie van gegevens uit diverse systemen, zowel intern als extern, kan op basis van historisch gedrag van vergelijkbare klanten en real-time transacties diepgaand inzicht verkregen worden in ontwikkelingen in kwantitatieve risico’s en commerciële aantrekkelijkheid van klantgroepen of producten. Ten slotte, door financiële transacties die door de instelling afgehandeld worden continu te monitoren en te vergelijken met relevante data uit diverse andere bronnen, kunnen patronen die wijzen op fraude, witwassen, een naderend faillissement of financiering van terrorisme zichtbaar worden gemaakt nog voordat de transactie afgehandeld is.
Implementatie-issues
Bovengenoemde technieken zijn niet per se een vervanging van huidige systemen en analyseprocessen, maar kunnen veelal aanvullend worden toegepast. Elementen van deze technieken zijn ook in traditionele BI-oplossingen terug te vinden. Daar waar organisaties daadwerkelijk oplopen tegen de grenzen en beperkingen van de verwerkingsmogelijkheden, kan de toevoeging van Big Data concepten deuren openen die anders gesloten blijven. Dit impliceert dus dat Big Data en traditionele BI naast elkaar in één organisatie kunnen bestaan. Denk bijvoorbeeld maar aan een organisatie zoals Facebook waarbij de profielen door middel van een Big Data oplossing ontsloten worden terwijl de financiële administratie hier waarschijnlijk nog op een traditioneel relationeel DBMS zal draaien.
Om een dergelijke incorporatie van Big Data mogelijk te maken is er een aantal organisatorische randvoorwaarden waarmee rekening gehouden dient te worden. Een eerste vraag die zich in dit kader opwerpt is de plaats waar Big Data analytics plaats dient te vinden: binnen een organisatie of erbuiten (outsourcing) of een hybride vorm daartussen. Een hieraan relaterende vraag betreft het eigenaarschap van Big Data. Dient er binnen de organisatie een aparte BI-afdeling verantwoordelijk gesteld te worden voor Big Data analytics of dient per afdeling zelf een BI-functie ingeregeld te worden om Big Data vraagstukken op te pakken?
De nieuwigheid van de concepten, de benodigde geavanceerde technische kennis, gebrek aan talent, de enorme hoeveelheid hardware en de diversiteit van databronnen binnen de organisatie lijken een centraal gestuurde BI-afdeling te rechtvaardigen. Sterker, deze issues lijken haast voldoende reden om de technische implementatie van Big Data analytics volledig te outsourcen naar een hierin gespecialiseerde partij. Echter, Big Data analytics betreft typisch sterk vraag- of businessgedreven vraagstukken, een hechte integratie tussen de technische implementatie en de vragende afdeling is hierdoor tevens vereist. Het is derhalve noodzakelijk voor Big Data analytics een duidelijke afweging te maken over de plek binnen de organisatie. Het integreren van Big Data oplossingen met huidige reeds bestaande BI-afdelingen zou, gezien bovenstaande overwegingen, zomaar eens niet de meest optimale oplossing kunnen zijn.
Een tweede vraagstuk betreft de opslag van Big Data. Een nieuw en kostbaar serverpark aanleggen om Big Data op te slaan en te ontsluiten behoort natuurlijk tot de mogelijkheden. Echter, ook hier geldt dat de baten hiervan mogelijkerwijs niet tegen de hiermee gemoeide investering in tijd en energie opwegen. Bijkomend geldt ook nog dat dit nieuwe serverpark voor een groot deel van de tijd slechts deels in gebruik zal zijn, en op het moment dat gebruik wel optimaal is tekent zich direct weer een capaciteitsprobleem af. Als mogelijke oplossing kunnen twee recente trends die de afgelopen jaren al aan populariteit hebben gewonnen, met inachtneming van de bijbehorende risico’s, wellicht soelaas bieden: datavirtualisatie en opslag van gegevens in de cloud.
Naast de organisatorische brengt Big Data ook een aantal juridische c.q. ethische vraagstukken met zich mee waaronder bescherming van de privacy. Gegevensverzamelingen kunnen informatie verschaffen over een heel ander onderwerp dan waarvoor zij oorspronkelijk zijn vastgelegd (gegevens over belgedrag worden om administratieve redenen vastgelegd maar zijn ook goed bruikbaar voor marketing of de opsporing van misdrijven). Registraties die ooit te groot en te complex waren om naar personen herleidbare informatie terug te geven, kunnen met behulp van Big Data technieken alsnog dusdanig geanalyseerd worden dat zij herleidbare informatie teruggeven. Door tekstvergelijking met andere teksten op internet kan wellicht de auteur van een anonieme brief (of getuigenverklaring) achterhaald worden. Big Data wordt daarnaast veel gebruikt voor het koppelen van verschillende gegevensbronnen. Door het combineren van datasets kan alsnog naar een persoon herleidbare informatie ontstaan (uitgebreide profielen op basis van surfgedrag op internet). Ten slotte wordt de wijze waarop informatie over internetgebruikers achterhaald wordt steeds moeilijker te doorgronden voor deze gebruiker. Als er op een Facebookprofiel een instelling verkeerd staat kan het zomaar zijn dat het profiel met iedereen die hier behoefte aan heeft gedeeld wordt, zonder dat de gebruiker hier weet van heeft.
De huidige maatregelen voor privacybescherming zoals bijvoorbeeld de Wet op de bescherming van de persoonsgegevens blijven uiteraard van kracht. De toepassing en handhaving van deze wet en andere internationale wetgeving kan door de combinatie van gegevensbestanden problematisch worden. De veelheid aan beschikbare data maakt het voor toezichthouders lastig om te bepalen of een combinatie van databronnen een mogelijke inbreuk op de privacy vormt terwijl de losse registratie zelf binnen de richtlijnen blijft. Hierbij vormen de capaciteitsbeperkingen bij toezichthouders zoals CBP een extra bottleneck. Dit zorgt ervoor dat een steeds groter deel van de verantwoordelijkheid voor de verwerking en bescherming van gegevens bij de organisaties zelf komt te liggen en buiten beeld van gebruiker en toezichthouder blijft. Ook de variaties in cultuur over de hele wereld met betrekking tot wat privacygevoelige gegevens zijn, maken dit tot een ingewikkeld onderwerp.
Doemdenkers stellen dat door Big Data het einde van de privacy als concept in zicht is. De verantwoordelijkheid zal inderdaad een geheel nieuwe set aan richtlijnen en vereisten voor organisaties met zich meebrengen om ervoor te zorgen dat privacy gewaarborgd blijft. Toezichthouders dienen hier vooruitstrevend doch prudent actie op te ondernemen, echter het einde van de privacy als tijdperk is hiermee volgens ons nog niet aangebroken.
Conclusie
De vooruitzichten van Big Data zijn veelbelovend, maar een integrale methodiek om optimaal gebruik te maken van de door Big Data geboden mogelijkheden bevindt zich nog in een ontwikkelingsfase. Per organisatie en vooral per vraagstuk dient een passende oplossing ontwikkeld te worden waarbij de behoefte van de organisatie leidend is. Dit maakt de inzet wenselijk van experts met kennis van het gehele transformatieproces: van data naar informatie naar domeinkennis tot aan wijsheid (= beslissingen).
De tijd is gekomen voor alle organisaties om na te denken over de strategische inzet van (Big) Data. Daarin onderscheiden we twee varianten. Ten eerste is er de radicale variant, een volledig ‘data driven’ organisatie, die met name geschikt is voor start-ups of bij strategische heroriëntaties. Big Data wordt in dat geval de centrale component in de bedrijfsvoering. De tweede variant is de geleidelijkere variant, waarbij Big Data-concepten een noodzakelijke aanvulling zijn op reeds bestaande BI-infrastructuur en invulling geven aan de strategische behoefte aan informatie.
Voor de meeste bestaande bedrijven zal de geleidelijke variant geschikt zijn. Uit de huidige omgeving kunnen de relevante gegevens worden geëxtraheerd en gecombineerd met andere tot nu toe ontoegankelijke bronnen. De Big Data-oplossingen worden geleidelijk geïntegreerd met de rest van de systemen. Dit biedt organisaties de mogelijkheid door middel van een geleidelijke uitbouw steeds meer strategische voordelen te behalen. Let wel, bij voorkeur net een stapje eerder dan de concurrent en met inachtneming van alle risico’s en uitdagingen.
Literatuur
[Brew00] E. Brewer, tijdens ACM Symposium on Principles of Distributed Computing, 2000. Theoretisch uitgewerkt door Lynch en Gilbert in Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services, ACM SIGACT News, Volume 33 Issue 2, 2002, p. 51-59.
[Cuong07] C. Do Cuong, Google Techtalk 23 juni 2007, http://video.google.com/videoplay?docid=-6304964351441328559#.
[Fu00] X. Fu, J. Budzik and K.J. Hammond, Mining navigation history for recommendation, Proceedings of 2000 International Conference on Intelligent User Interfaces, New Orleans, 2000, p. 106-112.
[IBM] IBM IBMWatson, http://www-03.ibm.com/innovation/us/watson/index.html.
[McKi11] McKinsey Global Institute Big data: The next frontier for innovation, competition, and productivity, 2011.