Johannes Kepler, a German 17th century astronomer, famous for discovering how planets revolve around the sun, is supposed to have said that ‘logarithmic tables’ had doubled his lifespan. If a simple list of numbers can do this for an academic 400 years ago, imagine the impact of artificial intelligence (AI) on the life of a modern-day financial advisor. Embracing AI means eternal life is within their reach. Where Kepler used observational data of the planets gathered by the Danish astronomer Tycho Brahe, the modern-day financial advisor uses the abundance of data currently available. Its volume has exploded over the last 10 years. The combination of prolific processing power, data, data storage and AI has revolutionized the domain of recommendations; it allows the real-time delivery of automated, personalized advice. When this type of advice is related to financial products, we use the term ‘robo-advice’.
During the time of Kepler and Brahe the institutions in charge tried to control their scientific work and output ([Koes59]). How should 21st-century authorities respond to ‘robo-advice’ and the use of artificial intelligence? Should these possibilities be controlled and if so, how can this be done by the providers themselves?
Introduction
Humans have been providing advice since the dawn of time. It therefore doesn’t come as a surprise that automated advice, in the form of search engines, has been both a primary attribute and driver of the Internet. Without automated advice most on-line services and information would remain hidden from potential users or clients. We would still be reading magazines similar to the old-fashioned TV guide to navigate through the endless Internet universe. The business model of many successful and popular on-line enterprises also depends on the recommendation paradigm. Its capability has made global brands of companies such as Amazon, Netflix, Spotify, Booking and YouTube.
In addition to those business models aimed at entertainment, the financial sector has also embraced the recommender model. The reasons are numerous. The relationship in the financial sector was traditionally one of trust. Technology and costs have required the financial sector to invest in automation and self-service, however, impacting the relationship between the provider and the client. Clients themselves are expecting the financial services industry to offer them real-time, 24/7 digital services to assist them in what remains a complex domain. These expectations can be met by traditional providers as well as by providers outside the financial sector, such as Fintechs. They can target a European market that has increased significantly over the last 20 years due to the introduction of the Euro, passporting rights for financial firms and the removal of national barriers. All made possible by a legislator that aims to make Europe fit for innovation. However, that same legislator has introduced many additional regulatory obligations and prohibitions to protect the client and market. Rules that potentially increase the complexity and costs of the service.
The asset management industry has seen growth in two ‘recommender’ areas: automated investment advice (robo-advice) and automated portfolio management. Specific attention has been given to these two subjects by a number of national and international regulators during the last five years. This has resulted in guidance on how to tackle risks for providers, clients and the economy at large. The recommender system itself has been blessed by the exciting new possibilities that AI is offering. Used correctly, AI will allow recommendation systems to provide advice that cannot be matched by conventional technology or standalone human advisors. However, AI has introduced its own new challenges.
This article will discuss the principles of a recommender system, explain where AI is used, guide the reader through the different types of advice and identify when an activity qualifies as financial advice, share the traps and pitfalls of robo-advice and recommend mitigating controls the (internal) auditor will be expecting.
The Recommender Model
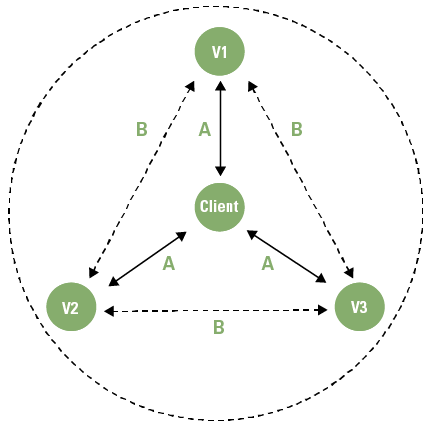
The principles of a recommender model are not hard to understand. In essence, a recommender system filters information and seeks to predict the rating or preference a user would give to an item ([Ricci11]). Generally, this system is based on one of three models: the collaborative filter model, the content-based model or the knowledge-based model (see Figure 1).
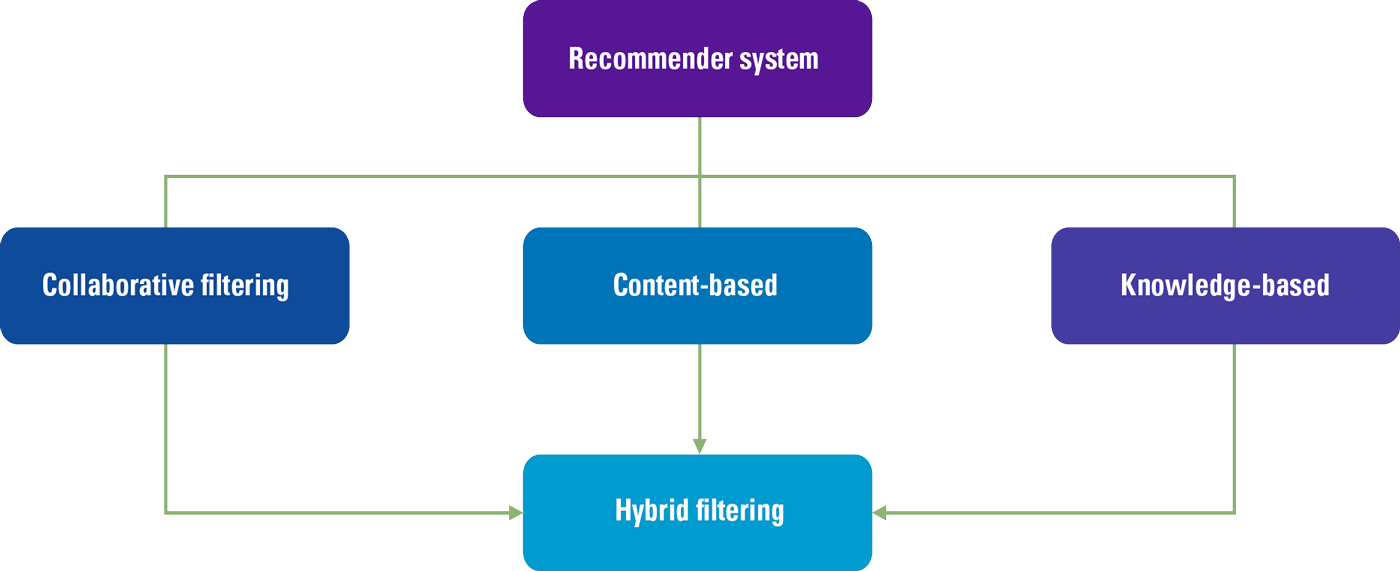
Figure 1. Recommender Models. [Click on the image for a larger image]
A collaborative filter model uses information of the behavior of many users with respect to a particular item. Hence the name ‘collaborative’. The content-based model requires information (i.e. content) about the item itself. Therefore, if the item is a book, a collaborative filter approach would gather the number of times people would search for the book, buy the book and rate the book in order to predict the preference of a client. The content-based approach would use attributes of the book itself: its title, author, language, price, format, publisher, genre etc. Content-based systems therefore seek similar features while collaborative filter systems seek similar attributes. The third model, the knowledge-based system, is based on explicit information about the item assortment, user preferences, and recommendation criteria. This system relies heavily on the identification of specific rules to determine when – in a given context – the right item is advised to the user. A system could also be based on a combination of the three techniques creating a hybrid system.
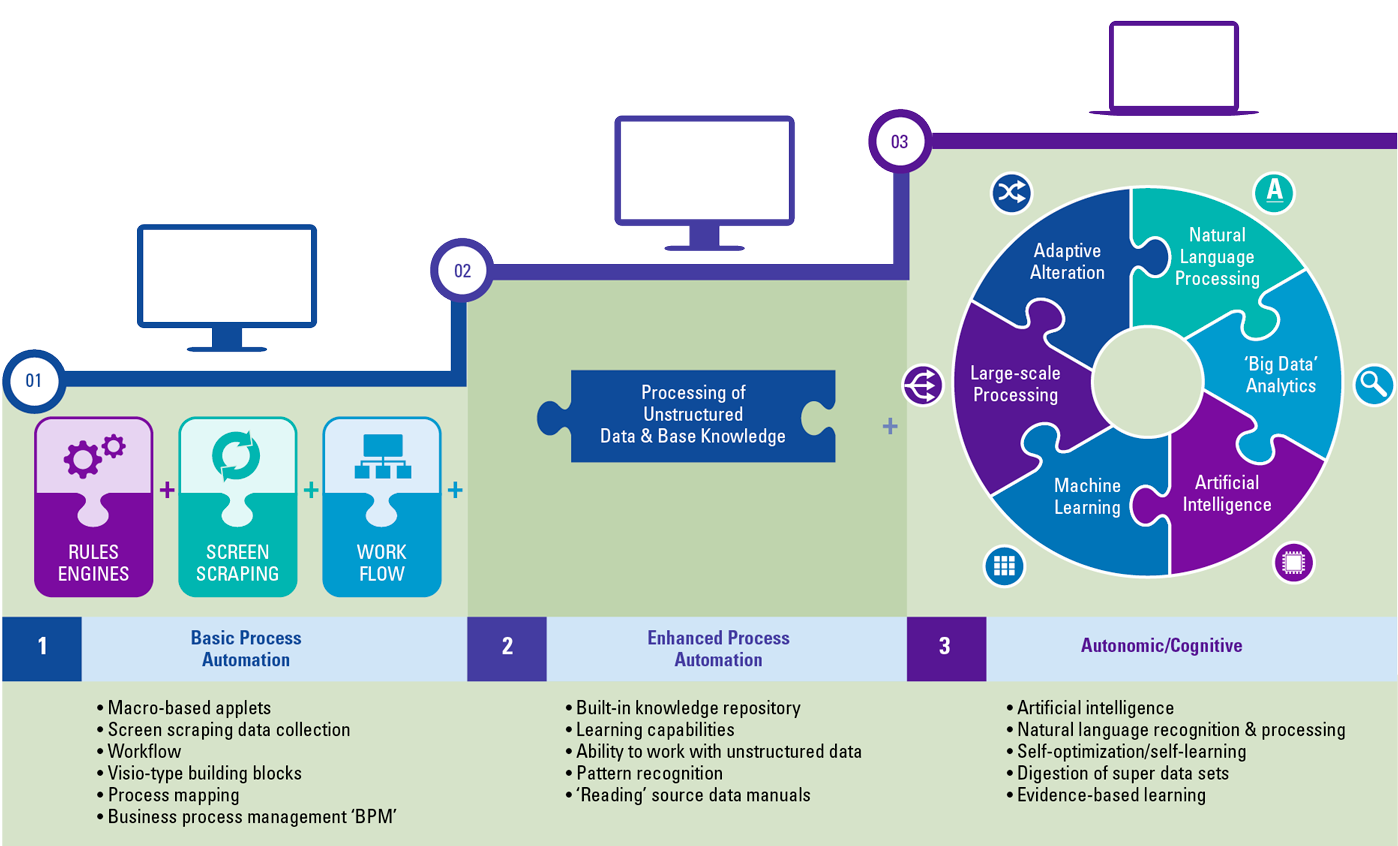
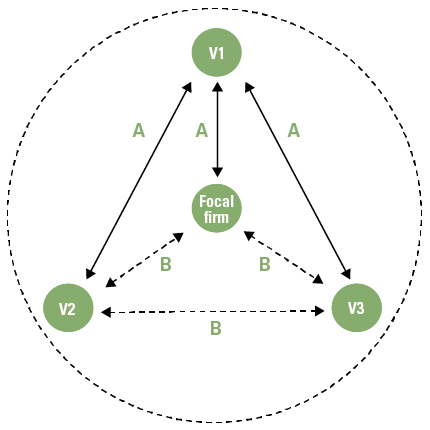
What is the (new) role of AI in a recommender system? AI is a suite of technologies that distinguishes itself by its ability to recognize patterns from structured and unstructured data based on accuracy and confidence ratings/weightings. One example of such an AI technology is the ‘neural network’ paradigm, a generic capability that was until recently limited to biological brains only ([Vost17]). With AI technology, recommender systems can be built that identify the required associations automatically. As such, using AI as a technology allows the development of automated adaptive (autonomous) recommendation systems that train themselves and improve in time (see Figure 2). The disadvantage of using AI is that it may become impossible to explain why the system has generated a specific recommendation, the AI dilemma of unexplainability.

Figure 2. Simplified AI Recommender Architecture. [Click on the image for a larger image]
When does a recommendation qualify as robo-advice?
Recommender systems are applied all around us, from products to services, to events: there are possibilities within many markets, such as retail, media and entertainment, healthcare, government and transportation. In essence, a recommender system helps a company to retain its customers by engaging with them. This increases loyalty and sales. Although they are most often associated with the retail and entertainment business, recommender systems are common in the financial services sector, where they are known under the generic term robo-advice.
It’s the legislator and the financial regulators that have started to use the term robo-advice exclusively within the context of the financial services industry, a heavily regulated segment of the economy. A joint discussion paper by the three European Supervisory Authorities for the financial sector (see box “Supervisory model Europe”) has identified three main characteristics of a robo-advice system ([ESAs15]):
- The system is used directly by the consumer, without (or with very limited) human intervention;
- An algorithm uses information provided by the consumer to produce an output;
- The output of the system is, or is perceived to be, financial advice.
The first two characteristics, A and B, have been discussed as part of the explanation of the recommender model. Characteristic C requires more analysis as the definition of financial advice depends on the regulatory and supervisory regime applicable to a firm’s business model and jurisdiction.
Supervisory model Europe
In Europe, the financial services sector is divided in three areas, with each area having its own European Supervisory Authority (ESA):
- The European Banking Authority (EBA);
- The European Securities and Markets Authority (ESMA); and
- The European Insurance and Occupational Pensions Authority (EIOPA).
A national competent authority or supervisor is usually responsible for providing the license. The Netherlands has a twin-peak supervisory model. Prudential supervision is the responsibility of the Dutch Central Bank (DNB) and conduct supervision is the responsibility of the Authority for the Financial Markets (AFM). Some banks however are supervised by the European Central Bank (ECB).
Irrespective of robo-advice, it is always important for a firm to assess if the firm is required: (i) to notify a supervisor, (ii) to have a license or (iii) is exempt of any license requirements. In addition, firms need to know the regulatory regime applicable to their business model. For example, depending on the service, product and client segment, the Dutch conduct supervisor AFM exercises supervision under one of two acts: either the Financial Services Act (FSA) or the Consumer Protection Enforcement Act (see box “European regulatory regimes”).
European regulatory regimes
Membership to the European Union (EU) requires member states to transpose European Directives to national regulations such as the FSA. The flood of new or adapted European legal frameworks such as Solvency II, Insurance Distribution Directive (IDD), Capital Requirements Directive (CRD), Markets in Financial Instrument Directive II (MiFID II), Alternative Investment Fund Managers Directive (AIFMD) and the Market Abuse Directive (MAD) has resulted into significant changes to national financial regulatory frameworks. In addition, sector agnostic regulation has also impacted national legislation. A well-known example is the General Data Protection Regulation (GDPR), which has been applicable since May 2018 in the Netherlands, replacing national legislation (Wet bescherming persoonsgegevens (Wbp)).
A successful license application results in a registration in the applicable register at the applicable supervisor. The register will specify, among others, the Financial Service Type, the Service/Activity permitted and the date of entrance. The (internal) auditor should validate that the license provided matches the activities carried out by the firm. If this is not the case, it should be reported to the supervisor.
Unfortunately, not every regulatory regime is always clear about the meaning of financial advice. For example, the Markets in Financial Instruments (MiFID II) framework, which governs investment services, mentions four different types of advice related to investment activities ([EU14]):
- Generic advice: advice provided about the types of financial instruments, e.g. small cap equities;
- General recommendation: investment research and financial analysis or other forms of general recommendation relating to transactions in financial instruments;
- Corporate financial advice: advice to undertakings on capital structure, industrial strategy and related matters and advice and services relating to mergers and the purchase of undertakings;
- Investment advice: the provision of personal recommendations to a client, either upon its request or at the initiative of the investment firm, in respect of one or more transactions relating to financial instruments.
Of these four types of advice, only investment advice is an activity/service that always requires a license to operate in Europe. Of the other three types, both ‘general recommendations’ and ‘corporate financial advice’ are recognized as ancillary services. They don’t necessarily require a license. However, when the provider provides an ‘investment service’ such as ‘investment advice’ these ancillary services may introduce additional requirements.
Fortunately, the European authority ESMA has done some preparatory work to help companies understand the meaning of ‘financial advice’. It has defined five criteria ([CESR10]) to identify when an activity qualifies as ‘investment advice’. This model can be re-used and enhanced to define a decision tree to assess if a financial activity qualifies as ‘financial advice’ (see Figure 3).
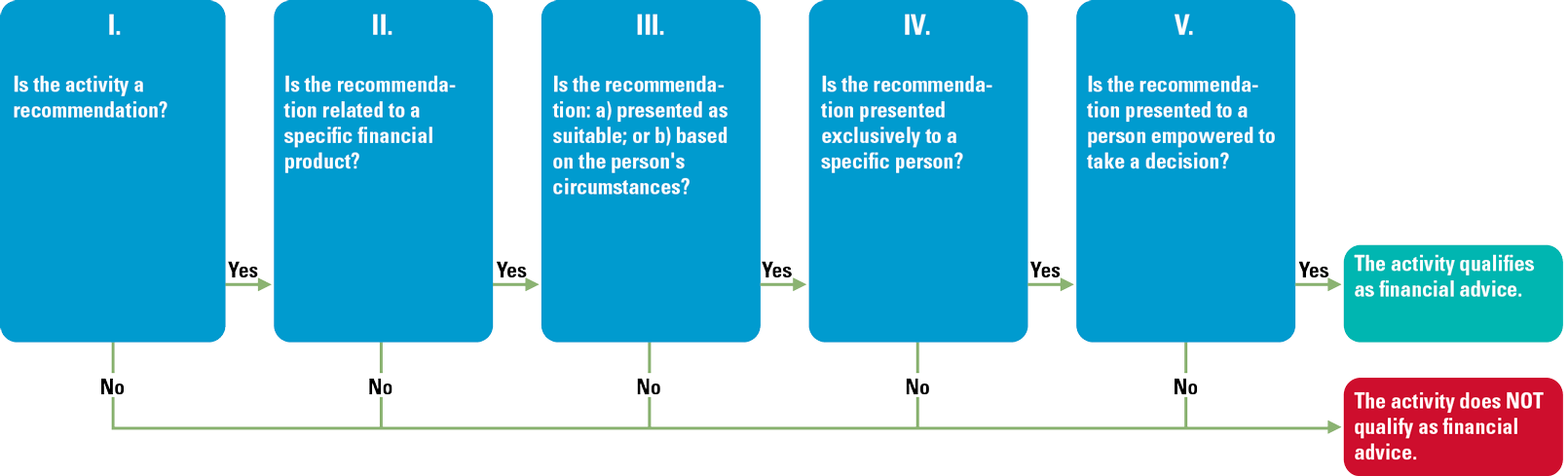
Figure 3. Financial Advice Decision Tree. [Click on the image for a larger image]
The first criterion used to qualify an activity is the question “Is the activity a recommendation? A recommendation requires an element of opinion on the part of the advisor. The second question requires an analysis of the actual outcome of the activity. If the outcome is narrowed down to a recommendation about a specific financial product the answer to this question is ‘Yes’. However, for a recommendation referring to a wide range of products or a group of products, e.g. an asset class, the answer is ‘no’ and an activity with such an outcome is not considered financial advice. Depending on a positive outcome of the three remaining criteria, the qualification of ‘financial advice’ may be given to an activity. Knowing which type of activity we are dealing with allows us to identify the respective regulatory permissions, obligations and prohibitions that have to be implemented. The decision tree may also be used by (internal) audit or compliance to verify the assessment of an existing set of activities.
The traps and pitfall of robo-advice and AI
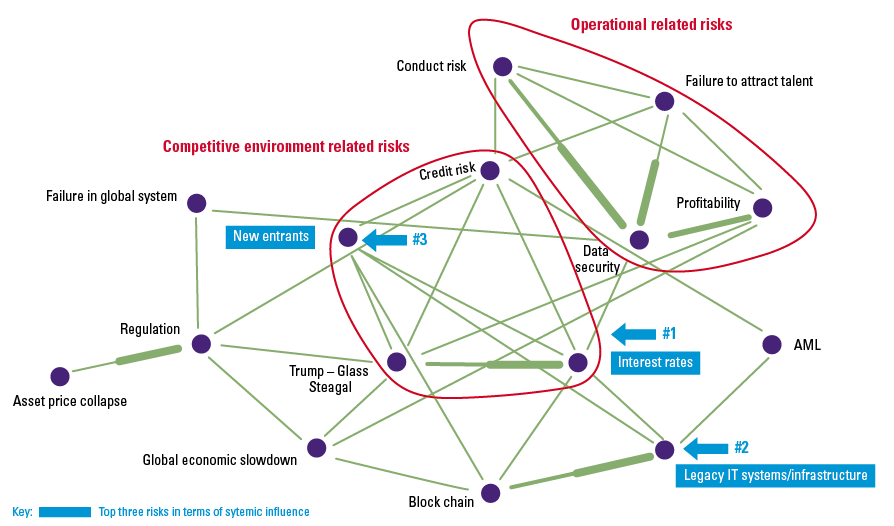
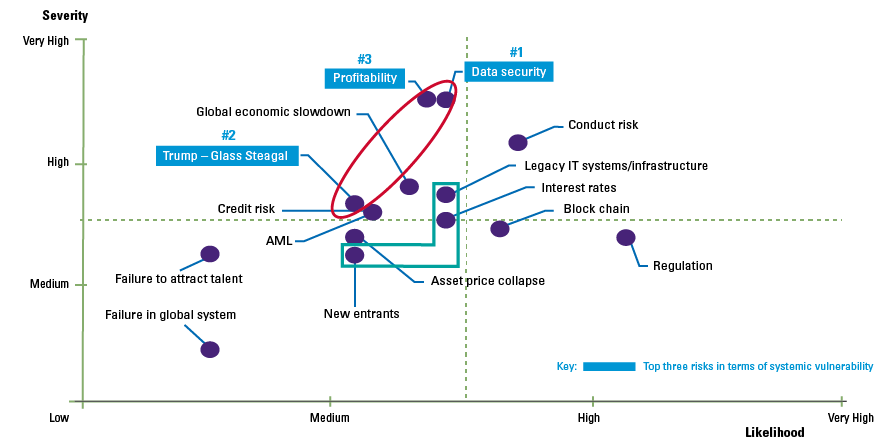
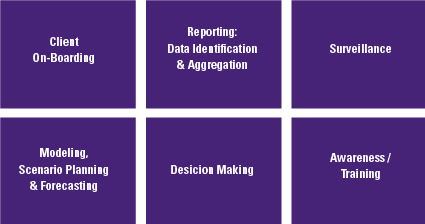
The risks of robo-advice (see Figure 4) are known and have been thoroughly studied by numerous institutions and supervisors ([ESAs18], [BEUC18]). In these reports, the most immediate risk that keeps coming up relates directly to the actual advice as provided by the system.
Robo-advice is perceived by the client to be highly personalized and suitable. Although the quality of automated recommendations has been improving steadily over the years, it remains highly dependent on the availability of the right data and the input provided by the client. An attribute of a recommender model like ‘collaborative filtering’ is that it suffers from ‘cold start’ problems as information regarding other users has not yet been generated. As a consequence, the system may give incorrect or unsuitable advice. Similarly, errors in code or corruption due to a cyberattack may impact the suitability and correctness of robo-advice. Unsuitable advice and prejudice may also be the result of (unintentional) biases in the application itself (see box “Biases”). All in all, advice must allow the recipient to make well-informed decisions and the provider should ensure that the advice is compressible, correct and suitable.

Figure 4. AI & robo-advice risk. [Click on the image for a larger image]
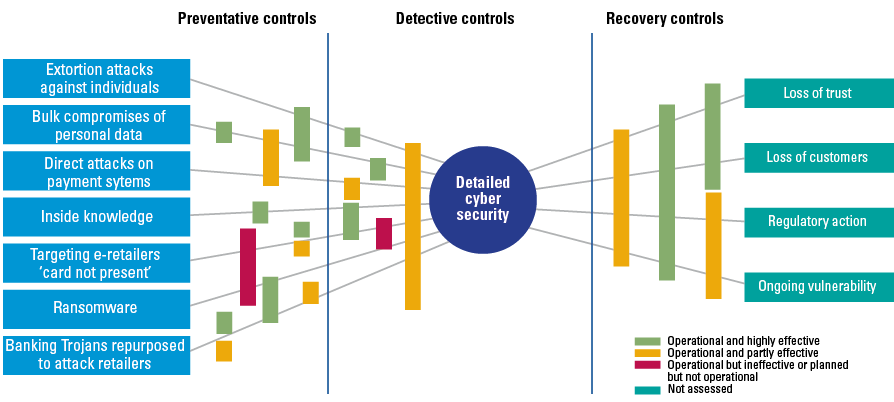
A continuing concern of robo-advice is the possible abuse of user data. Robo-advice makes use of personal data, i.e. information that can be used to identify an individual, that is often combined and aggregated within the system. The more this happens, the more difficult is becomes to de-identify the data to preserve the privacy of the users. Data privacy and data access are closely linked risks. Any access to personal data should be highly restricted in such a way that only those authorized and qualified to do so can have access. On the other hand, access to personal data is a fundamental right for any user, addressed in data protection regulations such as the GDPR. Therefore, any design of a recommender system should include support for this fundamental user right.
One of the risks increased by the use of AI techniques is the explainability of the advice; the ability to explain the decision-making process. In general, the better the AI algorithm, the blacker the box, the more difficult it is to find out why something has happened inside the box. However, as with data access, meaningful information about the logic involved, as well as the significance and consequences of user data is an essential right that must be catered for by the system (GDPR Art.22). Any recommendation made by the robo-advice application must be explainable and auditable.
Biases
Bias in, bias out. AI systems are brilliant at analyzing vast quantities of data and delivering solutions. But there is one major problem: they are bad at understanding how inherent biases in that data might affect their decisions. As a result, a series of headline-hitting cases are drawing attention to the ‘white guy’ problem, where systems make decisions that discriminate unfairly against certain groups ([KPMG17]).
How can companies mitigate the risks of robo-advice?
Many arrangements required to eliminate or significantly reduce the robo-advice risks are already known and common practices in the market. Supervisors also agree that additional legislation to cover any robo-advice risks are currently not required ([ESAs18]). Instead, supervisors state that the complexity of existing applicable regulation, such as MiFID II, IDD, GDPR, PRIIP, is a regulatory barrier preventing the development of automation in the financial sector ([ESAs18]).
A menu of possible arrangements to control robo-advice risk based on best practices and current regulatory obligations allocates the measures to either client/product related activities on the one hand and algorithm related activities on the other hand.
Client/product risk mitigation
In order to mitigate the client and product risks identified in the previous section, companies should introduce measures for product governance, client onboarding, disclosure design, cost transparency and suitability statement (see Figure 5).
Product governance
Companies should develop, approve and review their product for use within robo-advice. This should include the critical identification and assessment of both new and existing products, including their business and operational aspects, with all relevant stakeholders. The critical assessment should include a clear description of each product in scope, its target market including the knowledge and experience required by the potential clients to understand the product, the suitability of the product with the target market’s risk profile, a definition of the risk category and suitability to cover the target market’s financial objectives and needs. Every product should be explicitly approved by the robo-advice service.
Client onboarding
Companies should implement arrangements to identify a client’s knowledge and experience, its financial position, its ability to bear losses, its financial (investment) objectives and its risk profile. Where applicable, a client should be allocated to a client category, e.g. retail or professional. Companies should explicitly identify if robo-advice is suitable for the client before offering the client the possibility to receive advice.
Disclosure design
Companies should pay attention to the disclosure of information, both regarding the actual robo-advice application as well as the use of personal data by the application and the presentation of the recommendations. Behavioral insights into the presentation of disclosures should be used to optimize the client’s understanding of essential information and resulting behavior ([IOSC19]). Companies should use design features, such as layout and warnings to assist clients in making informed decisions.
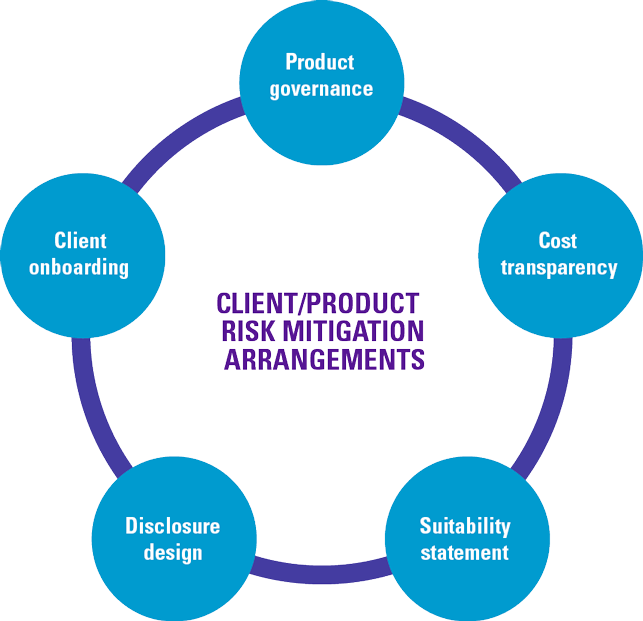
Figure 5. Client/product risk mitigation. [Click on the image for a larger image]
Cost transparency
Before a client uses any service, companies should share any costs and charges with the client. If the client uses robo-advice, companies should provide the client with a complete overview of all possible costs that may occur before the client decides to accept the advice. Companies should provide an overview of the ex-post costs occurred as well. This overview should match the ex-ante information. Any discrepancies should be explained.
Suitability statement
Every advice provided should include a suitability statement. This suitability statement should include an assessment of the clients’ knowledge and experience, financial situation and investment objectives based on information obtained from the client. In addition, the statement should include a reference that the robo-advice systems recommendations will not reduce the responsibility of the company. They may also further include details regarding a periodic assessment of the suitability of the advice given.
Algorithm risk mitigation
In order to mitigate the risks related to the algorithm used by the robo-advice system, companies should introduce measures for controlled Development and Change Management Process, algorithm transparency, pre and post-advice controls, real-time advice monitoring and periodic assessment( see Figure 6).
Controlled Development and Change Management Process
The firm should have a transparent development and deployment process with defined responsibilities. It should ensure the proper functioning and stability of the algorithm by supporting tests to assess the correctness of the software using white and black box methodologies. The change management process should support clear responsibilities and record keeping regarding the time and nature of the change, and who approved the change and subsequent deployment. Access to the development and change management environment should be restricted.
Algorithm transparency
The design of the algorithm should be such that it complies with all applicable regulatory requirements. Documentation of the algorithm should include, but is not limited to: a brief overview; the current status; the date the algorithm was approved and, if appropriate, retired; detail any restrictions placed on the algorithm when approved; a detailed description of its functionality and design such that the firm understands the risks that the algorithm exposes the firm to.
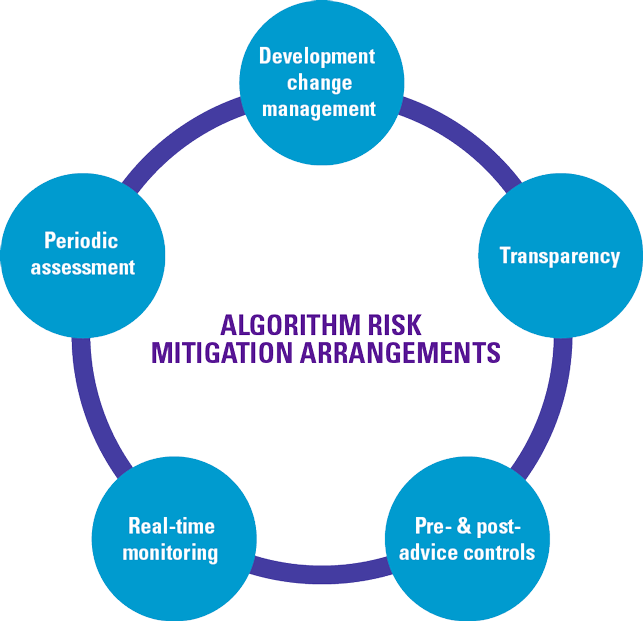
Figure 6. Algorithm risk mitigation. [Click on the image for a larger image]
Pre and post-advice controls
Companies should define and implement pre and post-advice controls. Pre-advice controls should include support to control the product group, the target market, the negative target market, risk profiles and the ability to bear losses. Post-advice controls include the availability of a mandatory suitability statement and avoidance of negative target market. Companies should have procedures in place to detect and respond to any pre and post-advice alerts.
Real-time advice monitoring
Firms should implement arrangements to validate confidentiality, integrity and availability of the robo-advice application. The arrangements should support real-time alerts.
Periodic assessment
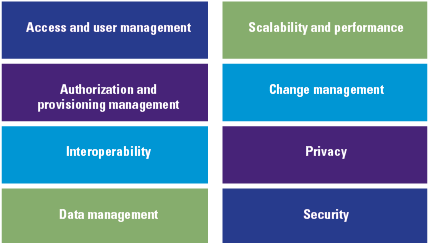
Companies providing robo-advice should have management in place that reviews the application and algorithm(s) periodically to assess any unintended results (including biases) and their suitability for the profile of the clients and the company. Depending on the integration of AI in the robo-advice application, companies should examine to what extent the application is a responsible one (see Figure 7) in order to assess the use of an AI framework as presented by the Dutch central bank (DNB) in 2019 ([DNB19]).

Figure 7. Applicability matrix of DNB AI principles. [Click on the image for a larger image]
Conclusion
By providing robo-advice, companies are able to address a number of challenges: product volume and complexity, personalization, customization, service differentiation and regulatory compliance. Robo-advice provides the client with a suitable recommendation, allowing the client to take a well-informed decision while creating economies of scale for the provider.
The provider should check out any required licenses or registrations, identify related regulations and guidelines, and design its service in such a way that it complies with national and international (European) legislation. Using AI to enhance the quality of a recommender system brings additional advantages, provided the challenges of explainability and transparency are addressed.
Risks related to robo-advice are always present; this article provides guidance in how to control these through mostly existing best practices. Given that regulatory requirements for robo-advice are – for the time being – not more stringent than general finance advice and that specific legislation for robo-advice is not expected to be introduced in the near future, this is the right time to develop an automated advice service.
References
[AFM18] AFM (2018). The AFM’s view on robo-advice. Opportunities, duty of care and points of attention. 15 March 2018.
[BEUC18] BEUC (2018). Automated decision making and artificial intelligence – A consumer perspective. 20 June 2018.
[CESR10] CESR (2010). Question & Answers. Understanding the definition of advice under MiFID. 19 April 2010.
[DNB19] De Nederlandsch Bank (2019). General principles for the use of Artificial Intelligence in the financial sector.
[ESAs15] ESAs Joint Committee (2015). Joint Committee Discussion Paper on automation in financial advice. 4 December 2015.
[ESAs16] ESAs Joint Committee (2018). Joint Committee Report on the results of the monitoring exercise on ‘automation in financial advice’. 5 September 2018.
[EU14] European Parliament (2014). Directive 2014/65/EU of the European Parliament and of the Council of 15 May 2014 on markets in financial instruments and amending Directive 2002/92/EC and Directive 2011/61/EU Directive 2014/65/EU.
[IOSC19] IOSCO (2019). The application of behavioural insights to retail investor protection. OICV-IOSCO, April 2019.
[Koes59] Koestler, A. (1959). The Sleepwalkers. London: Hutchinson.
[KPMG17] KPMG LLP (2017). Advantage AI.
[Ricci11] Ricci, F., Rokach, L. & Shapira, B. (2011). Introduction to Recommender Systems Handbook. In: Ricci, F., Rokach, L., Shapira, B., & Kantor, P. (eds.), Recommender Systems Handbook. Boston: Springer.
[Vost17] Voster, R.J. & Slagter, R. (2017). Autonomous Compliance: Standing on the shoulders of RegTech! Compact 2017/4.