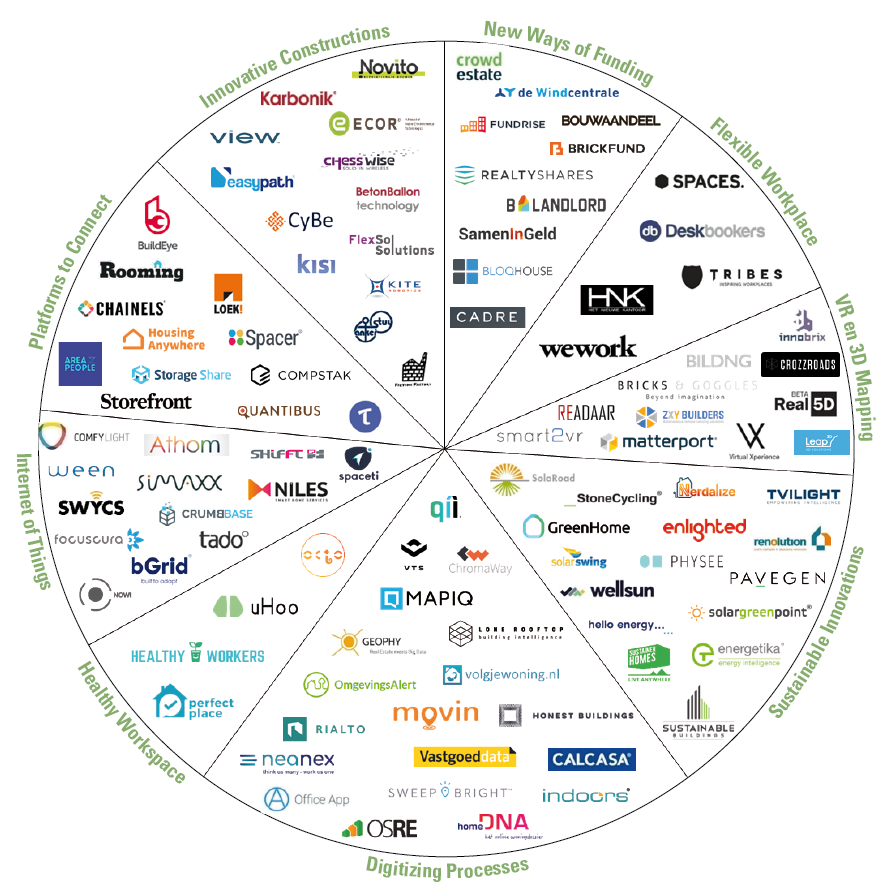
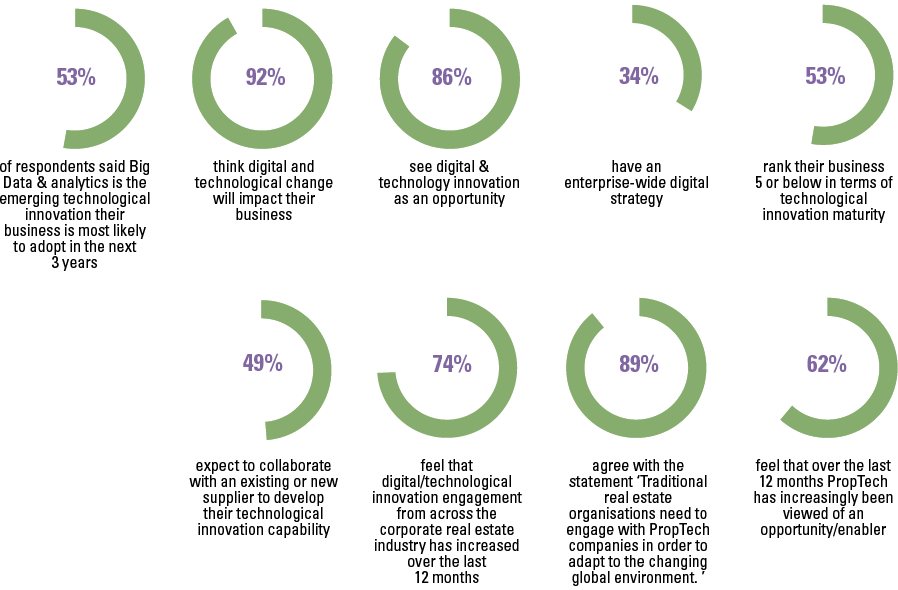
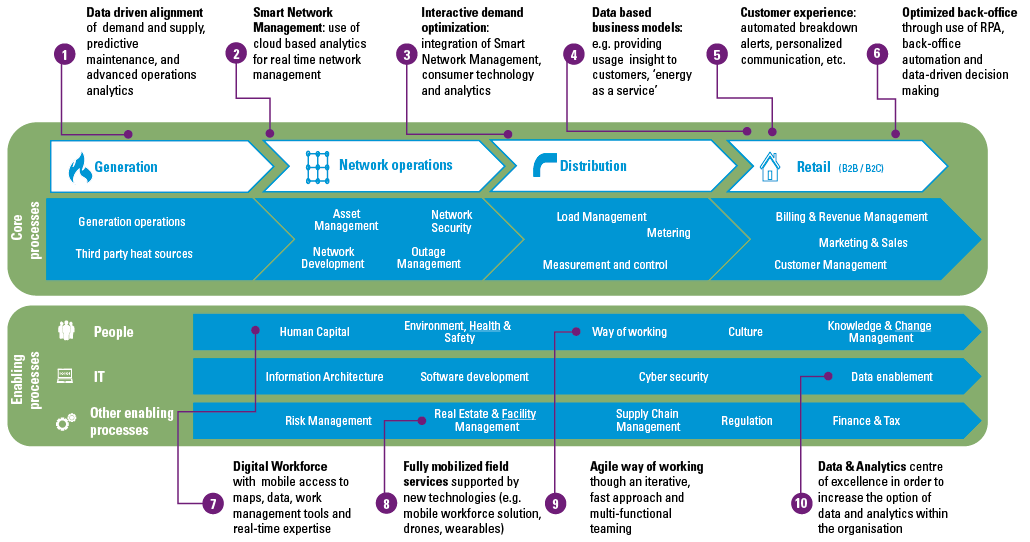
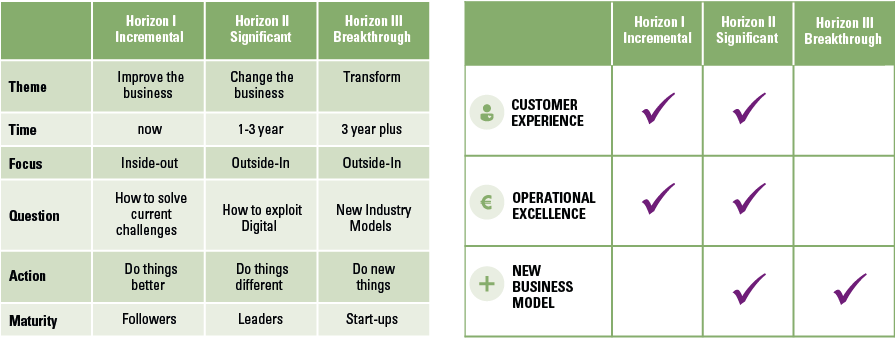
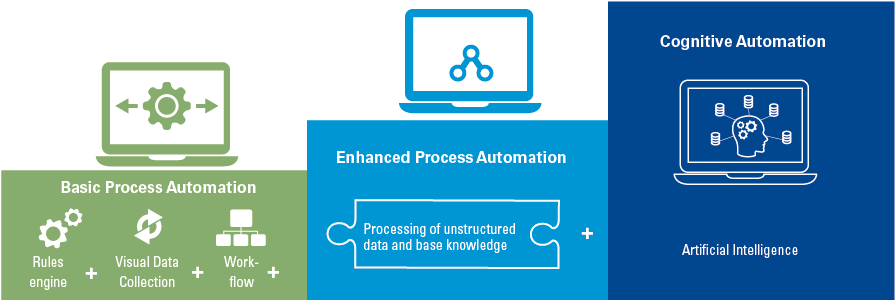
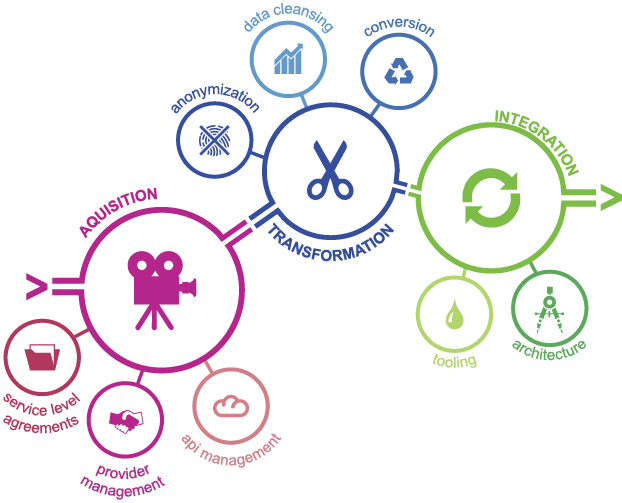
Despite the growing possibilities to collect, store, report and analyze data, organizations still struggle to transform their businesses. Business value needs to be unlocked from data; businesses need to address their growth, risk and cost strategies to truly enable employees and create the fundamental value they need to ‘talk’ data and become more data-literate.
Introduction
Digital transformation is the name of the game these days for many organizations. This is founded in a wide and impressive range of new (information and communication) technologies that have a growing impact on business outcomes ([John18]). Data, analytics, intelligent automation and artificial intelligence have become more mature and are fundamental to the current age of digital transformation. The creation of a data-driven culture helps drive these successful business outcomes.
However, while most organizations focus on the potential of data-driven technologies (like data lakes, data platforms and incorporating artificial intelligence or machine learning), the technologies must be carefully cultivated to become a trusted core capability. Real value often only comes with scalability, repeatability and effective deployment, where algorithms are used to enable humans and data-driven technologies are embedded into organizations’ day-to-day business. To truly enable people, they need to have a better understanding of the insights data provide using analytics, and how it can improve the way they work. Data needs to become a native language; people need to ‘talk’ data and become more data-literate. Data literacy – the ability to understand, engage, analyze and reason with data – is a key factor for successfully implementing a data-driven culture within an organization.
Data Literacy
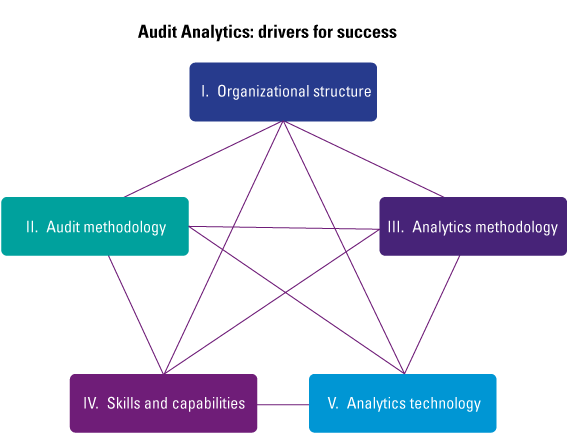
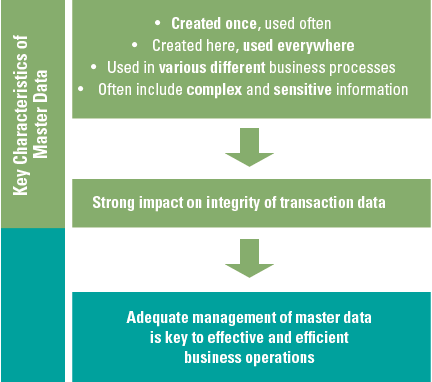
The urge of organizations to use data within their organization is built on the fact that enormous amounts of data are available, which can create valuable insights. While organizations are starting to use advanced analytics and are exploring the power of machine learning and artificial intelligence, they are still struggling with successfully implementing solutions in their day-to-day business. This is not due to technical limitations since developments and innovation in the data analytics field come at a tremendous pace. It is because there is a gap between data experts or analytical specialists, and the business users that need to understand the analysis and turn it into business insights, actions and ultimately value. This gap can be filled by further educating the organization on the concept of data as fuel for the analytics that give the insights to improve the work, and by educating the data experts on the business implications of analytics. All hierarchical layers within an organization need to have at least a basic understanding of the concept of data, and they need to be able to understand and engage with data fitting their role and start talking the language of data. Making business decisions based on gut feeling is a thing of the past; acting upon solid factual data needs to become the company-wide standard. This requires an organization to elevate on the four cornerstones of data literacy – understand, engage, analyze and reason with data (Figure 1).
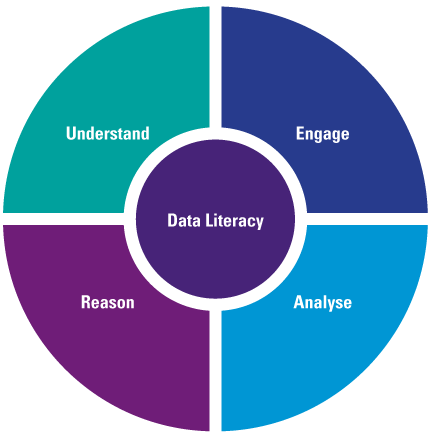
Figure 1. Four cornerstones of Data Literacy. [Click on the image for a larger image]
Understand
In order to start working with data, you need to be able to understand the data. Data is usually presented in various forms within an organization, such as a bar chart, pie chart, table or pivot. A user should be able to understand what is presented in the graph. What does the data tell us? Which insights can be derived from it? What is the impact on business processes? It also requires critical thinking about the presented data. For example, let’s consider an interest rate dataset with the interest rate per year. Visualizing the data in a bar chart can give a good overview of the increase or decrease of the interest rate over the years. However, with a wrongly chosen scale size, the visualization can suggest that there is a large increase of the interest rate. When we closely look at the scale size, we see that the actual difference in years is minimal (Figure 2).
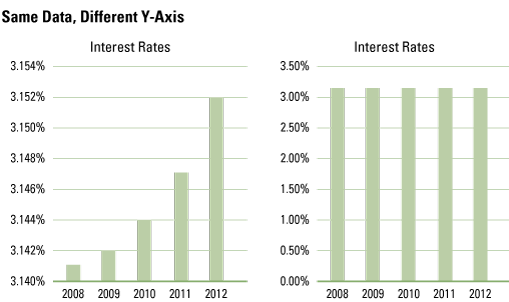
Figure 2. Example of a bar chart visualization with misleading scale size (left).
Next to understanding the visualization, we often see that organizations struggle to understand the insight. When the organization was asked if the progressive line on the interest rate had a positive or negative effect for the organization, they were not able to answer. Fully understanding the data also requires not taking the data for granted and being able to critically think about the visualizations and analysis shown.
Engage
To engage with the data, people need to use data and know what is available within the dataset. This includes knowing how the data is composed; understanding the type of data; where it originates from and who is using it. Answering these questions will help understand the data and its context. A first step is to look at the data definitions or define them when not available. Using data definitions, you can establish the type of data fields and the expected values. This closely relates to data management, where large datasets definitions and characteristics of fields are defined within a data catalog. Engaging with the definitions helps understand the data. Another aspect that better helps engaging with the data is finding out or knowing who the data consumers and data producers are. Knowing who created the data will give you a perspective of what should be represented and with what perspective the creator created the dataset. Imagine a business controller who needs to create a guiding report for the organization: if there is a mere focus on the look and feel of the graphs, while understanding the dataset at hand is ignored, it could result in wrongly chosen data elements, or critically incomplete information.
Analyze
Inevitably, the skillset to analyze a dataset is an important step in becoming more data-literate. Understanding data and being able to engage with data helps in starting discussions and shifting from creating information to creating insights and ultimately concrete business actions. These insights can only be generated by analyzing the data. Being able to use statistical and analytical methodologies to create valuable insights will become a skill that is necessary for more and more (business) roles within an organization. With the world becoming more data centered and data savvy, organizations and departments will not solely rely on data scientists providing useful analyses. Creating valuable insights from a given dataset and analyzing the data is becoming more and more a combination between technical skills and business knowledge. The analytics and business perspective will converge further. A data scientist is not able to create business insights if he is not comfortable with the business perspective. On the other hand, business users need to have a certain level of understanding of analytics in order to work together with a data scientist and comprehend their approach on analyzing a dataset for a specific business purpose. This doesn’t imply that a business user needs to deep-dive into algorithms used or become an expert in data analytics, but it does require a business environment with a high level of trust in the insights provided by the black box of analytics ([Pato17]). You also don’t have to be an engineer to drive the most technical enhanced car, but you should trust it.
Reason
One of the most important, and complex, aspects of data literacy is the ability to reason with data. Understanding and analyzing data is important, but if you cannot talk the language of data or reason with data in a proper way, misalignment or misunderstanding will take place. Communicating with data can be done verbally but also by showing visualizations. The power of a good visualization is often underestimated, especially because a chart can perfectly support your story or emphasize the point you’re trying to make. Telling the right story and guiding your audience through the steps you have followed within an analysis will clarify your results and create a starting point to discuss the impact of the results. When doing this, always consider the level of data literacy of your audience, to ensure you send a clear message that can be understood by everyone.
Levels of Data Literacy
Becoming data literate is important, but the required proficiency depends on the data role of the business user. According to Gartner [Loga17] there are five levels of proficiency in data literacy: conversational, literacy, competency, fluency and multilingual (Table 1).

Table 1. Gartner’s Data Literacy levels of proficiency. [Click on the image for a larger image]
Although it would be helpful if your entire organization is multilingual, it is not a necessity. For example, a business controller will not write complex statistical models, but should be able to understand and interpret analyses done by data experts. The different levels of proficiency strongly relate to the four cornerstones of data literacy (understand, engage, analyze and reason), where the cornerstones overlap usually two levels of proficiency. People on a conversational level will focus on reading and understanding data. They can have basic understanding of the analytics done, but aren’t able (yet) to communicate or explain these results clearly to others. People with a higher competency level are more focused on analyzing and reasoning with data. They have the skillset to perform advanced analytics and make sense of a given dataset, but still may lack profound communication skills. Finally, people with a multilingual level of proficiency cover the entire spectrum of data literacy, but do not have to be an expert at every level. They have solid communication skills, analytical capabilities and understand and interpret the data effortlessly.
Data Roles
Data roles define the different data personalities which exist within the organization. Organizations are made up of different people with different backgrounds, interests, intrinsic motivation and organizational focus areas. To become data-driven, the organization needs to focus more on data and create a culture where data literacy is embraced. The culture is a key to ensure championship, stewardship and change. KPMG defines four data roles for the business users, with different data skills, capabilities and learning requirements (Figure 3).

Figure 3. Four data roles within a data-driven organization. [Click on the image for a larger image]
Data Believer
Data believers are people with limited to no analytical knowledge, but need to understand and engage with data in order to make business decisions. These are typically people that have extensive business knowledge, but little analytical capabilities, such as C-level or management. The mindset of a data believer needs to change from making decisions based on gut feeling to making decisions based on data analysis. To achieve this, it is vital to understand the data and steps performed within an analysis. Be aware that you sometimes need to convince people of the power of data in order to turn them into data believers and letting them see the added value of data.
Data User
Data users need to incorporate data and analyses in their daily work. These people need to be able to understand and engage with the data, like business controllers of process owners. Important for them is that they know what’s in the dataset, understand where the data is coming from and the insights that can be derived. Generally, the analytical capabilities are very basic and need to be developed to a proper level. Although the data user doesn’t need to be as technical as a data scientist, understanding analyses and more complex methodologies is important.
Data Scientist
These are typically the data gurus who have profound analytical and statistical skills, such as data scientists or data analysts. Generally, no further development is required in the area of analytical and statistical methodologies. The focus areas for a data scientist would be to improve on communicating, explaining and reasoning with data regarding business users in order to reach a level of data fluency or even multilingualism. Implementations of their (advanced) analytical methodologies strongly depends on the capabilities of a data scientist to explain and show their analysis results to business people (for example data believers) and give useful insights.
Data Leader
Data leaders have a good understanding of the data, can interpret results or analyses and have a good level of understanding analytical methodologies. You can think of business analysts, information analysts or BI specialists. Data leaders are the front runners of data literacy within your organization. They see the added value of using analytics in day-to-day business and understand the impact of an analysis. A data leader doesn’t need to have the same level of analytical skills as a data scientist, but is required to be able to apply some analytical methodologies on his own. Furthermore, the data leader needs to be able to communicate, discuss and reason with the data. Data leaders need to understand the complexity of the analysis and follow the steps and then translate them to business users with more limited analytical knowledge.
The four data roles also strongly relate to the previously introduced levels of proficiency (Figure 4). Although all employees are expected to talk the language of data, a data believer will focus on a conversational level, while a data leader needs to have the capabilities to talk data fluently.
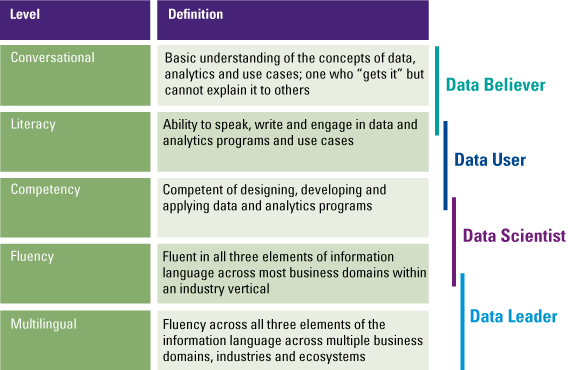
Figure 4. Relation between levels of data literacy levels of proficiency and data roles. [Click on the image for a larger image]
How to become data-literate
The key question for organizations now is on how to become more data-literate and support the creation of a data-driven culture. A data-driven culture determines how an organisation operates and gets things done with data, as an answer to internal and external challenges. While cultures in organizations are usually focused on creating a certain mindset and daily work, the technicalities of data also require an individual capability improvement based on the data roles to gain the required level of data literacy. Becoming data literate is merely an organizational exercise, but with implications on technical capabilities. KPMG’s global Behavioral Change Management (BCM) methodology [KPMG16] provides a step-by-step process for culture change programs to support becoming more data literate.
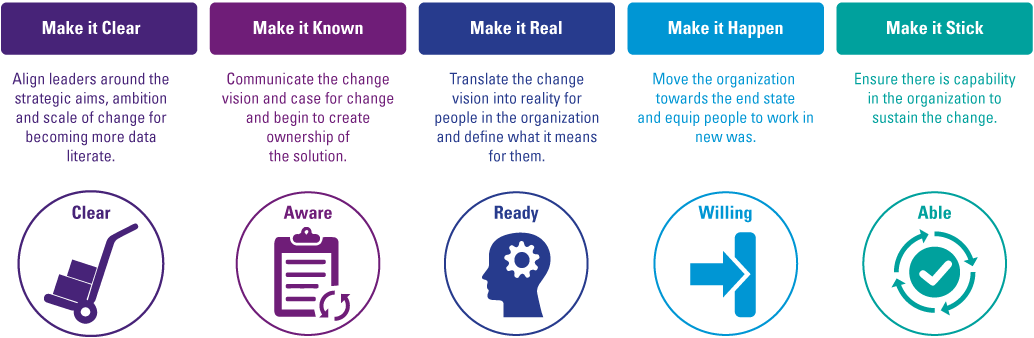
Figure 5. KPMG’s global Behavioral Change Management (BCM) methodology. [Click on the image for a larger image]
The methodology starts with clarifying – in business goals and objectives – why becoming more data literate is important. We see most organizations in the market ground establish the objectives of becoming more data literate regarding the current digital transformation and evolvement of data-driven cultures, with strong (technical) developments in big data, machine learning, augmented and artificial intelligence. Leadership should be aligned with a common ambition that is focused on what can be achieved with data literacy, the expected levels of data proficiency specified for the functions within the organization and how these impacts required behavior and ways of working. The ambition needs to be communicated top-down and people need to be engaged with data literacy. This is a perfect moment to identify the front runners (data leaders in your organization) and create ownership of the cultural change plan.
After creating understanding and awareness in the organization, the change plan needs to be translated into reality for people. Define and communicate the expected level of proficiency and data role per person, the practical implications of the change, and what is expected from people in this process. Actions and specific behaviors for people are defined and monitored as well. As mentioned before, next to implementing the cultural change, people also need to develop their technical capabilities based on their data role within the business. At this point in time you define the development and capability improvement for the people based on their proposed data role. The start is to map people with the different roles of data literacy, in order to adapt the development plan accordingly.
The next step is to facilitate the change and move the organization to the desired end state of data literacy proficiency levels by implementing the practical changes. With the help of the right triggers, tools, training and workshops an enabling environment focused on becoming more data literate is created. The result of this step is people understanding and working with data to support business decisions as a day-to-day activity, with a level of data literacy proficiency suitable for their data role within the organization.
The final step is to ensure that becoming and staying data literate sticks in the culture by continuously managing, communicating and monitoring the change in capabilities.
Conclusion
Shifting towards a data-driven organization, focused on supporting the digital transformation, requires a cultural change. To become data-driven, the organization needs to focus more on data and start using data in their day-to-day activities. Becoming data-literate will provide people with the necessary capabilities and change of mindset to incorporate data-driven initiatives. By defining your data roles, defining the expected levels of data literacy proficiency and designing your cultural change plan, your organization can start speaking data as a native language and will be ready to drive real impact in the digital transformation.
References
[John18] A. Johnson et al., How to build a strategy in a Digital World, Compact 2018/2, https://www.compact.nl/en/articles/how-to-build-a-strategy-in-a-digital-world/, 2018.
[KPMG16] KPMG, Behavioral Change Management (BCM) Method, KPMG, 2016.
[Loga17] Valerie Logan, Information as a second language: enabling Data Literacy for Digital Society, Gartner, https://www.gartner.com/doc/3602517/information-second-language-enabling-data, 2017.
[Pato17] J. Paton and M.A.P. op het Veld, Trusted Analytics, Compact 2017/2, https://www.compact.nl/articles/trusted-analytics/, 2017.
A special thanks goes to Chantal Dekker, Joris Roes and Ard van der Staaij for providing us with valuable input on cultural change management, performance management and data management.