



De Algemene Verordening Gegevensbescherming (AVG) noemt pseudonimisering als maatregel om tot een persoon herleidbare gegevens op passende wijze te beschermen. Maar hoe doe je dat? En hoe sterk moet de oplossing zijn? En wat levert de toepassing je als organisatie op? Geldt er een verlicht AVG-regime voor het omgaan met gegevens als deze gepseudonimiseerd zijn? Veel organisaties worstelen met deze vragen. Dit artikel gaat in op deze vragen aan de hand van een aantal praktijkvoorbeelden.
Inleiding
De AVG vereist de inzet van technische en organisatorische maatregelen om persoonsgegevens op passende wijze te beschermen. Pseudonimisering wordt daarbij genoemd als mogelijke maatregel. Maar wat is pseudonimiseren en welke eisen worden eraan gesteld? En wat zijn de gevolgen voor de bruikbaarheid van de gegevens? In het maatschappelijk verkeer worden de termen pseudonimiseren, anonimiseren, de-identificeren, maskeren en coderen regelmatig door elkaar heen gebruikt of gecombineerd tot prachtige termen als ‘pseudo-anonieme’ of ‘dubbel gepseudonimiseerde key-coded’ data als resultaat. Termen die de suggestie wekken dat het wel goed zit met de privacybescherming. Het is uiteraard de vraag of dat daadwerkelijk het geval is. Dit artikel beschrijft eerst wat pseudonimiseren is en wat het verschil is met anonimiseren. Daarna komen aan de hand van twee cases de mogelijkheden en beperkingen van pseudonimiseren aan de orde. Tot slot worden enkele veelbelovende ontwikkelingen op het gebied van privacybeschermende maatregelen besproken.
Achtergrond en ontstaansgeschiedenis
Mede gedreven door de AVG heeft pseudonimisering als beveiligingsmaatregel voor het beschermen van persoonsgegevens de afgelopen jaren een grote vlucht genomen. Wereldwijd is een toenemend aantal aanbieders actief, bijvoorbeeld Privacy Analytics (Canada) en Custodix (België), die oplossingen aanbieden voor het pseudonimiseren van privacygevoelige gegevens. Recent heeft ook Google de bèta voor een Cloud Healthcare API for de-identifying sensitive data ([Goog]) gelanceerd. Ook in Nederland zijn meerdere dienstverleners actief, waaronder ZorgTTP en Viacryp. Daarnaast is er een toenemend aantal publicaties zoals [ENIS19] waarin best practices voor de technische opzet en mogelijke toepassingsgebieden worden beschreven. De overheid heeft in het kader van het eID-stelsel en de Wet digitale overheid ([Over]) die medio 2020 in werking zal treden, in het rijbewijs een voorziening opgenomen ([Verh19b]) voor het verstrekken van gegevens op basis van polymorfe pseudoniemen ([Verh19a]). Kenmerkend voor deze vorm van pseudonimiseren is dat iedere afnemer een ander pseudoniem krijgt voor dezelfde natuurlijke persoon. De kans op het doorbreken van de pseudonimisering wordt hiermee sterk beperkt. Pseudonimiseren is daarmee uitgegroeid van een specialistische en exotische toepassing naar een steeds breder beschikbaar en in toenemende mate gestandaardiseerd beveiligingsinstrument.
Wat zegt de AVG over pseudonimiseren?
Voordat we naar de techniek, praktijkvoorbeelden en ontwikkelingen op het gebied van pseudonimiseren kijken, is het van belang de juridische verankering te verkennen.
Pseudonieme gegevens zijn tot de persoon herleidbaar. De AVG en ook de voormalige EU-werkgroep 29 (thans European Data Protection Board) beschouwen pseudonieme gegevens als tot de persoon herleidbare gegevens ([EC14]). Deze vaststelling is van belang omdat nog wel eens wordt gesteld dat gepseudonimiseerde gegevens niet herleidbaar zijn. EU-werkgroep 29 stelt in dit kader echter dat pseudonieme gegevens als zodanig niet als anonieme gegevens kunnen worden gezien. De inzet van aanvullende maatregelen is vereist om met name de indirecte herleidbaarheid tot natuurlijke personen uit te sluiten. Daarmee moeten gepseudonimiseerde gegevens worden beschouwd als identificerende of identificeerbare gegevens waarop de AVG van toepassing is.
De AVG definieert pseudonimisering in artikel 4 lid 5 ([EU16b]) als:
het verwerken van persoonsgegevens op zodanige wijze dat de persoonsgegevens niet meer aan een specifieke betrokkene kunnen worden gekoppeld zonder dat er aanvullende gegevens worden gebruikt, mits deze aanvullende gegevens apart worden bewaard en technische en organisatorische maatregelen worden genomen om ervoor te zorgen dat de persoonsgegevens niet aan een geïdentificeerde of identificeerbare natuurlijke persoon worden gekoppeld;
Uit deze definitie blijkt dat in een pseudonieme dataset:
- persoonsgegevens niet meer aan specifieke betrokkenen kunnen worden gekoppeld zonder het gebruik van aanvullende gegevens;
- technische en organisatorische maatregelen vereist zijn om de herleidbaarheid van pseudonieme data naar identificeerbare of geïdentificeerde natuurlijke personen met aanvullende gegevens te voorkomen.
Met andere woorden, eerst moet bij het genereren van de pseudoniemen de link tussen de identificerende gegevens behorende bij een natuurlijke persoon en de daarvan afgeleide pseudonieme gegevens worden doorbroken. Dat kan al met het in bewaring geven van een eenvoudig sleutelbestand bij een ander, maar doorgaans wordt hier gebruikgemaakt van cryptografische algoritmes. Vervolgens moet worden voorkomen dat ongeautoriseerde herleiding plaats kan vinden door verrijking van de gepseudonimiseerde gegevens met aanvullende gegevens. De aanvullende maatregelen zijn daarbij in het algemeen gericht op het voorkomen van ongeautoriseerde toegang tot en verspreiding van de data. In een goede pseudonimiseringsoplossing moet zowel het genereren van pseudoniemen als het verrijken van gepseudonimiseerde data afdoende zijn geadresseerd.
DPIA als startpunt voor het inrichten van een pseudonimiseringsoplossing
Aan de eisen die de AVG stelt aan het pseudonimiseren van gegevensverwerkingen kan op meerdere manieren worden voldaan. Van geval tot geval moet worden beoordeeld welke combinatie van maatregelen als passend kan worden beschouwd ([EC14]). De vraag of het bijvoorbeeld mogelijk moet zijn om terug te kunnen naar de identificerende gegevens of juist niet, is een vraag die in dit kader gesteld moet worden. De beoordeling kan het beste worden gedaan in de vorm van een gegevensbeschermingeffectbeoordeling, of Data Protection Impact Assessment (DPIA), zoals vereist in artikel 35 van de AVG ([EU16b]). Op basis van de verwerkingsgrondslag, de aard van de verwerking en de daaraan verbonden risico’s, kan de afweging worden gemaakt tussen het beoogde detail van de te verwerken gegevens, de impact op de persoonlijke levenssfeer van betrokkenen en de maatregelen om de risico’s te mitigeren.
Wat levert pseudonimiseren op?
AVG-overweging 28 stelt dat de toepassing van pseudonimisering op persoonsgegevens de risico’s voor de betrokkenen kan verminderen en de verwerkingsverantwoordelijke en verwerkers kan helpen om hun verplichtingen inzake gegevensbescherming na te komen. Het gaat daarbij echter met name om het verminderen van de directe herleidbaarheid.
Indirecte herleidbaarheid
Ten aanzien van de mate waarin de gegevens na pseudonimisering indirect herleidbaar zijn, wordt in de opinie over anonimiseringstechnieken ([EC14]) gesteld dat moet worden nagegaan in hoeverre herleiding door herleidbaarheid (singling-out), koppelbaarheid (linkability) en deduceerbaarheid (inference) van de gegevens redelijkerwijs kan worden uitgesloten. Daar wordt nadrukkelijk gesteld dat pseudonimisering als zodanig voor geen van deze criteria indirecte herleiding uitsluit.
Wat zegt de toezichthouder over pseudonimiseren?
Reeds ver voor de publicatie van de opinie van [EC14] en de invoering van de AVG heeft het College bescherming persoonsgegevens (CBP) nagedacht over pseudonimiseren en de mate waarin dit leidt tot het beperken van de herleidbaarheid. De voorwaarden die het CBP voor pseudonimiseren heeft geformuleerd ([CBP07]), hielden reeds rekening met zowel de directe als indirecte herleidbaarheid van de gepseudonimiseerde gegevens. Het CBP stelde dat:
Bij toepassing van pseudonimisering is geen sprake van verwerking van persoonsgegevens, indien aan de volgende voorwaarden is voldaan:
- er wordt (vakkundig) gebruik gemaakt van pseudonimisering, waarbij de eerste encryptie plaatsvindt bij de aanbieder van de gegevens;
- er zijn technische en organisatorische maatregelen genomen om herhaalbaarheid van de versleuteling (“replay attack”) te voorkomen;
- de verwerkte gegevens zijn niet indirect identificerend, en
- in een onafhankelijk deskundig oordeel (audit) wordt vooraf en daarna periodiek vastgesteld dat aan de voorwaarden a, b en c is voldaan.
Eén van de uitgangspunten is voorts dat de pseudonimiseringsoplossing op heldere en volledige wijze dient te worden beschreven in een actief openbaar gemaakt document zodat iedere betrokkene kan nagaan welke garanties de gekozen oplossing biedt.
Gelden deze eisen nog onder de AVG?
In de achterliggende periode is meermaals gebleken dat bij pseudonimisering de uitdaging niet zozeer ligt bij de initiële inrichting van gegevensverwerking, maar bij de governance over een langere periode. Het blijkt in de praktijk een uitdaging voor organisaties om bij het toevoegen van nieuwe variabelen (datapunten) opnieuw de herleidbaarheid van de dataset te onderzoeken. Voorbeelden hiervan zijn de Diagnose Behandel Combinatie Informatiesysteem (DIS)-verwerking van de Nederlandse Zorgautoriteit ([AP16]) en de Routine Outcome Measurement (ROM)-verwerking door Stichting Benchmark GGZ (SBG) ([AP19b]). In beide gevallen bleek door uitbreidingen van de dataset in de loop van de tijd de indirecte herleidbaarheid van de gegevens zodanig toegenomen dat niet langer kon worden gesproken van redelijkerwijs niet-herleidbare gegevens.
Deze uitspraken impliceren niet zozeer het intrekken van de eerdere eisen voor pseudonimisering, maar vormen veel meer de bevestiging dat pseudonimisering als zodanig niet tot een anonieme dataset leidt zoals gesteld in opinie [EC14]. Het criterium om vast te stellen of sprake is van het verwerken van tot de persoon herleidbare gegevens, is in de AVG niet wezenlijk anders dan in de Wet bescherming persoonsgegevens (WBP). Nog steeds moet worden nagegaan of het, rekening houdend met de benodigde moeite en beschikbare middelen, redelijkerwijs (on)mogelijk is om gegevens te herleiden naar een natuurlijke persoon. Dat staat los van het al dan niet pseudonimiseren van de gegevens. In die zin blijven de eisen een bruikbaar uitgangspunt om na te gaan of sprake is van een verwerking binnen of buiten het kader van de AVG. Daarnaast kunnen de eisen helpen bij het beoordelen van toepassingen van pseudonimisering. Daarbij is de beoordeling niet gericht op het vaststellen of sprake is van het uitsluiten van herleidbaarheid, maar gericht op het tot een acceptabel niveau reduceren van de herleidbaarheid binnen een verwerking met privacygevoelige gegevens. Voor reductie van het risico is immers aandacht voor het beperken van zowel de directe als de indirecte herleidbaarheid noodzakelijk.
De relatie tussen pseudonimiseren en anonimiseren
Zoals in de vorige paragraaf is toegelicht, leidt pseudonimiseren als zodanig niet tot anonieme data. Pseudonimiseren is een van de mogelijke maatregelen gericht op het beperken van herleidbaarheid. In samenhang toegepast leiden deze mogelijk tot anonieme data. Die anonimiteit komt echter wel met een prijs: verlies aan onderscheidend vermogen in de dataset vanuit het perspectief van de gebruiker. In de HIPAA Safe Harbour-richtlijn voor het de-identificeren van medische gegevens wordt gesteld dat de-identificatie ten koste gaat van de bruikbaarheid van de data.
Volgens [Bart14] is hier sprake van de ‘Inconvenient Truth’ (zie figuur 1) dat het bereiken van de ideale situatie met optimale privacybescherming enerzijds en optimale waarde van de data anderzijds onmogelijk is. Bij het toepassen van technieken voor de-identificatie moet daarom steeds de afweging worden gemaakt tussen het beoogde gebruik en de kwaliteit van de informatie enerzijds en de privacybescherming anderzijds. Die afweging kan leiden tot een positionering van de verwerking binnen dan wel buiten de AVG. Zo kan de wens bestaan om productiedata met persoonsgegevens voor testdoeleinden te gebruiken wegens de representativiteit van de dataset. Als hiervoor echter geen toestemming van de betrokkenen of een andere AVG/grondslag voorhanden is, dan moeten de data geanonimiseerd worden. Het anonimiseren gaat echter ten koste van de representativiteit. Mogelijk kunnen niet alle testcases worden uitgevoerd, bijvoorbeeld omdat de postcode is geaggregeerd naar een regiocode of omdat de geboortedatum is omgezet naar een leeftijdsklasse. Daarnaast bestaat het risico dat de getroffen maatregelen de indirecte herleidbaarheid in onvoldoende mate beperken waardoor de testdata toch als herleidbaar worden gezien.
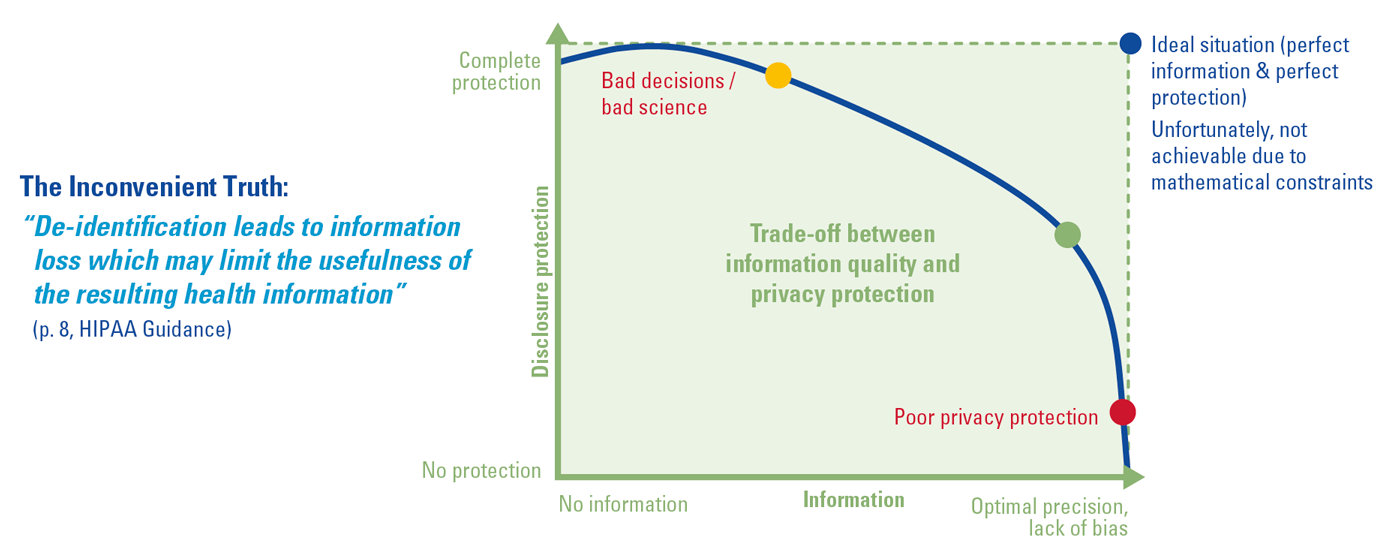
Figuur 1. Weging privacybescherming en datakwaliteit ([Bart14]). [Klik op de afbeelding voor een grotere afbeelding]
Zijn anonieme data eigenlijk nog wel haalbaar?
Uit het voorgaande blijkt dat de lat voor anonimiteit in de praktijk zodanig hoog ligt dat de mogelijkheid om individuen te onderscheiden in een dataset, gelijk wordt gesteld aan herleidbaarheid van de gegevens.
- Een toenemend aantal publicaties bewijst dat de ideale situatie uit figuur 1 niet haalbaar is. Keer op keer blijkt het mogelijk om individuen in schijnbaar geanonimiseerde datasets te herleiden door de datasets te verrijken met aanvullende gegevens. Aansprekende voorbeelden hiervan zijn studies zoals die naar het herleiden van de Netflix-prijsdataset met openbare censusdata ([Nara08]) en het promotieonderzoek van [Koot12] waar in de Nederlandse context schijnbaar niet-herleidbare medische data door verrijking met openbare CBS-data konden worden herleid. Recente publicaties als die van [Mour18] en [Roch19] tonen aan dat door de toename van openbaar beschikbare data, kennis en technische middelen steeds minder datapunten uit de geanonimiseerde set benodigd zijn om individuen te herleiden. Volgens [Cala19] kan alleen al het (unieke) patroon van aan een persoon gekoppelde datapunten leiden tot herleiding.
- De Autoriteit Persoonsgegevens (AP) vereist inmiddels dat verwerkingsverantwoordelijken en verwerkers aantoonbaar, juist en actief geavanceerde privacybeschermende technieken als K-anonymity ([Swee02]) toepassen ([AP19b]). Herleidbaarheid dient daarbij eerder absoluut dan redelijkerwijs uitgesloten te worden op basis van de criteria van herleidbaarheid, koppelbaarheid en deduceerbaarheid conform [EC14]. In beslissing op bezwaar [AP19a] tegen de eerder in dit artikel genoemde SBG-uitspraak geeft de AP aan dat een vergelijking met het Breyer-arrest ([EU16a]), waarin een minder absolute maatstaf voor niet-herleidbaarheid wordt voorgestaan, niet opgaat voor datasets waar een groot aantal andere datapunten is gekoppeld aan de pseudoniemen.
Voorbeeld van anonieme data
Ondanks dat het steeds lastiger blijkt om data te anonimiseren, zijn er wel voorbeelden te noemen van het verwerken van anonieme data. Zo is het Centraal Bureau voor de Statistiek (CBS) in de Wet op het Centraal bureau voor de statistiek ([Over03]) aangewezen als organisatie voor het produceren van statistieken voor beleid en onderzoek en kan het CBS in Nederland als maatgevend worden gezien als het gaat om het toepassen van technieken voor het anonimiseren van gegevens. Daarvoor wordt in Europees verband met zusterorganisaties ontwikkelde programmatuur voor Statistical Disclosure Control (SDC) zoals µ-argus en Tau-argus ingezet ([CBS20]). Met deze programma’s kan de mate van herleidbaarheid in te publiceren datasets worden beperkt tot een aanvaardbaar minimum. De inzet van deze programmatuur is echter niet triviaal. Statistische kennis en specifieke training voor gebruik van de software zijn vereist.
Pseudonimiseren: techniek en modellen
Nu de relatie tussen anonimiseren en pseudonimiseren duidelijk is geworden, wordt hierna een voorbeeld gegeven van pseudonimisering in Nederland. Daarvoor is het van belang kort stil te staan bij de techniek en de operating models. Pseudonimisering kan in verschillende vormen worden toegepast. Ga voor de keuze voor de specifieke uitwerking na of deze:
- een open of gesloten karakter moet hebben;
- omkeerbaar of onomkeerbaar moet zijn;
- een eenmalige of structurele omzetting van gegevens vereist;
- voor één specifieke of voor meerdere organisaties zal worden toegepast;
- de mogelijkheid voor omzettingen tussen gescheiden pseudonieme deelverzamelingen vereist (bijvoorbeeld bij multicenterstudies);
- in eigen beheer of met hulp van een externe dienstverlener moet worden uitgevoerd.
De uitkomst van deze afweging kan van geval tot geval verschillen en kan leiden tot de inzet van verschillende technieken. Het voornaamste doel van iedere oplossing moet het voorkomen van het ongeautoriseerd doorbreken van de pseudonimisering zijn. Bepalend voor een goede uitwerking van dat doel is de wijze waarop (cryptografisch) sleutelmanagement en functiescheiding zijn georganiseerd. De functiescheiding moet daarbij zodanig zijn ingericht dat wordt afgedwongen dat iedere actor de beschikking heeft over slechts een van de volgende elementen:
- de identificerende data (ID-data in figuur 2);
- het cryptografische sleutelmateriaal;
- de gepseudonimiseerde data.
Alleen als een afdoende scheiding is aangebracht tussen deze elementen, kan het ongeautoriseerd doorbreken van de pseudonimisering effectief worden voorkomen.
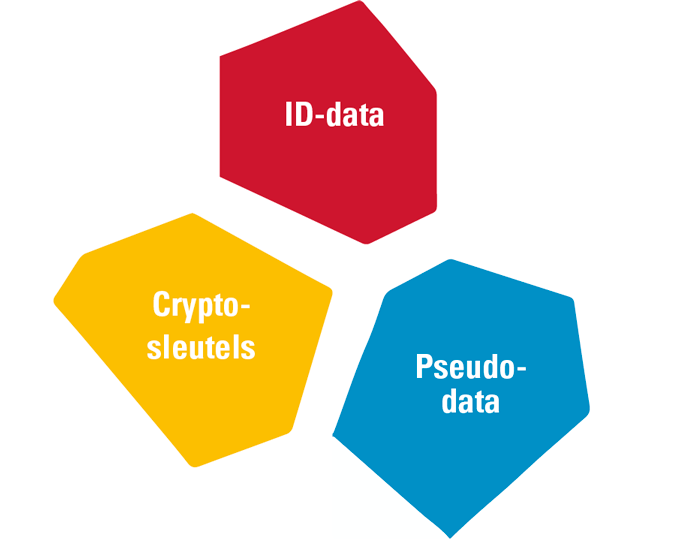
Figuur 2. Functiescheiding. [Klik op de afbeelding voor een grotere afbeelding]
Normen en praktijkrichtlijnen
Lange tijd was ‘ISO 25237 – pseudononimisatietechnieken’ een van de weinige normen op het gebied van pseudonimiseren. Inmiddels zijn de ‘NEN 7524 – pseudonimisatiedienstverlening’ en ‘ISO 20889 – de-identification techniques’ beschikbaar. Daarnaast verschijnen er steeds meer guidelines zoals die van ENISA ([ENIS19]) en de Personal Data Protection Commission Singapore ([PDPC18]). Ook sectorspecifiek zijn er richtlijnen voor praktische toepassing van de-identificatie, zoals het IHE Handbook De-identification ([IHE14]). Daarmee wordt het steeds beter haalbaar voor organisaties om een goede oplossing in te richten.
Case: pseudonimisering voor de risicoverevening
Zorgverzekeraars hebben de opdracht om te concurreren op prijs en kwaliteit. Wegens de in Nederland geldende acceptatieplicht is de verwachte schadelast per verzekeraar niet gelijk. Het Zorginstituut berekent daarom jaarlijks per zorgverzekeraar de vereveningsbijdrage per zorgverzekeraar op basis van de Regeling Risicoverevening ([Over18]) bij de Zorgverzekeringswet. Daarmee worden verzekeraars gecompenseerd voor onevenredige schadelast in de verzekerdenpopulatie en wordt een ‘level playing field’ gecreëerd waarbinnen de verzekeraars met elkaar kunnen concurreren. Om deze berekening te kunnen uitvoeren is een grote hoeveelheid (gevoelige) gegevens benodigd. Figuur 3 geeft een overzicht van de organisaties die een rol hebben bij de gegevensverwerking in het kader van de risicoverevening. Jaarlijks worden honderden miljoenen datarecords verwerkt binnen het stelsel. De verwerking kent een grondslag in de Zorgverzekeringswet. Hierin is expliciet opgenomen dat voor het doel van de risicoverevening de verwerking van medische persoonsgegevens en het burgerservicenummer noodzakelijk is.
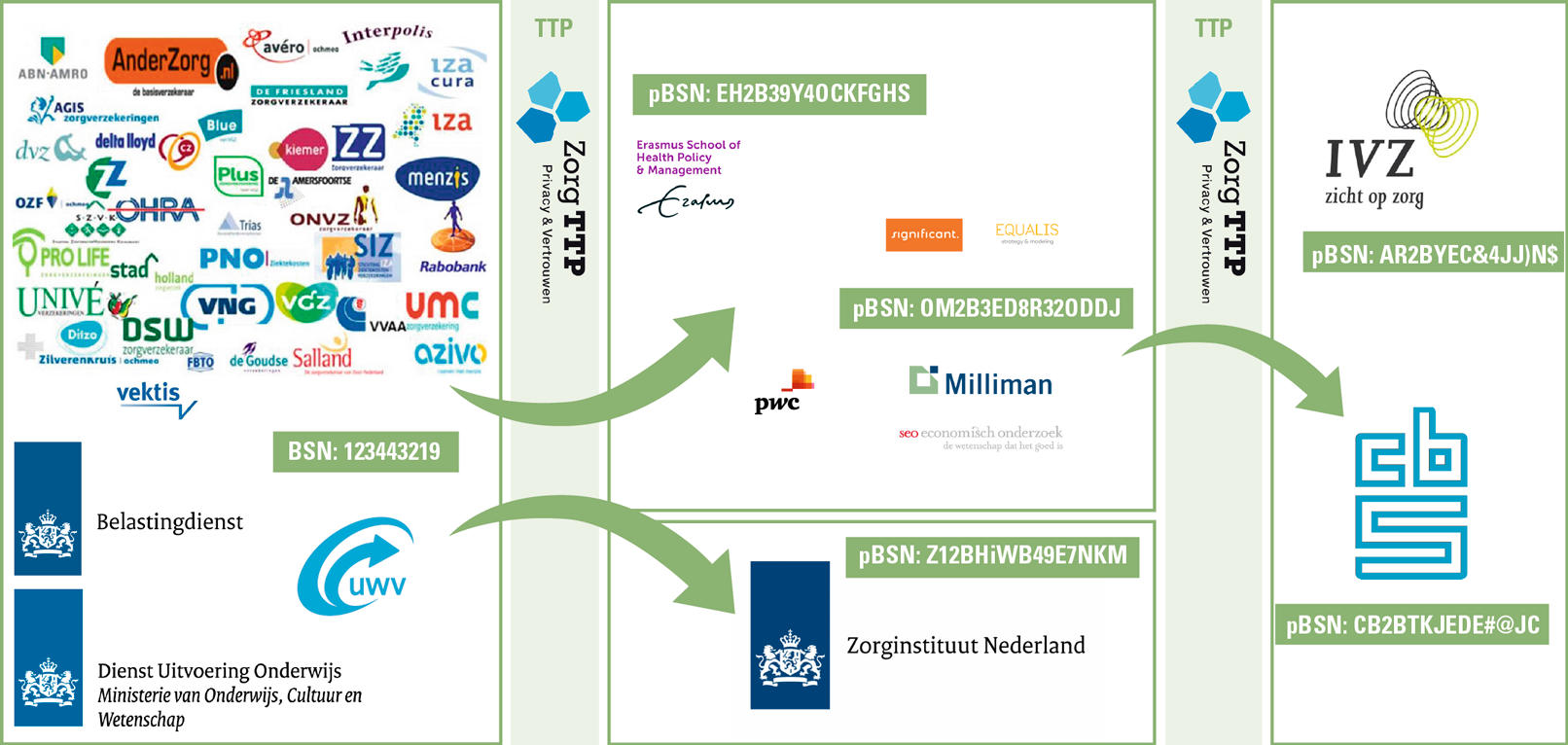
Figuur 3. Stelsel Risicoverevening. [Klik op de afbeelding voor een grotere afbeelding]
Aan de linkerzijde staan de organisaties die input leveren voor het vereveningsmodel. Via pseudonimiseringssoftware worden jaarlijks gegevens aangeleverd aan enerzijds het Zorginstituut voor het berekenen van de vereveningsbijdrage; anderzijds worden gegevens geleverd aan jaarlijks te contracteren onderzoeksbureaus die in opdracht van het ministerie van Volksgezondheid, Welzijn en Sport belast zijn met onderhoud en doorontwikkeling van het vereveningsmodel. Na gebruik van de data worden deze eerst in een kortetermijnarchief geplaatst. Tot slot wordt het CBS voorzien van de data voor statistische doeleinden. De groene vlakken laten zien hoe een burgerservicenummer (BSN) wordt omgezet naar verschillende pseudoniemen voor verschillende afnemers.
Omdat het College Bescherming Persoonsgegevens ([CBP07]) de gegevensverwerking als een van de meest gevoelige verwerkingen in Nederland heeft bestempeld, zijn uitgebreide maatregelen getroffen om de persoonlijke levenssfeer van de betrokkenen te beschermen. Naast onomkeerbare pseudonimisering van de direct identificerende gegevens wordt voor de indirect herleidbare gegevens generalisatie toegepast in de vorm van aggregatie en het coderen van gegevens naar klassen. Figuur 4 beschrijft de functionele keten waarlangs gegevens gepseudonimiseerd worden. Een lokale pseudonimiseringsmodule leest het aangeboden bronbestand in en brengt na controle van de aangeboden gegevens eerst een scheiding aan tussen de direct en indirect identificerende gegevens. Op beide datadelen vindt vervolgens een bewerking plaats: respectievelijk pre-pseudonimisering en generalisatie. Het resulterende pseudo-ID en datadeel worden vervolgens voor definitieve pseudonimisering aangeboden aan de pseudonimiseringsdienstverlener. Deze dienstverlener fungeert als Trusted Third Party die uit oogpunt van de eerdergenoemde functiescheiding enkel toegang krijgt tot het pseudo-ID-deel. Het datadeel is door middel van PKI versleuteld voor de eindontvanger. Na definitieve pseudonimisering worden beide delen via een ontvangstmodule opgehaald door de eindontvanger. In de module worden de afzonderlijke delen samengevoegd, waarna het resultaatbestand wordt aangeboden. Het resultaat van deze operatie is een effectieve doorbreking van de relatie tussen brongegeven en gepseudonimiseerd afgeleide. Geen van de partijen kan zonder samen te spannen met een van de andere partijen de keten doorbreken.
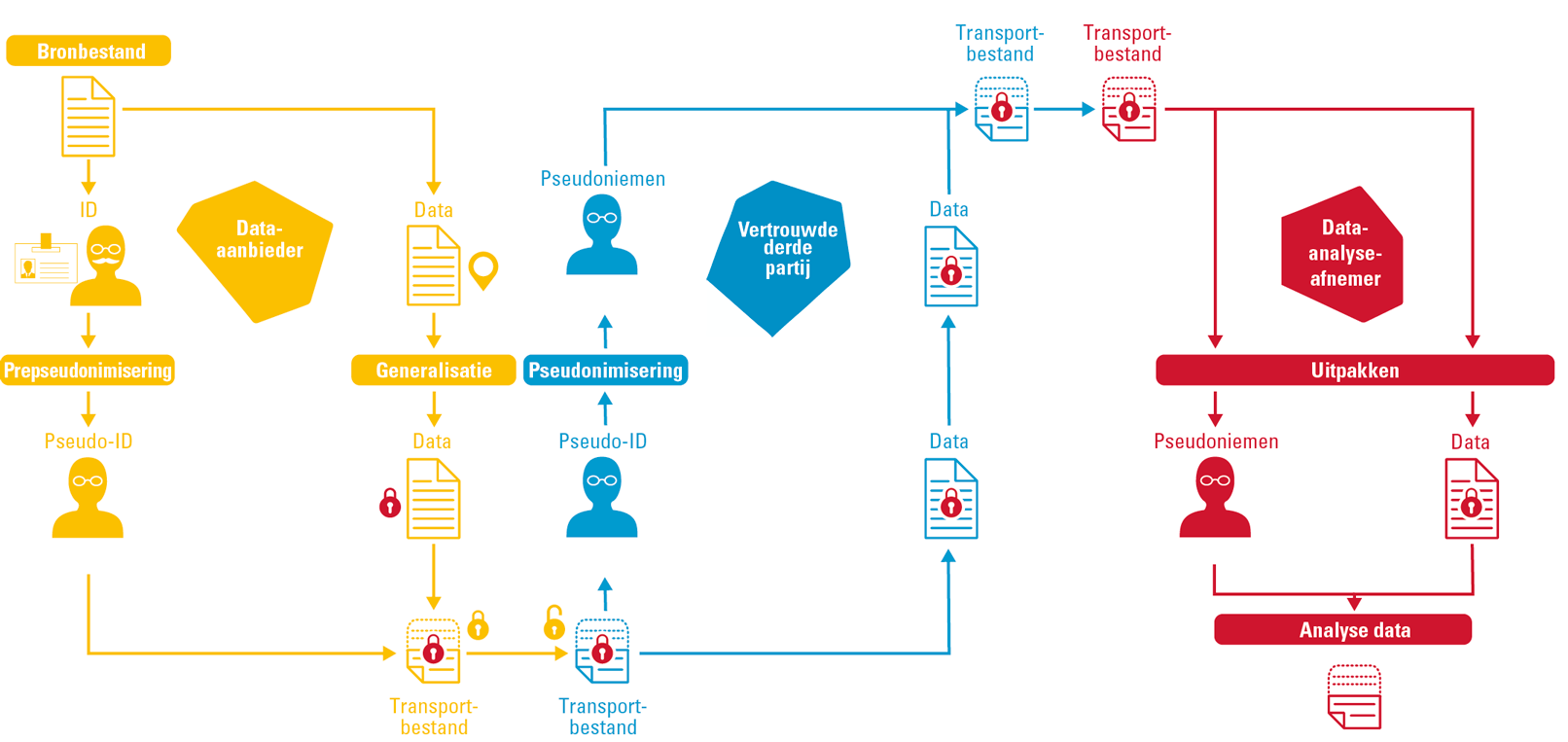
Figuur 4. Operating model voor onomkeerbare pseudonimisering. [Klik op de afbeelding voor een grotere afbeelding]
Governance
De grootste succesfactor van de pseudonimisering voor de risicoverevening is dat regelmatig aandacht aan wordt gegeven aan zowel de technische als de organisatorische maatregelen. De methodebeschrijving van het pseudonimiseringsalgoritme is openbaar en voorziet in functies op het gebied van sleutelbeheer waarmee sleutels en toegepaste encryptiestandaarden kunnen worden vervangen. Ook interoperabiliteit is in de methode belegd, waardoor het mogelijk is om gegevens over te dragen aan andere aanbieders die de methode ondersteunen. Om ervoor te zorgen dat de data alleen voor legitieme doelen door daartoe geautoriseerde gebruikers toegankelijk zijn, heeft het ministerie een beleid voor datagovernance ontwikkeld. Het beleid voorziet in maatregelen en afspraken met betrekking tot opslag, transport, toegang en verspreiding van de data en wordt jaarlijks geëvalueerd. Daarbij wordt voor alle transacties in het stelsel vastgesteld of er wijzigingen in de specificaties zijn en of deze impact hebben op de herleidbaarheid van de data.
Ontwikkelingen
Er is een aantal veelbelovende ontwikkelingen gaande met de belofte om het gebruik van gevoelige gegevens op grote schaal te verenigen met een privacyvriendelijke opzet.
Synthetische data
Bij synthetische data wordt een afgeleide gemaakt van een (real-world) dataset met behoud van statistische eigenschappen. Het voordeel is dat er geen sprake is van herleidbaarheid naar individuen in de set omdat er een compleet nieuwe dataset wordt gegenereerd met fictieve personen in plaats van een afgeleide van de oorspronkelijke set. Het nadeel is echter dat de techniek nog voornamelijk in de context van wetenschappelijk onderzoek wordt toegepast, nog niet volwassen is en niet op alle vragen past. Extreme waarden in de dataset (uitbijters) kunnen bijvoorbeeld verloren gaan. Bij fraudedetectie wil je die juist zien. Voor het genereren van representatieve synthetische data is een real-world tegenhanger nodig waarop het algoritme dat de synthetische data moet genereren, wordt getraind. Het risico op herleidbaarheid van deze oorspronkelijke set door verspreiding en ongeautoriseerde verrijking van de data kan wel worden ondervangen door een synthetische set openbaar te maken. Het samenstellen van het origineel en/of de trainingsset uit diverse databronnen zou bij een Trusted Third Party kunnen worden belegd. Die rol kan in de praktijk belegd worden bij organisaties als het CBS, maar ook bij private partijen.
Secure Multi Party Computation
Secure Multi Party Computation is een verzameling technieken waarmee data afkomstig uit verschillende bronnen in geëncrypteerde vorm kunnen worden samengevoegd en bewerkt. Alleen het resultaat op populatieniveau wordt opgeslagen in de vorm van bijvoorbeeld regressiecoëfficiënten. Er ontstaat geen permanente samengevoegde dataset. De samengevoegde set wordt met de techniek van Shamir secret-sharing opgebouwd bij een Trusted Third Party die verwerkersovereenkomsten heeft gesloten met de aanleverende databronnen. Omdat de samengevoegde set alleen tijdelijk, in memory en bovendien in versleutelde vorm leeft, is geen sprake van gebruik van herleidbare data buiten het mandaat waarmee deze verzameld zijn. Er is sprake van verenigbaar gebruik.
Conclusie
Pseudonimiseren als zodanig leidt niet tot anonieme data. Organisaties moeten zich afvragen in hoeverre de heilige graal van anonieme én tegelijk betekenisvolle data haalbaar is. De lat voor anonimiteit ligt hoog. Herleidbaarheid dient absoluut uitgesloten te worden op basis van de criteria van herleidbaarheid, koppelbaarheid en deduceerbaarheid. In de praktijk moet een afweging worden gemaakt tussen privacybescherming en het beoogde gebruik van de data. Dat maakt dat verwerkingen binnen de kaders van de AVG moeten opereren. Pseudonimiseren kan daarbij een krachtig middel zijn om het risico op herleidbaarheid binnen een dataset te verminderen. De verwerkingsverantwoordelijke en verwerker(s) kunnen daarmee aantoonbaar voldoen aan de vereiste om passende technische en organisatorische maatregelen toe te passen.
Er is een toenemend aantal normen en richtlijnen beschikbaar voor het pseudonimiseren van gegevens. Deze kunnen helpen om tot een robuuste opzet te komen van pseudonimisering binnen een verwerking. De belangrijkste aspecten die belegd moeten worden, zijn functiescheiding, cryptografisch sleutelmanagement en het op transparante wijze beschrijven van het gevolgde proces en de daarbij geldende afspraken.
In Nederland is de risicoverevening een voorbeeld van het op grote schaal pseudonimiseren van gevoelige gegevens in een stelsel waarbij veel actoren zijn betrokken. De overheid werkt ondertussen aan opschaling in het kader van eID en de Wet digitale overheid.
Secure Multi Party Computation en synthetische data zijn technieken in ontwikkeling die een waardevolle toevoeging lijken te bieden in de continue afweging tussen het beoogde gebruik van data en het beschermen van de persoonlijke levenssfeer van hen op wie de data betrekking hebben.
Literatuur
[AP16] Autoriteit Persoonsgegevens (2016). AP: NZa mag diagnosegegevens uit DIS beperkt verstrekken. Geraadpleegd op: https://autoriteitpersoonsgegevens.nl/nl/nieuws/ap-nza-mag-diagnosegegevens-uit-dis-beperkt-verstrekken
[AP19a] Autoriteit Persoonsgegevens (2019). Beslissing op bezwaar. Geraadpleegd op: https://autoriteitpersoonsgegevens.nl/sites/default/files/atoms/files/beslissing_op_bezwaar_sbg.pdf
[AP19b] Autoriteit Persoonsgegevens (2019). Rapport naar aanleiding van onderzoek gegevensverwerking SBG. Geraadpleegd op: https://www.autoriteitpersoonsgegevens.nl/sites/default/files/atoms/files/rapport_bevindingen_sbg_en_akwa_ggz.pdf
[Bart14] Barth Jones, B. & Janisse, J. (2014). Challenges Associated with Data-Sharing: HIPAA De-identification. Geraadpleegd op: http://nationalacademies.org/hmd/~/media/Files/Activity%20Files/Environment/EnvironmentalHealthRT/2014-03/Daniel-Barth-Jones_March2014.pdf
[Cala19] Calacci, D. et al. (2019). The tradeoff between the utility and risk of location data and implications for public good. Geraadpleegd op: https://arxiv.org/pdf/1905.09350.pdf
[CBP07] College bescherming persoonsgegevens (2007). Pseudonimisering risicoverevening. Geraadpleegd op: https://autoriteitpersoonsgegevens.nl/sites/default/files/atoms/files/advies_pseudonimisering_risicoverevening.pdf
[CBS20] Centraal Bureau voor de Statistiek (2020). About sdcTools: Tools for Statistical Disclosure Control. Geraadpleegd op: https://joinup.ec.europa.eu/solution/sdctools-tools-statistical-disclosure-control/about
[EC14] European Commission: Article 29 Data Protection Working Party (2014). Opinion 05/2014 on Anonymisation Techniques. Brussel: WP29. Geraadpleegd op: https://ec.europa.eu/justice/article-29/documentation/opinion-recommendation/files/2014/wp216_en.pdf
[ENIS19] ENISA (2019). Pseudonymisation techniques and best practices, Recommendations on shaping technology according to data protection and privacy provisions.
[EU16a] Europese Unie (2016). Uitspraak HvJ EU: Patrick Breyert. Bundesrepublik Deutschland, C-582/14, 19 oktober 2016, ECLI:EU:C:2016:779.
[EU16b] Europese Unie (2016). Verordening (EU) 2016/679 betreffende de bescherming van natuurlijke personen in verband met de verwerking van persoonsgegevens en betreffende het vrije verkeer van die gegevens en tot intrekking van Richtlijn 95/46/EG (algemene verordening gegevensbescherming). Brussel. Geraadpleegd op: https://eur-lex.europa.eu/legal-content/NL/TXT/?uri=celex:32016R0679
[Goog] Google (z.j.). Cloud Healthcare API for de-identifying sensitive data. Geraadpleegd op https://cloud.google.com/healthcare/docs/how-tos/deidentify
[IHE14] IHE IT Infrastructure Technical Committee (2014). IHE IT Infrastructure Handbook De-Identification. Geraadpleegd op: https://www.ihe.net/uploadedFiles/Documents/ITI/IHE_ITI_Handbook_De-Identification_Rev1.1_2014-06-06.pdf
[Koot12] Koot, M.R. (2012). Concept of k-anonymity in PhD thesis “Measuring and predicting anonymity”. Geraadpleegd op: http://dare.uva.nl/document/2/107610
[Mour18] Mourby, M. et al. (2018). Are ‘pseudonymised’ data always personal data? Implications of the GDPR for administrative data research in the UK. Computer Law & Security Review, 34.
[Nara08] Narayanan, A. & Shmatikov, V. (2008). Robust de-anonymization of large sparse datasets. In: Proceedings of the 2008 IEEE Symposium on Security and Privacy (pp. 111-125). Washington, DC: IEEE Computer. Geraadpleegd op: https://www.cs.utexas.edu/~shmat/shmat_oak08netflix.pdf
[Over] Overheid.nl (z.j.). Wet digitale overheid. Geraadpleegd op: https://wetgevingskalender.overheid.nl/Regeling/WGK005654
[Over03] Overheid.nl (2003, 20 november). Wet op het Centraal bureau voor de statistiek. Geraadpleegd op 16 februari 2020 op: https://wetten.overheid.nl/BWBR0015926/2019-01-01
[Over18] Overheid.nl (2018, 24 september). Regeling Risicoverevening, Zorgverzekeringswet. Geraadpleegd op 16 februari 2020 op: https://wetten.overheid.nl/BWBR0041387/2018-09-30
[PDPC18] Personal Data Protection Commission Singapore (2018). Guide to Basic Data Anonymisation Techniques.
[Roch19] Rocher, L. et al. (2019). Estimating the success of re-identifications in incomplete datasets using generative models. Nature Communications, 10, 3069. Geraadpleegd op: https://doi.org/10.1038/s41467-019-10933-3
[Swee02] Sweeney, L. (2002). k-anonymity: a model for protecting privacy. International Journal on Uncertainty, Fuzziness and Knowledge-based Systems, 10(5), pp. 557-570.
[Verh19a] Verheul, E. (2019). The polymorphic eID scheme – combining federative authentication and privacy. Logius. Geraadpleegd op: http://www.cs.ru.nl/E.Verheul/papers/eID2.0/eID%20PEP%201.29.pdf
[Verh19b] Verheul, E. (2019). Toepassing privacy enhancing technology in het Nederlandse eID. IB Magazine, 6, 2019. Geraadpleegd op: http://www.cs.ru.nl/~E.Verheul/papers/PvIB2019/PvIG-IB6.pdf