





Increased global pressure on tax compliance is leading to a higher cost of compliance. The majority of the time and effort is spent on preparing data. Therefore, much is to be gained by applying progressive data management. For a global bank, KPMG has implemented a data management solution, the tax data factory, to automate and standardize this process. As a result, the tax compliance reporting was done quicker, with less effort and resulted in higher quality data.
Introduction
Tax compliance for any organization is critical. You need to show transparency when it comes to how the business operates by filling tax returns timely and accurately. Preparing these tax returns can be a costly and time-consuming process. Tax teams often have a short period of time to collect and assess a substantial amount of information. Especially for annual returns, often applicable for corporate taxes, this creates significant pressures for the finance and tax teams. Every decision and transaction in the past year might have an impact and needs to be reviewed with the latest local, and possibly foreign, tax laws in mind. And while this review is extremely important for the quality of the tax returns, there is a slightly hidden activity that receives more time and attention from the tax teams: collecting and preparing data.
Information required to populate a tax return comes from decisions and transactions from the entire organization. What was the total taxable profit? How much was spent on legal fees? This data is available, but it was never recorded with a tax purpose in mind. As a result, tax teams spend a huge amount of time and effort in 1) obtaining the right data, 2) reconciling and validating the quality of the data, and 3) ensuring that the data are sufficiently detailed and in a usable format.
In the past, organizations often overcame these data challenges through brute force. They assigned more people to address the problem or used an outsourcing model to move the issues outside of the organization. In a global tax benchmark conducted by KPMG, over 55% of the interviewed companies predicted an increase of their total tax head count as a result of this approach ([KPMG18]).
During the past years, we have seen organizations that adopt a different approach and address these data challenges by using automation and digital solutions. Especially in tax areas like indirect taxes, which traditionally use more transactional data, companies are investing in data technologies to support the tax teams ([Down15]).
More recently, we also see the same trend for corporate taxes. This is mainly driven by new taxes and reporting requirements, which arise from the digitization of the economy. Examples are the introduction of Digital Services Taxes (DST; e.g. Austria, United Kingdom, Turkey), BEPS 2.0 Pillar 1 and Foreign-Derived Intangible Income (FDII) in the US ([OECD20]). These new tax requirements require more and more detailed data for tax calculation. It is therefore a logical response that organizations also look at data technologies for corporate tax compliance. Using the right technology not only avoids peak periods for the tax teams, but it also saves costs, increases throughput time and can increase the quality of the returns.
Client study
To show how companies can benefit from data technology in the context of corporate tax compliance, we introduce a client case. Our client, a large international investment bank, has asked KPMG to support with its corporate income tax (CIT) compliance. In the Asia-Pacific region, this bank submits over 150 different CIT returns annually in 19 countries. The required data to prepare these returns is captured in a highly complex systems architecture spanning various accounting systems. This resulted in high costs of tax compliance. KPMG has supported this bank by lifting the burden from client’s tax teams and helping with efficient data collection, review and timely filing of the CIT returns.
The existing process of preparing tax data was highly manual, with divergent processes between different countries, and a lot of back-and-forth of information requests. Furthermore, the tax data was often received in an inconsistent format, in- or over-complete. As a result, the tax teams were often caught up in manual data activities and spent less time on value adding tax activities. We have estimated that the tax professionals were spending 80% of their time on the following activities:
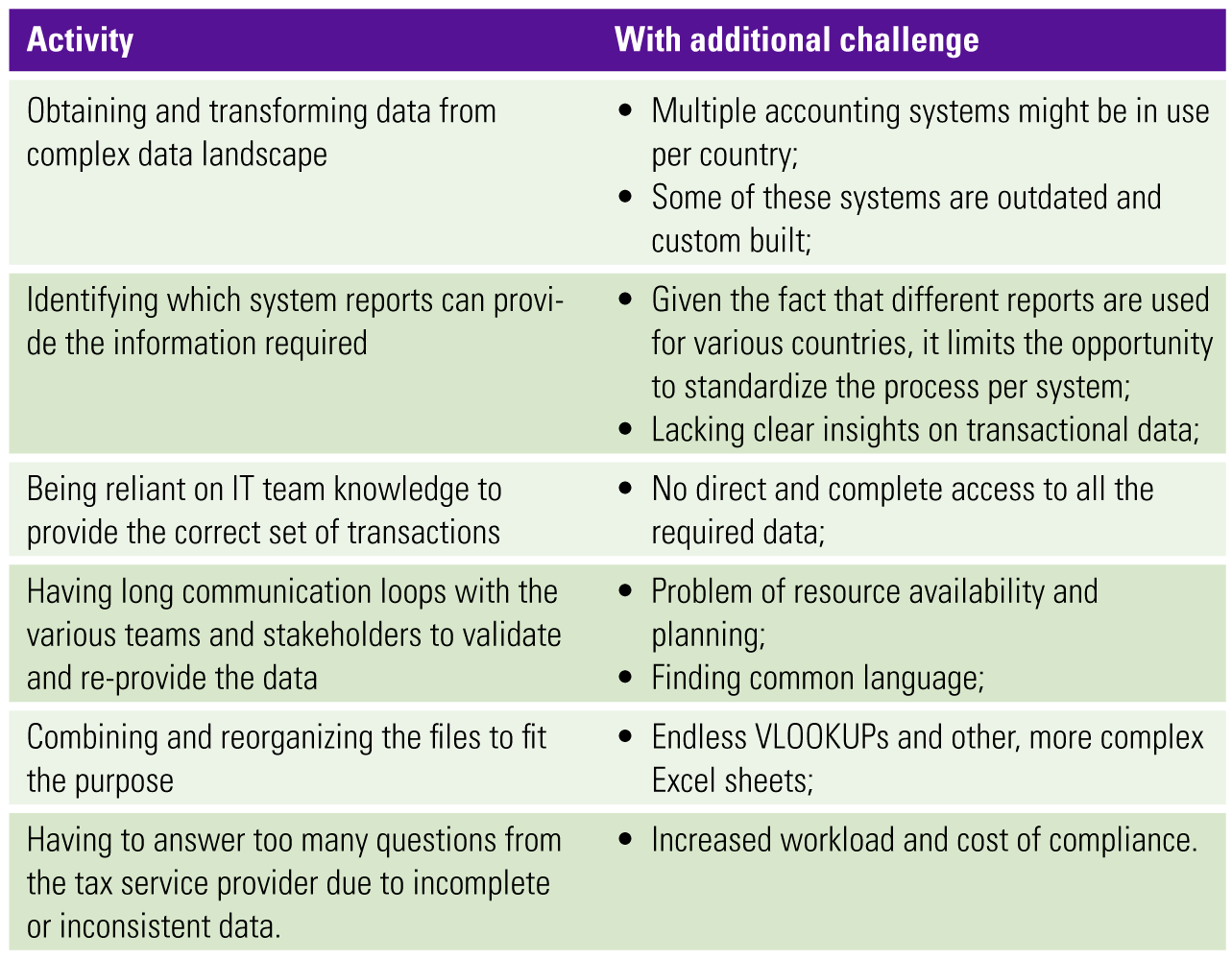
The underlying root-cause for this time dissipation results from poor tax data management. Tax data management refers to the strategy, technologies and available intelligent data models to extract, ingest, clean, transform, harmonize data from its source (where it’s created) all the way to data outputs which can feed directly into tax applications used by tax teams ([Zege21]).
A key element of the approach taken was to improve the tax data management by investing in modern tax technology solutions. This approach to future proof tax data management, also called KPMGs “Tax Data Factory”, is using a set of capabilities and methodologies designed to automate and standardize all activities to tax data. This ultimately leads to less time spent on non-value adding activities and increasing data quality.
Tax Data Factory approach
For this bank, as for most organizations, working with tax data is nothing new. However, their existing approach to tax data management was mainly using the most used tax technology solution globally: Microsoft Excel. When introducing the Tax Data Factory, we took a more holistic approach and matched it with technologies which are fit for purpose. The approach can be split into four successive parts:
- Understanding the data requirements
- Data collection and transmission
- Data validation and processing
- Delivery of country-specific data packages
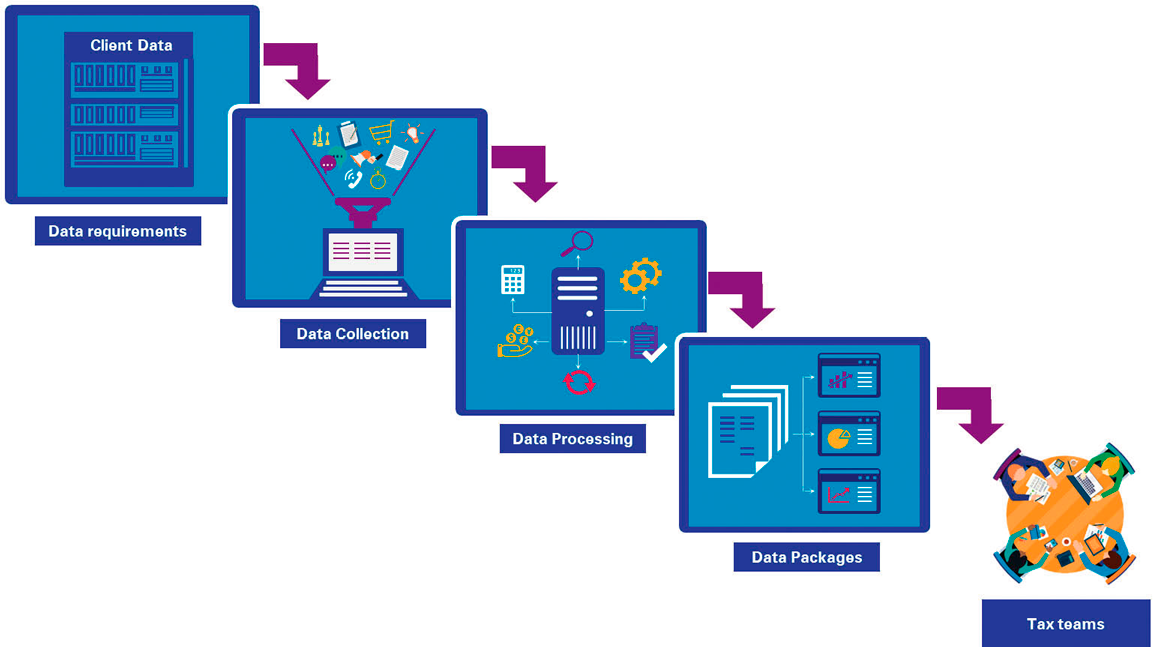
Figure 1. Data flow in the project. [Click on the image for a larger image]
Understanding the data requirements
Before being able to start building a data factory, it is important to understand the data requirements. Tax data management is all about retrieving data from the source and providing it to the tax team as efficiently as possible. First, it is important to understand the connection between data supply and data demand. This understanding comes from workshops with IT, tax department and KPMG teams. The goal of these workshops was to understand which information is required, which underlying data is needed and in which system this data is stored.
During this exploratory process, it became clear that operating in multiple jurisdictions contribute to the complexity. Different, often non-standard, reports are required in different countries and the underlying data comes from vastly different source systems. Although it is tempting to come up with tax solutions per country, it is important to look for the common denominator in the data. Eventually, the common elements will contribute to standardization and efficiency of the overall approach. Our team was able to define a common data structure that can facilitate the specific requirements for different countries, while being as generic as possible.
Data collection and transmission
Even when having a design for a common data structure, the required data is still spread across several different systems. In close collaboration with the IT team, agreements must be made about the collection and transmission of this data. This agreement contains topics such as the scope of data (which tables, columns, and filter to apply), timing (when to share the data), format (file format and naming convention of the files that are shared). Making solid agreements and documenting the details is crucial for having efficient tax data management processes.
Data validation and processing
The core of this data management approach is the Tax Data Factory. The Tax Data Factory is the technology that performs the data processing and transforms the source data to the final outputs, using the common data structure. For the bank, this was achieved by using the Microsoft Azure cloud and native Microsoft data technologies.
The Tax Data Factory uses a modular and flexible setup. The source data enters the data factory and flows through different levels as depicted in figure 2. These different levels, each with a distinct purpose, are connected with automated pipelines which transfers data from one level to the next. This entire process is coordinated by a central control room that orchestrates and monitors the data processing.
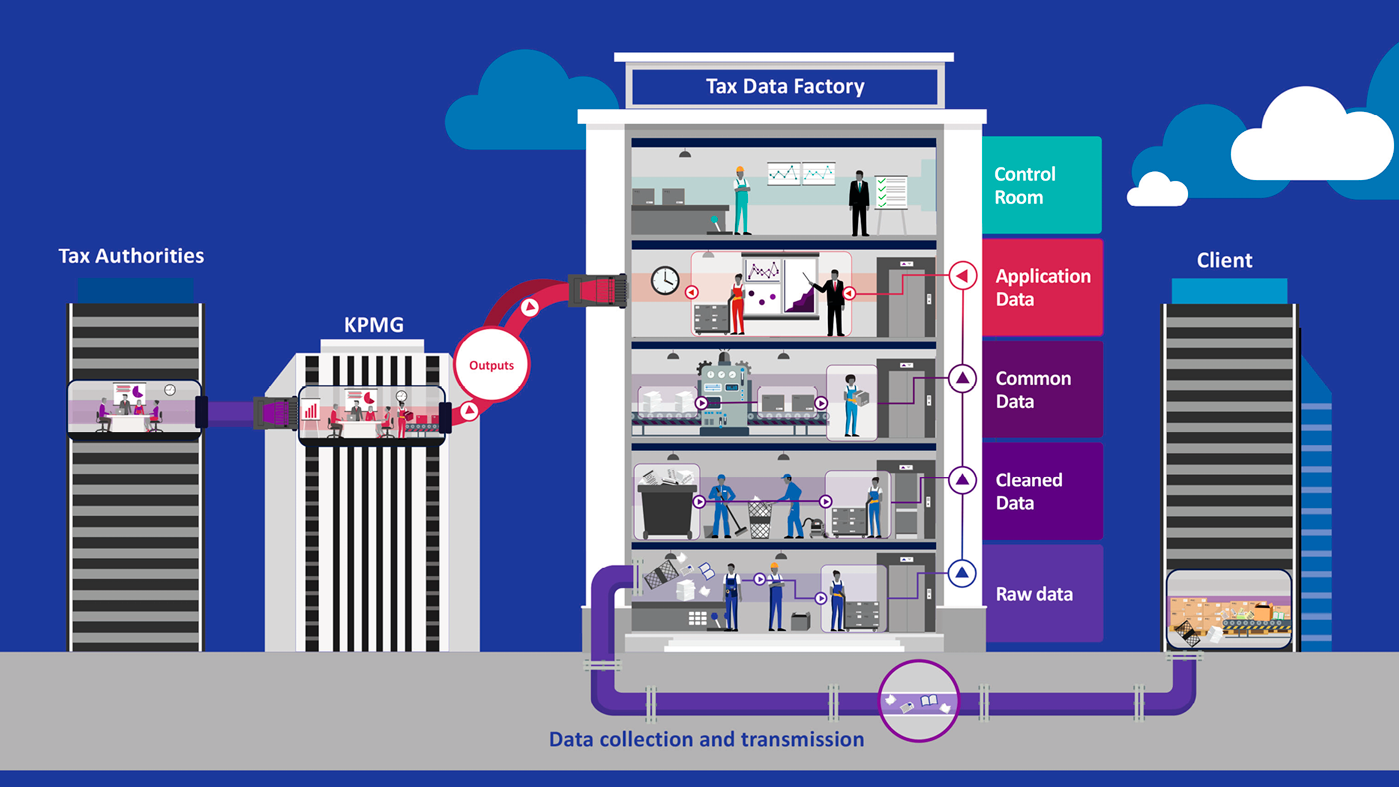
Figure 2. Tax Data Factory. [Click on the image for a larger image]
On the Raw Data level, source data is brought in directly from the bank and stored in the data factory. Initial validations are performed to ensure that the correct data (for example, the sum of general ledger transactions reconciles with the corresponding trial balance amount) is received.
Since not all data is received in a format which is fully ready for processing, some cleaning steps are performed before data ends up on the Cleaned data level. These cleaning steps such as removing empty lines, handling of row counts and formatting, are generically designed such that they can be reused for data from different systems.
As data originates from different systems, the data needs to be transformed before it fits into the common data structure. This happens in the Common Data level where system-specific logic is applied to the data. These data transformations range from the renaming of columns, to combining different data elements into a single new one, to bringing the data in the same level of granularity.
Once the data is put into a common data structure, it can be used to generate the specific tax reports which together form a data package. This logic sits in the Application Data level. A major advantage is that this logic only has to be set up once and not per source system, because it uses the common data structure as a source.
Finally, all transformations are centrally coordinated from a control room. In this control room, it is known which common data elements are required for each required output, how they are generated based on which cleaned data, and which source data is required and how it needs to be cleaned. This all happens in a highly automated environment with appropriate checks and balances to ensure the data quality.
Delivery of country-specific data packages
Using the data from the “application data” level, a specific data package consisting of several standardized reports is generated. The local tax legislation requires the tax team to evaluate a specific set of transactions and details in order to determine the tax position. Therefore, the difference in tax legislation results in a different information demand per country (for example, which transactional details should be included for specific deductible expenses). This highlights a key challenge for corporate income tax automation: how are local requirements incorporated based on country-specific legislation in a standardized approach?
One way of providing all information required by the local tax teams using a standardize approach, is to simply provide all available tax data to all the countries. However, this results in unnecessary work for both the central team preparing the data and the local teams using the data. As a result, the tax team has to manually manipulate the data in order to make it relevant for each specific country, which is something we want to avoid in the first place.
A better solution is the concept of a “Common Chart of Accounts”. The common chart of accounts is a set of generic ledger accounts, combined with a classification of whether the information of an account is required in a certain country. By connecting an organization’s ledgers from the various systems to this generic ledger, the common chart of accounts, it becomes possible to treat these ledger accounts in a standardized way. So regardless of the source system, it is possible to generate country-specific reports in an automated way. These data reports only contain the required information per country which drastically reduces the information shared. Therefore, the focus can be on analyzing the data which adds value to the tax compliance process.
Results of the project
Challenging the traditional and established ways of working is never easy and requires commitment and interest from the stakeholders to make it happen. Given the scale of the task at hand, implementing a data factory requires initial costs and investments by the teams months before the go-live date. It includes financial funding, resources to be assigned to the development team, connections to be established with the local tax leads, and training and on-boarding of the new way of working among local teams.
Nevertheless, the result of implementation of the tax data factory has brought significant improvement to the efficiency of the corporate tax compliance processes. By replacing the manual data activities with automated data transformations, the following benefits have been achieved:
- Reduced turnaround time
- Increased standardization
- Increased data quality
- Recured time and efforts required in data preparation
- Increased focus on analyzing only the tax-relevant data
Reduced turnaround time
The turnaround time required from collecting the source data to sharing the correct information with the tax teams has decreased significantly. As a result, the tax team has more time to analyze the data or to file an earlier declaration. To make this concrete: for one of the large countries, the lead time went from 6 to 8 weeks to less than 2!
Increased standardization
The tax team receives a single standard data package with the relevant reports for each country. These reports contain data, which can originate from difference source systems in a standard layout. The standardization of these reports enables the optimalisation of the downstream tax activities such as preparing the tax adjustments.
Increased data quality
To ensure the quality and consistency of the tax data, automated checks and reconciliations are embedded in the data processing. These automated checks reduce the risk of manual mistakes, e.g. manual copy paste errors, and will alert the tax team of any data quality issues.
Recured time and efforts required in data preparation
The time and efforts required to perform the data preparation activities has significantly decreased. For the bank, the new approach resulted in a 20-30% reduction in required hours spent, in the first year alone. This shift from manual tasks to automation has a significant impact on reducing the cost of compliance.
Increased focus on analyzing only the tax-relevant data
The standardized reports only contain data that is relevant for the specific country for which it was generated. By using a combination of the common data structure and the common chart of account, a significant reduction in the volume of data which is being shared is achieved in comparison to the traditional approach. Therefore, the tax team can focus their time and activities on analyzing the data that adds most value. For example, for one of the countries, the data volume has decreased by 80% and still contains all the required data.
Lessons learned
Reflecting on the entire project, we have formulated a few recommendations and best practices to apply along the way for similar implementations of tax data management solutions.
- Include all the responsible stakeholders in the data discovery and data understanding processes. This will ensure good alignment and understanding of what your data management solution can and will deliver;
- Closely align the results with the needs of the tax data factory users. Keep these users informed and iterate over the results until you can be confident that the results will be adopted successfully by all users;
- Design the data model with the right balance between standardization and country-specific requirements;
- Build the data model in a modular way to allow for the addition of ERP systems or data requirements, without the need for large structural changes of your model. A common data structure is essential to achieve such a modular, expandable solution;
- Establish a central process that allows you to adjust the results in accordance with country-specific regulatory requirements. In this project, this flexibility was achieved by leveraging the KPMG Common Chart of Accounts.
Conclusion
Like many emerging technologies, data management is just beginning to have a significant impact on the tax function. Although tax data management is not yet adopted by most organizations, there are already significant benefits to be gained for early adopters. The use case in which a global investment bank implemented a tax data factory as part of corporate tax compliance illustrates these benefits. This automated and standardized approach to managing data has shortened lead times, increased data quality and saved costs. Additionally, the tax team can add more value to the organization by spending more time on providing insights and optimizing processes and systems. A Tax Data Factory facilitates a more data-driven and value-added future for Tax departments.
References
[Down15] Downing, C., van Loo, L., Zegers, A., & Haenen, R. (2015). Technology, Data and Innovation – Essentials for Indirect Tax Management. Tax Planning International Indirect Taxes, 13(9).
[KPMG18] KPMG (2018). A look inside tax departments worldwide and how they are evolving: Summary report: Global Tax Department Benchmarking. Retrieved from: https://assets.kpmg/content/dam/kpmg/xx/pdf/2018/03/global-tax-benchmarking-report.pdf
[OECD20] OECD (2020). Tax Administration 3.0: The Digital Transformation of Tax Administration. Retrieved from: https://www.oecd.org/tax/forum-on-tax-administration/publications-and-products/tax-administration-3-0-the-digital-transformation-of-tax-administration.htm
[Zege21] Zegers, A., & Duijkers, R. (2021). Tax Data Management: The hidden engine for future-proofing tax management. Retrieved from: https://meijburg.nl/nieuws/article-hidden-engine-future-proofing-tax-management-0