




Door de wildgroei van digitale gegevens binnen organisaties vormen eDiscovery applicaties een essentieel onderdeel voor het doen van waarheidsvinding. Uit onze ervaring zien wij dat gebruikers van eDiscovery applicaties ervan uitgaan dat iedere applicatie doorgaans een vergelijkbare werking en resultaten levert, maar is dat wel zo? Er bestaat voor deze applicaties en de achterliggende programmatuur namelijk geen (ISO-)certificering. Om die reden hebben wij voor dit artikel op de Nederlandse markt beschikbare eDiscovery applicaties naast elkaar gezet in een ‘spierballentest’. Tot verbazing van velen zien wij als uitkomst van dit onderzoek dat deze applicaties vrijwel op alle aspecten van elkaar verschillen.
Introductie
In onze dagelijkse werkzaamheden maken wij als forensisch onderzoekers veelvuldig gebruik van eDiscovery-tooling. In een wereld waarin datavolumes exponentieel blijven groeien, is waarheidsvinding binnen omvangrijke datasets zonder de inzet van adequate eDiscovery-tooling simpelweg niet meer efficiënt uitvoerbaar. ‘eDiscovery’ wordt in de praktijk vaak geassocieerd met een zoekmachine waarbij elektronisch opgeslagen informatie wordt klaargezet om op basis van voorgeprogrammeerde algoritmes doorzoekbaar te maken. Met ‘tooling’ doelen wij op de verschillende eDiscovery-applicaties die op de markt worden aangeboden door verschillende aanbieders. Inmiddels zijn er tientallen eDiscovery-aanbieders op de markt actief, waarbij de kwaliteit, data-integriteit en functionaliteit van de verschillende elektronische zoekmachines onderling sterk verschillen. Het is niet ongebruikelijk dat eDiscovery-onderzoeken mislopen, simpelweg omdat onderzoekers ongeschikte zoekmachines gebruiken en/of de technische implicaties van de gebruikte zoekmachine onvoldoende doorgronden. Met alle onderzoekstechnische en juridische consequenties van dien.
Wij kiezen in de uitvoering van onze werkzaamheden niet voor één specifieke eDiscovery-applicatie, maar laten de besluitvorming rondom de in te zetten applicatie afhangen van een aantal factoren, waaronder de uiteindelijke informatiebehoefte van onze opdrachtgevers. Het onderlinge verschil tussen de tientallen eDiscovery-applicaties is namelijk GIGAgroot. Wij vonden het dan ook de hoogste tijd om als eDiscovery-ervaringsdeskundigen het ‘kaf van het koren’ te scheiden met een spreekwoordelijke ‘elektronische spierballentest’.
Dit artikel verstrekt, naast een mooie inkijk in de uitdagingen voor besluitvormers en gebruikers van eDiscovery-toepassingen (met behulp van ‘echte’ uitkomsten, van vier verschillende eDiscovery-applicaties op precies dezelfde datasets), natuurlijk ook praktische aspecten die relevant zijn om in ogenschouw te nemen bij de selectie van de eDiscovery-applicatie. Alvorens in te gaan op de uitkomsten van onze spierballentest een korte introductie van wat het eDiscovery-proces nu eigenlijk is aan de hand van het Electronic Discovery Reference Model (hierna: EDRM Model). Met behulp van dit model zullen wij de Babylonische spraakverwarring tussen de verschillende mogelijkheden van de eDiscovery-applicaties inzichtelijk proberen te maken.
eDiscovery-proces
Het EDRM Model fungeert als de marktstandaard en biedt een conceptuele weergave van de eDiscovery-processtappen die doorlopen (behoren) te worden, afhankelijk van de context en doelstelling waarbinnen de waarheidsvinding plaatsvindt. Met andere woorden, niet voor alle vormen van waarheidsvinding is het doorlopen van alle stappen binnen het EDRM Model vereist.
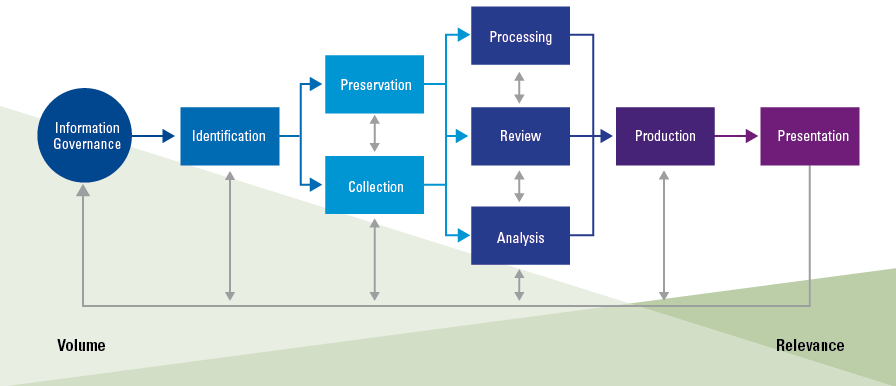
Figuur 1. Visuele weergave van het EDRM Model ([EDRM18]). [Klik op de afbeelding voor een grotere afbeelding]
De processtappen binnen het EDRM Model behelzen niet alleen technische functionaliteiten, maar omvatten ook menselijke handelingen. Dit model start bij de identificatie van de beschikbare data bij het onderzoeksobject, hetgeen altijd een menselijke handeling betreft, direct gevolgd door een aantal technische processtappen. De diverse eDiscovery-applicaties starten binnen het EDRM Model feitelijk op verschillende processtappen. De ene applicatie biedt naast ‘processing’- en ‘review’-mogelijkheden ook ‘collectie’-mogelijkheden, terwijl een andere applicatie alleen maar ‘review’-mogelijkheden biedt. Om deze reden zijn de verschillende eDiscovery-applicaties ook niet zonder meer vergelijkbaar. Afhankelijk van de onderzoeksvraag is niet elke applicatie geschikt en mogelijk is een combinatie van applicaties vereist. Geen enkele eDiscovery-applicatie op de markt heeft op dit moment alle technische stappen binnen het EDRM Model inbegrepen.
Voor onze spierballentest hebben wij eDiscovery-applicaties geselecteerd die de technische processtappen ná ‘collectie’ en ‘preservatie’ van de data ondervangen.
Selectie eDiscovery-tooling
Wij zien dat het aantal verschillende eDiscovery-applicaties de afgelopen jaren enorm is toegenomen. Het actuele aantal eDiscovery-applicaties is volgens een vergelijkingssite 1 op dit moment 78 (en dit aantal neemt toe). Belangrijk is om te vermelden dat deze producten niet allemaal de vereiste functionaliteit of eigenschappen hebben om een eDiscovery-applicatie adequaat bij een forensisch onderzoek in te kunnen zetten. Van deze 78 applicaties zijn er 40 die alle functionaliteiten bieden voor de EDRM-fases ná collectie. Hiervan worden er slechts 20 ook buiten de VS aangeboden. Op basis van deze beschikbare eDiscovery-aanbieders hebben wij, mede ingegeven door onze praktijkervaring, een representatieve selectie gemaakt van vier eDiscovery-toepassingen ter vergelijking. De betrokken eDiscovery-applicaties zijn voor dit artikel geanonimiseerd.
- marktleider A: een applicatie die bekendstaat als allrounder en al langere tijd meegaat;
- marktleider B: een applicatie die bekendstaat om zijn goede analyse- en reviewmogelijkheden;
- marktleider C: een applicatie die bekendstaat om zijn processingkracht en een breed spectrum aan bestandstypen accepteert;
- startup: een nieuwkomer in de markt die op papier vergelijkbare dienstverlening biedt als de marktleiders.
Selectie datasets
In de praktijk te onderzoeken datasets bevatten een diversiteit aan bestandstypen en -grootten. Voor onze spierballentest hebben wij drie verschillende datasets samengesteld die deze diversiteit op een goede wijze weerspiegelen. Aangezien het belangrijk is om reproduceerbare resultaten te publiceren, is gebruikgemaakt van publiekelijk beschikbare datasets. Deze datasets zijn alle afkomstig van de EDRM-website [EDRM18], een community van eDiscovery-en juridische professionals, die praktische middelen creëren om eDiscovery en informatiebeheer te verbeteren. Hieronder zijn de gebruikte datasets kort toegelicht.
Dataset 1: EDRM Enron e-mail
De eerste dataset bestaat uit 190 PST-bestanden (mailboxen) en heeft een totale omvang van 53,0 gigabyte. Dit is de Enron e-maildataset, bekend van het boekhoudschandaal, die al jaren als industriestandaard wordt gezien om te gebruiken voor eDiscovery-training en -testen. De Enron dataset is geselecteerd omdat deze relatief groot in omvang is en over een grote diversiteit aan e-maildocumenten en bijlagen beschikt.
Dataset 2: EDRM forensische kopie
De tweede dataset betreft een ‘evidence’-bestand, namelijk het gestandaardiseerde .E01-formaat. Een dergelijk formaat wordt doorgaans gebruikt bij het maken van een forensische kopie van bijvoorbeeld een harde schijf. De totale omvang van het bestand is 3,0 gigabyte. Forensische kopieën zijn een belangrijk startpunt in het kader van waarheidsvinding en daarom is dit type dataset meegenomen in dit onderzoek. In vergelijking met dataset 1 bevat deze dataset veel meer verschillende bestandstypen, zoals deze in een kopie van een computer aangetroffen kunnen worden.
Dataset 3: EDRM bestandsdiversiteit-set
Deze laatste dataset betreft een collectie van 4036 bestandsformaten die mogelijk binnen een organisatie aangetroffen kunnen worden en bruikbare informatie kunnen bevatten ten behoeve van waarheidsvinding. Deze dataset omvat een grote diversiteit aan bestandstypen waarvan wij ons afvroegen in welke mate deze, in de door ons onderzochte eDiscovery-toolings, ondersteund zouden worden. Deze dataset is een samenvoeging van drie datasets (File Format Data Set, Internationalization Data Set en de Public Micro Data Set) op de EDRM-website [EDRM18].
Bovengenoemde datasets zijn op dezelfde wijze in de vier door ons betrokken eDiscovery-applicaties ingeladen. Dit vertrekpunt staat als basis voor het uitvoeren van de tests die in het volgende hoofdstuk op hoofdlijnen beschreven staan.
eDiscovery-spierballentests
De eDiscovery-applicaties zijn door ons op 47 aspecten met elkaar vergeleken, die in de ondergenoemde categorieën ingedeeld kunnen worden.
- Preliminair – Overwegingen op basis van de doelstelling van de gebruiker en het beschikbare budget. Het gaat hierbij om elementen zoals prijs, toegangsmogelijkheden en de ondersteuning van besturingssystemen.
- Algemeen – Beschikbare technische en functionele kenmerken van de applicatie, zoals de tijd die nodig is om de toepassing te installeren of de schaalbaarheid van de applicatie voor grotere datasets.
- Verwerking van data – Mogelijkheden en prestaties op het gebied van het verwerken van de data, zoals het uitvoeren van ‘Optical Character Recognition’, de-duplicatie van bestanden en snelheid.
- Review – Veelzijdigheid en robuustheid van de applicatie met betrekking tot het zoeken en reviewen tijdens een digitaal onderzoek, zoals zoekfunctionaliteiten, aanpasbaarheid van de reviewomgeving en gebruiksgemak.
- Productie – Geschiktheid van de applicatie om documenten te produceren als resultaat van het onderzoek, waaronder de diversiteit van exportformaten en redactiemogelijkheden.
- Projectmanagement – De functionaliteiten op het gebied van projectmanagement door middel van het genereren van rapportages om voortgang en kwaliteit te kunnen bewaken en granulariteit van toegangsbeperking.
In figuur 2 zijn van de 47 onderzochte aspecten de veertien meest relevante aspecten weergegeven, verdeeld over de zes hiervoor beschreven categorieën.
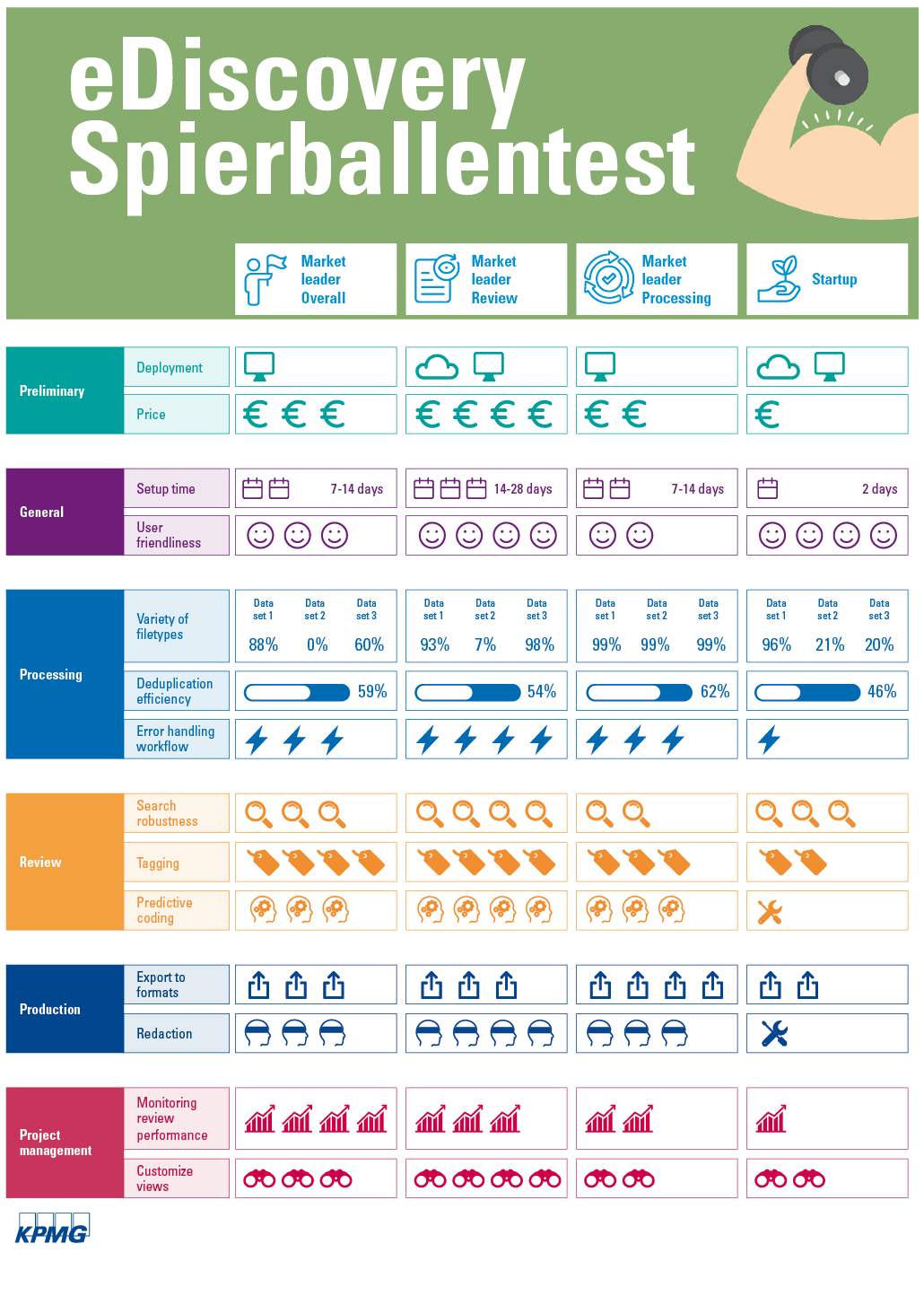
Figuur 2. Informatieve illustratie van de uitkomsten van de eDiscovery-spierballentest ([KPMG18]). [Klik op de afbeelding voor een grotere afbeelding]
Deze informatieve illustratie geeft onze uitkomsten in een vierpuntsschaal weer, waarbij één pictogram, relatief gezien, de laagste uitkomst representeert en vier pictogrammen de hoogst mogelijke uitkomst voorstelt. De afbeelding 
geeft aan dat de betreffende functionaliteit nog in ontwikkeling is.
Onderzoeksresultaten in vogelvlucht
Preliminair
Om te beginnen is het kostenplaatje dat aan de verschillende eDiscovery-toepassingen hangt uiteenlopend. Dit is niet eenduidig in dit artikel uiteen te zetten, omdat de afrekenmethodiek per eDiscovery-applicatie afhankelijk is van de afspraken die gemaakt zijn per afnemer. Doorgaans zijn de kosten voor de applicaties van de marktleiders aanzienlijk hoger dan voor de applicatie van de startup. Tussen de verschillende marktleiders zijn kostentechnisch eveneens verschillen zichtbaar. Alle vier de applicaties kunnen op de technische infrastructuur van de gebruiker worden gehost. De gebruiker is dan verantwoordelijk voor de hosting en het uitvoeren van updates. Voor twee van de vier eDiscovery-applicaties biedt de leverancier eveneens de mogelijkheid om de applicatie voor de gebruiker in de cloud te hosten.
Algemeen
Ten aanzien van de setup-tijd die benodigd is per applicatie zijn grote verschillen waarneembaar. Waar je met de startup-applicatie binnen 48 uur al aan de slag kunt met indexeren en reviewen van de digitale documenten, duurt de setup-tijd van de verschillende marktleiders minstens één à twee weken. Deze setup-tijd wordt grotendeels bepaald door de infrastructuur die hiervoor benodigd is. Daarnaast wordt de setup-tijd ook beïnvloed door de mate van expertise die benodigd is. Indien snelheid geboden is, kan de keuze van applicatie in aanvangstijd een groot verschil maken.
De gebruiksvriendelijkheid, die door ons is ingeschat op basis van eigen waarneming, laat eveneens grote verschillen zien. Waar marktleider B en de startup grotendeels intuïtief zijn ingeregeld voor de reviewer, is de benodigde technische kennis voor het gebruik van de eDiscovery-applicatie C aanzienlijk hoger. Dit komt onder andere tot uiting in de hoeveelheid opties die de reviewer wordt aangeboden in het reviewscherm, het aantal benodigde ‘clicks’ om een document te reviewen en de eenvoud van het zoeken en vinden van documenten.
Verwerking van data
Als wij vervolgens kijken naar de processingcapaciteit, die feitelijk als de ‘core-functionaliteit’ van een eDiscovery-applicatie beschouwd zou kunnen worden, dan zijn de verschillen niet anders dan (zeer) groot te noemen. Dit komt tot uiting in het aantal documenten dat verwerkt wordt door de verschillende oplossingen met betrekking tot de drie verschillende datasets en daarmee directe impact heeft op de documenten die door de onderzoeker doorzocht kunnen worden. Marktleider C haalt op alle fronten – in termen van processing – de beste resultaten, omdat deze applicatie het grootste aantal bestanden kan detecteren. Deze uitkomsten zijn vervolgens door ons als norm gebruikt om de processingcapaciteit van de andere applicaties te kunnen vaststellen. De 99% representeert derhalve de beste benadering van het aantal te detecteren bestanden op basis van de vier door ons betrokken applicaties. Daarbij is het van belang om te realiseren dat alles wat niet gedetecteerd wordt bij het processen van de data, feitelijk niet verwerkt wordt en daarmee niet doorzoekbaar is of kan worden gemaakt.
Als wij vervolgens dieper naar de percentages kijken ten opzichte van de drie datasets, kunnen wij onderstaande observaties plaatsen:
- Bij dataset 1 merken wij op dat met name marktleider A achterblijft bij het aantal .pst-bestanden dat verwerkt is in vergelijking met de andere applicaties.
- Bij dataset 2 zien wij dat alle andere applicaties sterk achterblijven op marktleider C. Bij marktleider A constateren wij zelfs een 0%-score, wat verklaard kan worden door het feit dat het alomvattende ‘evidence’-bestand (.e01) niet ondersteund wordt. Hierdoor kunnen de bestanden binnen het ‘evidence’-bestand ook niet worden verwerkt.
- Bij dataset 3 constateren wij dat met name de startup veel bestanden niet verwerkt en marktleider A tevens fors achterblijft op marktleiders B en C. Zoals eerder aangegeven, bevat deze dataset een grote diversiteit aan bestandsformaten die met de applicaties van de startup en markleider A niet geheel betrokken kunnen worden in het onderzoek.
Om te voorkomen dat onderzoekers meerdere malen naar hetzelfde document hoeven te kijken, voeren de eDiscovery-applicaties een de-duplicatie op de bestanden uit. Met de-duplicatie worden de dubbelingen uit de dataset verwijderd. De percentages representeren het gedeelte van dataset 1 waarvan de applicatie heeft vastgesteld dat deze duplicaten zijn. In deze resultaten zijn net als bij de processingcapaciteit verschillen tussen de applicaties zichtbaar, waarbij het de-duplicatiepercentage van marktleider C het hoogst is en dus de meeste duplicaten in de dataset voor de gebruiker elimineert voor review. Daarnaast is een goede afhandeling van mogelijke foutmeldingen tijdens de verwerking van de gegevens essentieel om te borgen dat er geen informatie ontbreekt. Marktleider B biedt de meest uitgebreide en gestroomlijnde workflow om deze foutmeldingen in te kunnen zien en op te kunnen volgen.
Review
De ‘review’-functionaliteit in eDiscovery-applicaties wordt gebruikt door onderzoekers om de bestanden te doorzoeken en de resultaten van deze zoekslagen te beoordelen op relevantie voor het doel van de waarheidsvinding. Om een vastlegging te kunnen maken van deze beoordeling wordt in de praktijk gebruikgemaakt van ‘tagging’. Daarnaast bieden eDiscovery-applicaties steeds vaker een ‘predictive coding’-functionaliteit, waarmee de applicatie op basis van machine-learningalgoritmen de relevantie van documenten voorspelt aan de hand van keuzes die de gebruiker eerder heeft gemaakt. Ons onderzoek wijst uit dat de eDiscovery-applicaties verschillende zoekresultaten opleveren bij het toepassen van dezelfde zoektermen. Dit is enerzijds gerelateerd aan het feit dat iedere applicatie een ander percentage van de dataset geïndexeerd heeft. Anderzijds merken wij tevens op dat de zoekalgoritmen bij de eDiscovery-tools een verschillende werking hebben op de datasets. Daarnaast ondervinden wij dat de ‘tagging’-functionaliteit onder de marktleiders relatief uitgebreider is dan de mogelijkheden die door de startup geboden worden. Tot slot bieden alleen de marktleiders op dit moment de ‘predictive coding’-functionaliteit, maar zijn de mogelijkheden voor toepassing hiervan uitgebreider bij marktleider B ten opzichte van marktleiders A en C.
Productie
Zodra een onderzoek naar waarheidsvinding is afgerond, dient er vaak een export gemaakt te worden van de resultaten. Daarbij is het voor juridische producties soms van belang om specifieke gegevens (zoals persoonsgegevens) te redigeren. Hiertoe wordt binnen eDiscovery gebruikgemaakt van de ‘redaction’-functionaliteit waarin je stukken tekst in documenten onleesbaar kan maken alvorens deze te exporteren.
Wij zien dat marktleider C de meest uitgebreide mogelijkheden biedt ten aanzien van het aantal formaten waarin de resultaten geëxporteerd kunnen worden. Daarnaast bieden alleen de marktleiders redaction-functionaliteit, die het meest uitgebreid is bij marktleider B.
Projectmanagement
Aangezien het uitvoeren van een onderzoek met behulp van een eDiscovery-applicatie veelomvattend kan zijn en er veelal met meerdere onderzoekers tegelijkertijd aan wordt gewerkt, is de projectmanagement-functionaliteit van belang om zicht te houden op de voortgang en kwaliteit van het onderzoek. Wij merken op dat marktleider A de meest uitgebreide monitoring dashboards en rapportages biedt voor het inzichtelijk maken van de voortgang van de review. Daarnaast biedt marktleider B de meest uitgebreide mogelijkheden om de rapportages in de applicatie naar eigen wens te kunnen aanpassen.
Resumerend
Het algemene beeld is dat er geen eDiscovery-applicatie hetzelfde is. De eDiscovery-toepassingen zijn niet alleen op het gebied van kosten, setup en architectuur verschillend, maar juist ook op het gebied van processen, de-dupliceren, indexeren en zoeken. Er bestaat voor deze applicaties en de achterliggende programmatuur geen (ISO-)certificering of algemene instantie die test of een eDiscovery-toepassing ‘werkt’.
Zo scoort marktleider B op de meeste onderzochte aspecten het best van de vier applicaties. Het gebruik van deze applicatie vereist echter een forse investering en opstarttijd, waardoor deze met name geschikt lijkt voor grote en complexe trajecten. Bij minder complexe trajecten kan men mogelijk uit de voeten met de applicatie van de startup, waarbij de investering en opstarttijd vele malen lager respectievelijk korter is, maar men zich bewust dient te zijn van de beperkingen en de gevolgen daarvan voor de waarheidsvinding.
Bij de keuze en het gebruik van een eDiscovery-applicatie is het daarom van belang om de in dit artikel opgenomen aspecten in het achterhoofd te houden om te voorkomen dat ‘in het land der blinden eenoog koning wordt’. Objectieve en onafhankelijke ondersteuning ten aanzien van de selectie en toepassing van een of meerdere eDiscovery-applicatie(s) is daarmee elementair voor het doen van gedegen elektronisch onderzoek.
Noten
- Op de website [CAPT18] staan op het moment van schrijven 78 applicaties.
Referenties
[CAPT18] CAPTERRA, eDiscovery Software, Capterra.com, https://www.capterra.com/electronic-discovery-software/, 2018.
[EDRM18] EDRM, EDRM Model, EDRM.net, https://www.edrm.net/frameworks-and-standards/edrm-model/, 2018.
[KPMG18] KPMG, KPMG eDiscovery Spierballentest 2018, KPMG, 2018.