




‘Data’ en ‘datakwaliteit’ als onderwerp voor een artikel: wie is daar nu in geïnteresseerd? Data staan aan de basis van beslissingen die bedrijven en instellingen dagelijks nemen. Beslissingen waarmee vaak grote financiële belangen zijn gemoeid, zoals beslissingen over grote aankopen, of over focus op nieuwe markten. Regelmatig verschijnen artikelen in kranten en bladen over organisaties die last hebben van data van slechte kwaliteit. Er is één specifieke soort data die in dit verband cruciaal is: de masterdata (stamgegevens). In dit artikel willen wij een praktische handreiking bieden aan bedrijven en instellingen die inzicht willen verkrijgen in de kwaliteit van masterdata, mogelijke kostenbesparingen en de kwaliteit vervolgens willen verbeteren.
Inleiding
Naast de hierboven genoemde financiële belangen kunnen beslissingen op basis van verkeerde data ook een ingrijpende invloed hebben op het welzijn van mensen. Een ziekenhuis gaf drie jaar lang een te hoge dosis chemotherapie: de hoeveelheid van het middel dat wordt gegeven, wordt gemeten in milliliters of in internationale eenheden. Bij het omrekenen naar milliliters zou in september 2008 een fout zijn gemaakt. Die fout werd pas ontdekt toen in 2012 van leverancier werd veranderd.[Zie nu.nl, 7 december 2012.]
Masterdata (stamgegevens) zijn data die eenmaal in een systeem worden vastgelegd om daarna in afzonderlijke bedrijfstransacties te worden gebruikt. Denk hierbij aan leveranciers-, klant- en productgegevens. Ook referentiedata worden hiertoe gerekend, zoals een tabel met wisselkoersen waaraan wordt gerefereerd als een inkoopcontract in het systeem wordt vastgelegd. Onvolledige of onjuiste masterdata kunnen een enorme impact hebben op de operationele bedrijfsvoering. Dit brengt onnodig hogere kosten van de bedrijfsvoering met zich mee. Zonder masterdata kunnen bedrijfstransacties namelijk niet in systemen worden ingevoerd. Onjuiste masterdata kunnen leiden tot logistieke problemen (afleveradres onjuist), inefficiënties (foutieve data die moeten worden hersteld), of aansturingsproblemen (verkeerde financiële of operationele rapportages). Door de masterdata op orde te brengen, worden dit soort problemen voorkomen en kunnen kostenbesparingen gerealiseerd worden. Zie figuur 1 voor de relatie tussen het verbeteren van de datakwaliteit en kostenbesparingen.

Figuur 1. Relatie tussen het verbeteren van datakwaliteit en kostenbesparingen.
We richten ons in dit artikel in eerste instantie op degene die verantwoordelijk is voor het beheer van data en datakwaliteit: de datamanager. Voor de leesbaarheid hebben we het in dit artikel daardoor steeds over de datamanager. Deze term moet niet worden verward met de in de IT gebruikte functiebenaming ‘databasebeheerder’, die verantwoordelijk is voor het logische beheer van data in de (veelal) relationele databases. Wij hebben niet zozeer een specifieke functie op het oog als wel een rol die vooral actief is in de primaire bedrijfsprocessen van de organisatie. Het is degene die verantwoordelijk is voor de uitvoering van data-lifecycleprocessen, die zich richten op het verkrijgen, verrijken, verwerken, distribueren en archiveren van data. En verder houdt deze rol zich bezig met het toezicht op de kwaliteit van deze data.
In dit artikel wordt eerst stilgestaan bij de vraag waarom een datakwaliteitsonderzoek belangrijk is en hoe een dergelijk onderzoek uitgevoerd kan worden. Vervolgens gaan we in op hoe het vervolg eruitziet.
Waarom een datakwaliteitsonderzoek?
Er is de afgelopen jaren veel onderzoek gedaan naar de feitelijke datakwaliteit bij bedrijven en de impact die dit heeft op de bedrijfsvoering. De Aberdeen Group heeft in 2011 een internationaal onderzoek uitgevoerd onder 200 organisaties, waarvan 93 organisaties processen en systemen voor het beheer van masterdata hadden ingevoerd ([Rowe11]); dit wordt ook wel Master Data Management (MDM) genoemd. Ze heeft onderzocht of het investeren in masterdata voordelen oplevert in de bedrijfsvoering. Daarbij heeft ze gekeken naar de impact op complete en tijdige leveringen en de impact op de geregistreerde voorraden in het systeem. Dit levert het in tabel 1 weergegeven beeld op.
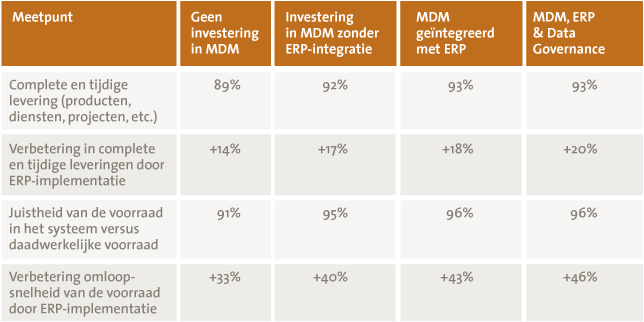
Tabel 1. Stroomlijnen van de leverings- en voorraadprocessen door MDM.
Uit tabel 1 blijkt dat bedrijven die investeren in het beheren van hun masterdata significant beter presteren dan bedrijven die dit niet doen. Ook geeft dit resultaat aan dat bedrijven door MDM meer waarde uit hun ERP-implementatie halen. Bijvoorbeeld de complete en tijdige leveringen nemen met zes procentpunten toe (van +14% naar +20%) door investering in MDM.
Het beter kunnen presteren zorgt ervoor dat deze bedrijven hun kosten kunnen verlagen. Dit wordt verderop in de publicatie van de Aberdeen Group ([Rowe11]) toegelicht. Hierin is onderzocht wat de impact van MDM is op de kosten en het resultaat. Tabel 2 toont daarvan de resultaten.
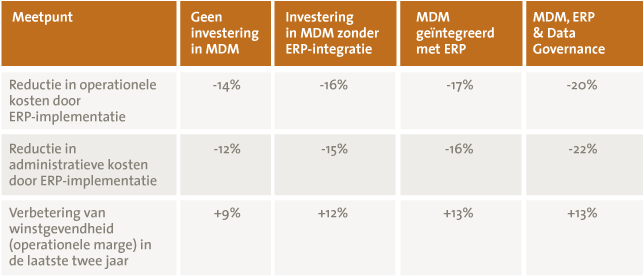
Tabel 2. Financiële impact van MDM.
Hieruit blijkt dat bedrijven die investeren in het beheren van hun masterdata significant lagere kosten hebben dan bedrijven die dit niet doen. Vooral het verschil tussen de topresultaten rechts in tabel 2 en de laagste resultaten links in de tabel zijn groot: zes procentpunten reductie in operationele kosten, tien procentpunten reductie in administratieve kosten en vier procentpunten stijging van de winstgevendheid. De relatie tussen het beheren van masterdata en de lagere kosten ligt erin dat masterdata van goede kwaliteit de effectiviteit van een ERP-systeem verbeteren. Dit zorgt vervolgens voor een verbeterde bedrijfsvoering en daardoor voor lagere kosten. Een bedrijf dat voor een ERP-implementatie € 100 miljoen winst maakte zou na de implementatie volgens dit onderzoek € 9 miljoen extra winst maken. Door MDM en datagovernance daarbij te implementeren kan volgens dit onderzoek nog € 4 miljoen extra winst behaald worden.
Een concreet voorbeeld uit eigen land betreft de wens van het kabinet om ‘scheefhuren’ te ontmoedigen. Door woningbouwcorporaties een huurverhoging te laten opleggen aan huurders van wie het inkomen boven een bepaalde grens uitkomt, wil het kabinet scheefhuren tegengaan. Het koppelen van de gegevens van de belastingdienst (inkomen) aan informatie uit de gemeentelijke basisadministratie (adres belastingplichtige) blijkt daarbij tot problemen te leiden. De NOS schrijft hier vorig jaar over ([Zijls13]): ‘Bij de Belastingdienst ontbreekt van veel woningen of huurders de benodigde informatie. Zo krijgen veel corporaties van de Belastingdienst te horen dat de eigenaar van de woning, de huurder of het inkomen niet bekend is, of dat het huisnummer niet klopt. Bij de meeste corporaties ontbreekt bij 10 tot 30 procent van de woningen de gegevens.’ Dit alles zorgt ervoor dat de uitvoering van het kabinetsbeleid wordt vertraagd en daardoor hogere kosten met zich meebrengt.
Bedrijven worden zich pas bewust van het belang van kwalitatief goede data, nadat ze met de gevolgen van kwalitatief slechte data zijn geconfronteerd. Dit blijkt onder andere uit het bovenstaande voorbeeld: een huurverhoging kan niet worden opgelegd doordat het inkomen niet of niet juist in het systeem staat. Als organisaties, door deze vervelende incidenten, zich ervan bewust zijn dat hun data kwalitatief niet goed genoeg zijn en zij eventueel ook geen goed zicht op de feitelijke kwaliteit hebben, komt er een lastige vraag naar boven drijven. Hoe kan de datakwaliteit verbeterd worden? Om deze kwaliteit te kunnen verbeteren is het eerst van belang om de huidige kwaliteit in kaart te brengen. In de volgende paragraaf laten we zien hoe de datakwaliteit inzichtelijk kan worden gemaakt.
Hoe pak je een datakwaliteitsonderzoek aan?
Voor een datakwaliteitsonderzoek hanteren we de tien stappen zoals weergegeven in figuur 2. Deze aanpak borduurt voort op wat Ronald Jonker eerder al schreef over datakwaliteitsonderzoek ([Jonk12]). Datakwaliteitsonderzoeken hebben wij bij vele organisaties uitgevoerd, onder andere bij een internationale organisatie die een Financial Shared Service Center (FSSC) aan het inrichten was. De boekhouding werd centraal belegd, denk daarbij aan de crediteuren-, debiteuren- en vaste activa-administratie. Belangrijk onderdeel van dit project was het op orde brengen van de masterdata om daarmee bij te dragen aan efficiënte FSSC-processen, correcte betalingen en correcte rapportages. Om te weten wat er op orde gebracht moest worden, hebben we een datakwaliteitsonderzoek uitgevoerd. Vervolgens hebben wij ondersteund bij het opschonen van de data en het schoon houden ervan. De voorbeelden die hierna genoemd worden hebben betrekking op deze casus.
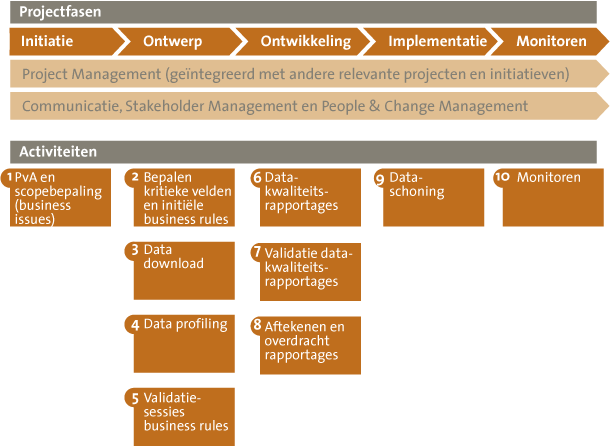
Figuur 2. Aanpak van datakwaliteitsonderzoek.
Het onderzoek begint zoals ieder onderzoek met het bepalen van de reikwijdte (stap 1). Op basis van business issues die bij het bedrijf bekend zijn, stelt de datamanager een lijst samen met masterdataobjecten die onderdeel uit gaan maken van het onderzoek. Bij een masterdataobject kan gedacht worden aan het leveranciers-, klanten- of productbestand. Een business issue is iets wat in de dagelijkse praktijk fout gaat en waar de organisatie last van heeft. Het kan bijvoorbeeld zijn dat de bankrekeningnummers van een aantal leveranciers onjuist in het systeem staan zodat de betalingen niet juist verwerkt kunnen worden. In eerste instantie zou u kunnen denken dat alleen de leverancier daar last van heeft omdat deze niet betaald wordt. Echter, in de praktijk heeft de organisatie zelf daar juist ook last van doordat het behandelen van aanmaningen, misgelopen betaalprogramma’s of het terugvorderen van foutief overgemaakte bedragen veel tijd in beslag neemt. Door per gegevensveld binnen deze objecten de impact op de bedrijfsprocessen te bepalen, ontstaat uiteindelijk een lijst van kritieke velden (stap 2). Deze velden worden ‘kritiek’ genoemd omdat ze noodzakelijk zijn voor de efficiënte en effectieve bedrijfsprocessen. Een kritiek veld binnen het leveranciersbestand is zoals eerder genoemd het bankrekeningnummer. Als dit ontbreekt kan de betreffende leverancier niet betaald worden. En als dit incorrect is kan het gebeuren dat aan de verkeerde leverancier betaald wordt. Zie figuur 3 voor een overzicht van de werkwijze om processen naar masterdata te vertalen.

Figuur 3. Vertaling van proces naar business rules.
Onderdeel van dezelfde stap is het bepalen van initiële bedrijfsregels (business rules). Bedrijfsregels zijn regels die de operationele bedrijfsvoering moeten stroomlijnen en geven dus aan waar de data aan moeten voldoen. Een bedrijfsregel kan gezien worden als een ‘als…dan’-relatie. Bijvoorbeeld: als een leverancier uit Nederland komt, dan moet het btw-nummer ingevuld zijn. Of: als een leverancier actief is, dan moet deze een bankrekeningnummer hebben. De leverancier kan anders niet betaald worden, maar dat hoeft alleen voor de leveranciers die te gebruiken zijn (actief). Het heeft namelijk geen zin om het bankrekeningnummer te vullen voor leveranciers die in het archief staan. Door samen met een procesdeskundige door de bekende business issues heen te lopen, kan de datamanager een eerste vertaling maken richting de bedrijfsregels. Onze ervaring leert dat hierdoor al veel initiële bedrijfsregels verzameld kunnen worden en dat deze manier sneller is dan eerst zelf de data inhoudelijk te bekijken. Zelf de data bekijken is namelijk tijdrovend en vergt specifieke data-analysevaardigheden.
Vervolgens verzamelt de datamanager de benodigde data vanuit de relevante systemen die betrekking hebben op de kritieke velden en initiële business rules (stap 3). Door daarna ‘profiling’ toe te passen kan de datamanager de inhoud van een veld analyseren (stap 4). ‘Profiling’ kan uitgevoerd worden met datakwaliteitssoftware. Dit is speciale software om te ondersteunen bij het in kaart brengen en verbeteren van de datakwaliteit. De datamanager ziet met behulp van de software hoe vaak een veld gevuld is, welke waardes hoe vaak voorkomen en hoe het formaat is opgebouwd. De datamanager ziet dan bijvoorbeeld hoe vaak het veld ‘bankrekeningnummer’ leeg is. Op basis van deze profiling kunnen de bedrijfsregels aangescherpt worden.
Een nieuwe trend is om aanvullend op basis van de omliggende data voorspellingen te doen over bedrijfsregels. De datamanager kan hiermee voorspellen welke velden binnen het datamodel een relatie hebben met het kritieke veld. Een mogelijke uitkomst kan zijn dat het land van een leverancier een sterke relatie heeft met de betaalwijze. Blijkbaar zijn er betaalwijzen per land toegekend en zou dit dus een bedrijfsregel kunnen zijn. Wij zien het gebruik van dit soort data-analyse als een waardevolle aanvulling boven op de input van de procesdeskundigen en de ‘profiling’.
De resultaten uit deze eerste analyse stemt de datamanager af met de procesdeskundigen (stap 5). Onze ervaring leert dat het raadzaam is dat de datamanager de details voorhanden heeft, zodat hij bij het bespreken van bedrijfsregels ook voorbeelden kan geven van gevallen waarin het fout gaat. Dit zorgt voor een snellere aanscherping van de regels. Vervolgens implementeert de datamanager de aangescherpte regels in de al eerder genoemde datakwaliteitssoftware (stap 6). Hiermee kunnen datakwaliteitsrapportages worden gemaakt waarop gedetailleerd de incorrecte records staan; deze rapportages worden ook wel ‘schoningslijsten’ genoemd omdat later in het project op basis van deze lijsten geschoond kan worden. Dit kan bijvoorbeeld een lijst zijn van leveranciers waarbij de betaalwijze nog op ‘cheque’ staat terwijl de organisatie ervoor gekozen heeft geen chequebetalingen meer te doen. Het is belangrijk om deze lijsten af te stemmen met een procesdeskundige (stap 7). Een bedrijfsregel kan namelijk op het gevoel goed zijn, maar in de praktijk ten onrechte veel incorrecte records laten zien. Het is mogelijk dat een procesdeskundige een bepaald standaardscenario is vergeten of dat hij niet alle uitzonderingen kon overzien. In één van onze projecten kwamen we bijvoorbeeld tegen dat de procesdeskundige niet wist dat in Amerika nog veel met cheques wordt betaald. Voor Nederlandse bedrijven is het daarentegen logisch om chequebetalingen niet meer toe te staan. Dit zorgde ervoor dat ten onrechte veel Amerikaanse bedrijven op de schoningslijst stonden, die in werkelijkheid terecht via cheque betaald konden worden.
Nadat alles afgestemd is, en de regels in de datakwaliteitssoftware aangepast zijn, maakt de datamanager een totaaloverzicht van de gevonden incorrecte records. Hiermee is de datakwaliteit inzichtelijk gemaakt.
Hoe vaak moet je de resultaten met de organisatie valideren?
De aanpak gaat uit van het veelvuldig betrekken van procesdeskundigen om input te leveren op de bedrijfsregels. Onze ervaring leert dat daar niet aan te ontkomen is. Een datamanager kan veel afleiden op basis van alleen de data, maar echt scherpe bedrijfsregels krijgt de datamanager pas na veelvuldige validatie. Dit wordt ook onderbouwd door Ted Friedman, vicepresident en onderscheiden analist bij Gartner’s Information Management team. Hij gaf vorig jaar in een interview aan ([Laws13]) dat een goede set aan bedrijfsregels maatwerk is, dus dat een standaard- of ongevalideerde set aan bedrijfsregels maar een beperkte waarde heeft. Dit komt ook overeen met onze ervaring. Zoals in figuur 4 is aangegeven, bestaat er een relatie tussen de mate waarin uitkomsten van datakwaliteitsonderzoek zijn gevalideerd en de effectiviteit daarvan. Zonder validatie is de effectiviteit laag. De kans is namelijk groot dat de initiële bedrijfsregels moeten worden aangescherpt. Het gevolg is dat zonder validatie records als incorrect worden gepresenteerd, die dat in feite niet zijn. Alleen bij gedetailleerde analyse van de resultaten – en daarmee validatie van de gehanteerde bedrijfsregels – kunnen deze onjuistheden worden geconstateerd en hersteld. Denk bijvoorbeeld aan het zojuist genoemde voorbeeld van chequebetalingen in Amerika.
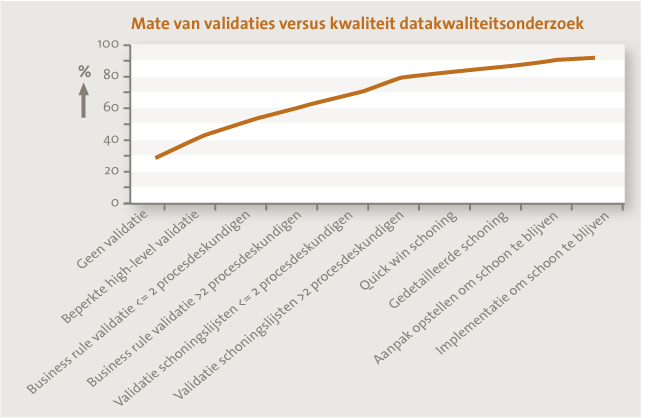
Figuur 4. De kwaliteit van het onderzoek neemt toe met het aantal validaties.
We zien in de praktijk echter dat uit kostenoverwegingen beknibbeld wordt op het aantal iteraties. Men volstaat dan met een initiële analyse, die door degenen belast met het datakwaliteitsonderzoek vervolgens als waarheid aan de organisatie wordt gepresenteerd. Procesdeskundigen ontdekken dan snel onvolkomenheden. Het gevolg is dat het draagvlak voor het datakwaliteitsonderzoek en het vervolgens verbeteren van de kwaliteit van de data afbrokkelt, omdat het vertrouwen in de uitkomsten wegvalt. Dit geeft aan dat ook bij datakwaliteitsonderzoek, net zoals bij vele andere typen onderzoek, hoor en wederhoor belangrijk is.
In figuur 4 is ook te zien dat het schonen van de data tevens zorgt voor een verbetering van het datakwaliteitsonderzoek. Dit komt doordat er bij het gedetailleerd onderzoeken van de incorrecte records zaken worden ontdekt, die tijdens eerdere validatie niet aan het licht zijn gekomen. Tijdens de schoning zou de datamanager kunnen constateren dat voor bepaalde landen uitzonderingen gelden. Dit was bijvoorbeeld niet bekend bij de procesdeskundigen. Het kan zelfs gebeuren dat de organisatie last heeft van de schoning, doordat onjuiste bedrijfsregels zijn gehanteerd. Denk aan ons voorbeeld van de chequebetalingen. Indien inderdaad tot (onterechte) schoning van de records wordt overgegaan die chequebetalingen toestaan, dan leidt dit vanzelf tot klachten van medewerkers, die vervolgens het betalingsproces niet kunnen uitvoeren. Hoe de data worden geschoond, wordt uitgelegd in de volgende paragraaf.
De lijn in figuur 4 gaat bewust niet volledig naar de 100%. Zelfs na veelvuldige validatie kunnen de procesdeskundige en de datamanager nog zaken over het hoofd hebben gezien. Dit is inherent aan bedrijfsregels ([BuRG03]). Het is namelijk een utopie te veronderstellen dat een organisatie een perfecte set aan bedrijfsregels kan definiëren. Het is daarom van belang om vooraf deze verwachting af te stemmen met de ontvangers van een datakwaliteitsrapportage, zodat ze weten hoe ze de resultaten moeten wegen. 100% ‘schone’ data is een utopie. Indien controle op de kwaliteit van data en het vervolgens corrigeren van incorrecte records een ingebed proces is, waarbij ook in continuïteit bedrijfsregels worden aangepast aan de feitelijke werking van het bedrijfsproces, dan zal datakwaliteit tenderen naar 100%, zonder die 100% datakwaliteit te bereiken.
Hoe ziet het vervolg eruit?
Na het in kaart brengen van de datakwaliteit kan de organisatie ervoor kiezen te gaan schonen. Wij raden aan dat het management de schoningslijsten aftekent (stap 8). Het management steunt daarmee de werkzaamheden en staat in voor de kwaliteit van de rapportages. Dit aftekenen is nodig, want in enkele van onze projecten hebben wij gezien dat onvoldoende steun vanuit het management ervoor zorgde dat prioriteiten van medewerkers niet bij het schonen werden gelegd. Dataschonen (stap 9) lijkt een wat saaie bezigheid, maar uit bedrijfsvoeringsoogpunt wel een belangrijke. Dataschonen vereist accuratesse en een goed analytisch vermogen. Het is daarmee geen routineklus. In dit verband hebben wij in één van onze projecten ervaren dat enthousiasme alleen niet voldoende garantie is voor een goed resultaat. In dit project gingen medewerkers direct enthousiast aan de slag met schoningslijsten, zonder na te denken over het effect van een doorgevoerde schoning op de bedrijfsvoering. In dit geval vermeldden de schoningslijsten ten onrechte winkelartikelen die uit het bestelboek gehaald moesten worden. De schoning zorgde ervoor dat die artikelen niet langer bestelbaar waren. De winkels hadden daar last van. Dit kan voorkomen worden door een additionele controle door de ‘schoners’ voordat tot daadwerkelijke schoning wordt overgegaan. Deze check is belangrijk, opdat er geen fouten in het systeem kunnen sluipen. Als de check ontbreekt zou dat juist kunnen zorgen voor extra kosten doordat processen mislopen in plaats van een kostenbesparing opleveren.
Om de voortgang van de schoningsactiviteiten te meten voert de datamanager dezelfde analyses uit zoals bij de initiële lijsten maar dan op recente data (stap 10). Onze ervaring is dat de weergave van de voortgang in een dashboard erg motiverend werkt. Zie figuur 5.
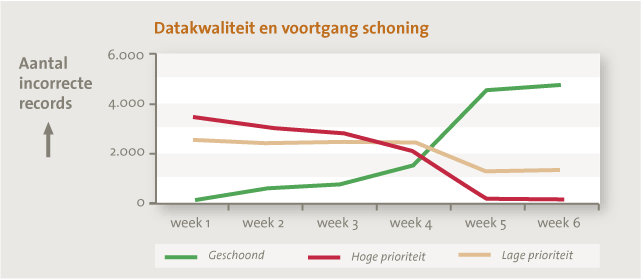
Figuur 5. Voorbeeld datakwaliteitsdashboard: datakwaliteit en voortgang schoning.
Tijdens een schoning krijgt de datamanager meestal de vraag: ‘Maar hoe houden we de data op orde?’ Een organisatie kan reactief blijven werken door maandelijks de werklijsten uit te draaien en direct op te pakken. Indien Master Data Management aan de voorkant niet goed is geregeld, is het maandelijks ‘dweilen met de kraan open’. Kostenbesparingen zijn alleen te realiseren als de data schoon blijven. Een organisatie kan de data op orde houden door onder andere een visie te vormen en taken en verantwoordelijkheden voor databeheer te beleggen. Bijkomende mogelijkheden zijn het aanscherpen van opvoer-, wijzigings- en verwijderingsprocedures. Daarnaast het gebruik van de juiste IT-hulpmiddelen voor maandelijkse monitoring, actief onderhoud van bedrijfsregels en het opvoeren of wijzigen van masterdata. Dit alles kan als add-on op het bestaande ERP-systeem of losstaand geïmplementeerd worden. Dit artikel gaat daar verder niet op in.
Een onderdeel van het schoon worden en houden van de data is werken aan continue verbetering. In het initiële datakwaliteitsonderzoek zijn bedrijfsregels opgesteld. Deze zijn echter aan verandering onderhevig door hernieuwde inzichten en wijzigingen in en om de organisatie. De bedrijfsregels dienen hier stelselmatig op aangepast te worden. Daarnaast wordt het interessant om verder te gaan met het schonen van minder kritieke zaken op het moment dat de kritieke zaken opgelost zijn. Op deze manier verhoogt een organisatie stap voor stap de datakwaliteit.
Conclusie
In dit artikel hebben we uitgelegd waarom het hebben van goede data belangrijk is om de operationele en administratieve kosten te verlagen en hoe organisaties vervolgens de datakwaliteit kunnen verbeteren. Dit kunnen zij namelijk doen door de data in hun IT-systemen op orde te brengen. Het definiëren en toepassen van de juiste regels en het valideren daarvan neemt een centrale plaats in bij het datakwaliteitsonderzoek en de schoning van de data.
Ook zien wij dat 100% datakwaliteit een mooi streven is, maar in de praktijk is dit niet realistisch. Hoe goed de processen ook op orde zijn, altijd kunnen zich ad-hocincidenten voordoen, zoals een onverwachte organisatiewijziging, of er kan onopgemerkt een fout zijn gemaakt tijdens de invoer. Hoe dan ook: hoe beter de datakwaliteit, hoe gezonder de bedrijfsvoering! Een mooi gevolg is dat de operationele en administratieve kosten hierdoor lager uitvallen. Datakwaliteit: een win-winsituatie!
Literatuur
[BuRG03] Business Rules Group, Business Rules Manifest: De grondbeginselen van onafhankelijke regels, Versie 2.0, 1 november 2003, www.BusinessRulesGroup.org
[Jonk12] R.A. Jonker RE RA, Datakwaliteitsonderzoek, Compact, 2012/2.
[Laws13] Loraine Lawson, Interview with Ted Friedman: How to Measure the Cost of Data Quality Problems, 5 april 2013, http://www.itbusinessedge.com/interviews/how-to-measure-the-cost-of-data-quality-problems.html
[Rowe11] Nathaniel Rowe, Turbo-charge your ERP-system with High Quality Master Data, Aberdeen Group, juli 2011.
[Zijls13] Jikke Zijlstra, Uitvoering huurverhoging moeilijk, NOS, 5 april 2013, http://nos.nl/artikel/492265-uitvoering-huurverhoging-moeilijk.html