




Voor organisaties en overheden is het van groot belang om de continuïteit van de bedrijfsprocessen en de onderliggende IT-systemen te waarborgen. Veel organisaties hebben in het kader van businesscontinuïteit back-upoplossingen geïmplementeerd in de vorm van tapeback-ups. Tapes hebben echter verschillende nadelen, waaronder de beperkte snelheid waarmee informatie kan worden weggeschreven of worden ingelezen, en de noodzaak om de tapes naar een veilige plaats te brengen.
Door het toepassen van een back-upoplossing op basis van Storage Area Networks (SAN’s) worden deze nadelen weggenomen en kunnen data direct worden geback-upt wanneer deze worden gemaakt.
Bij de implementatie van een back-upoplossing op basis van SAN’s zijn inrichtingskeuzen te maken die mede bepaald worden door de vereisten ten aanzien van aspecten als beschikbaarheid, onderhoudbaarheid, kostenniveau en ten aanzien van de huidige, bestaande SAN-omgeving. In dit artikel gaan wij in op deze ontwerpkeuzen en de risico’s en maatregelen die hieraan verbonden zijn.
Inleiding
Explosieve datagroei, intensivering van IT en 24/7 bedrijfsvoering zorgen ervoor dat de continuïteit van bedrijfsprocessen sterk afhankelijk is geworden van het functioneren van IT-systemen. Het implementeren van de juiste maatregelen om data en applicaties (weer) beschikbaar te maken na calamiteiten (Disaster Recovery), kan langdurige stagnatie of blokkering van bedrijfsprocessen voorkomen. De afgelopen decennia was tapeback-up de de facto Disaster Recovery (DR)-oplossing om organisaties te wapenen tegen dataverlies. Tegenwoordig sluit deze technologie niet meer aan op de beschreven ontwikkelingen met als voornaamste oorzaken: langdurige hersteltijden van data (RTO – Recovery Time Objective) en mogelijk dataverlies (RPO – Recovery Point Objective). De beschreven ontwikkelingen waarbij bedrijfsprocessen in belangrijke mate afhankelijk zijn van het functioneren van de faciliterende IT-systemen, vereisen minimale hersteltijden en minimaal dataverlies. Om aan deze DR-eisen te kunnen voldoen zal andere technologie moeten worden gehanteerd dan (uitsluitend) conventionele tapeback-up.
Veel organisaties maken tegenwoordig gebruik van Storage Area Networks (SAN’s) voor de centrale opslag van belangrijke data. Door DR-oplossingen in te richten op basis van SAN’s kunnen RTO en RPO sterk verbeterd worden, ten gunste van de continuïteit van bedrijfsprocessen.
In moderne datareplicatieoplossingen is nog steeds ruimte voor tapes. In de zogenaamde disk-to-disk-to-tape back-up strategy (D2D2T) worden periodiek de data van de back-updisk weggeschreven naar tape en vervolgens wordt deze tape extern opgeslagen als extra zekerheid.
In dit artikel worden back-uptechnologieën beschreven op basis van SAN’s en we beschrijven de te maken implementatiekeuzen per technologie en formuleren randvoorwaarden voor de verbetering van RTO en RPO.
Een IT-adviseur kan organisaties ondersteunen met het maken van de keuze voor een passende SAN-oplossing op basis van een onafhankelijke blik op de mogelijkheden en onmogelijkheden van de verschillende back-uptechnologieën.
Ontwikkeling van dataopslag
Sinds de opkomst van computers heeft dataopslag een flinke ontwikkeling doorgemaakt. Ten tijde van de introductie van computers (zoals de IBM-mainframes) was dataopslag voornamelijk lokaal ingericht. Dit type dataopslag wordt ook wel Direct Attached Storage (DAS) genoemd. In een DAS-omgeving beschikt iedere computer (server) over eigen dataopslagfaciliteiten. In de jaren tachtig werd het computernetwerk geïntroduceerd, wat het mogelijk maakte om onderling gegevens tussen computers uit te wisselen. Fabrikanten maakten het tijdens deze netwerkrevolutie tevens mogelijk om dataopslag in een netwerk te delen. Dit type dataopslag wordt ook wel Network Attached Storage (NAS) genoemd en centraliseert daarmee de dataopslag (in een netwerk). In de jaren negentig werd dataopslag fysiek ontkoppeld van servers door de opslag centraal in te richten en servers gebruik te laten maken van een Storage Area Network (SAN). Het SAN is een speciaal netwerk tussen servers en dataopslagsystemen, dat de centralisatie van dataopslag transparant maakt voor servers (de centralisatie is niet zichtbaar voor applicaties op de servers). Een SAN-oplossing biedt een speciaal netwerk waardoor het reguliere datanetwerk niet belast wordt met intensieve lees- en schrijfoperaties op (grote hoeveelheden) data, wat een aandachtspunt vormt voor NAS-oplossingen. Een SAN wordt uitsluitend gebruikt voor het transport van schrijf-/leesoperaties op de gecentraliseerde data.
Een SAN heeft een aantal interessante voordelen ten opzichte van eerdere technologieën:
- centralisatie van databeheer;
- centralisatie van back-up/DR-oplossingen;
- vereenvoudiging van data/server-migratie.
De opkomst van servervirtualisatie[Bij servervirtualisatie is er een logische ontkoppeling tussen hardware en het besturingssysteem dat de hardware gebruikt. Hierdoor kunnen meerdere besturingssystemen tegelijk de hardware gebruiken, waardoor er meerdere systemen gebruik kunnen maken van de beschikbare hardware.] onderstreept de voordelen van een SAN. Virtualisatietechnologie steunt veelal op SAN-technologie om daarmee het besturingssysteem, applicaties en data (logische server) compleet te ontkoppelen van de gebruikte hardware (fysieke server). Wanneer een fysieke server faalt, faciliteert het SAN de mogelijkheid om de logische server te migreren naar een andere beschikbare fysieke server.
In figuur 1 wordt het verschil tussen de beschreven dataopslagmethoden geïllustreerd. De figuur toont de verschillen aan de hand van de interactie tussen een applicatie en de verschillende dataopslagmethoden.
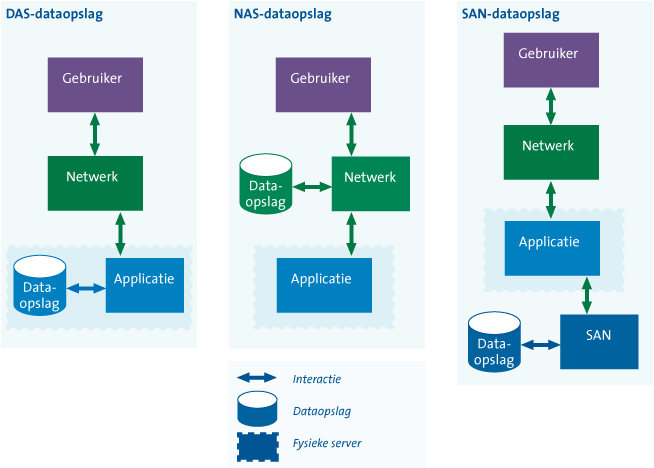
Figuur 1. Positie van dataopslag verschilt per technologie (bron: KPMG).
Classificatie van DR-oplossingen naar RTO- en RPO-prestaties
Verschillende DR-oplossingen bieden verschillende RPO- en RTO-mogelijkheden. Zoals eerder beschreven kunnen data moeilijk snel hersteld worden door middel van tapeback-uptoepassingen. In figuur 2 worden verschillende DR-oplossingen uitgezet in prestaties (RTO en RPO) en bijbehorende bedrijfswaarde van data/applicaties.
Zo is in de figuur te zien dat tapeback-up, waarbij de tapes in hetzelfde datacenter zijn opgeslagen als waarin de originele data zijn opgeslagen, een lage score heeft voor RTO en RPO (zie 1 in figuur 2). Bij een calamiteit, waarbij het datacenter niet beschikbaar is, zijn er geen voorzieningen geregeld om de data te kunnen herstellen. Indien tapes echter op een externe locatie worden opgeslagen, kan men met de tweede oplossing data herstellen op de externe locatie (zie 2 in figuur 2). Bij de derde oplossing worden data gerepliceerd naar een externe locatie, deze locatie beschikt echter niet over de nodige serverhardware om data te kunnen verwerken (zie 3 in figuur 2). In tegenstelling tot de tweede oplossing maakt oplossing 3 geen gebruik van tapes, waardoor de hersteloperatie sneller kan worden uitgevoerd.
Vanaf de vierde oplossing zijn er twee datacenters beschikbaar met ieder een SAN-omgeving en de nodige serverhardware. Data worden gerepliceerd tussen de SAN’s en kunnen hierdoor op twee locaties opgeslagen en gebruikt worden, wat een aanzienlijke winst oplevert voor RTO en RPO. Een bijkomend voordeel van een back-upvoorziening op basis van SAN’s is dat er geen tapeback-ups meer hoeven te worden getransporteerd naar een back-uplocatie, waardoor de vertrouwelijkheid van de gegevens beter is gewaarborgd.
Het verschil tussen de oplossingen 4 tot en met 6 is de respectievelijke timing van de datareplicatie. Bij asynchrone replicatie zullen data op vaste tijdstippen worden gerepliceerd tussen de SAN-omgevingen (bijvoorbeeld nachtelijke back-upoperaties) (zie 4 in figuur 2). In geval van synchrone datareplicatie zullen data direct worden gerepliceerd wanneer deze gecreëerd worden (zie 5 in figuur 2). De laatste oplossing in de figuur levert de beste RTO- en RPO-resultaten, aangezien naast synchrone replicatie tevens een logboek wordt bijgehouden met datawijzigingen (zie 6 in figuur 2). Deze oplossing is relatief kostbaar doordat er redundante apparatuur beschikbaar moet zijn en er een kostbare breedband-internetverbinding aanwezig moet zijn. Hierdoor kan men eerder gerepliceerde versies van data herstellen, bijvoorbeeld in het geval dat de laatste versie foutief is kan men een eerdere versie gebruiken. Deze logboekfunctionaliteit wordt ook wel aangeduid met Continuous Data Protection (CDP).
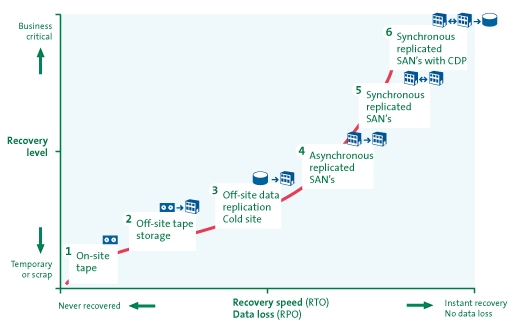
Figuur 2. Verschillende DR-oplossingen uitgezet tegen RTO/RPO en toenemende continuïteitseisen (bron: [Jone07]).
Vanaf oplossing 3 wordt gebruikgemaakt van datareplicatie en kan SAN-technologie worden ingezet om betere resultaten te behalen voor RTO en RPO. Om deze oplossingen te kunnen implementeren kunnen data tussen twee SAN-omgevingen worden gerepliceerd door middel van drie verschillende technologieën. De drie technologieën verschillen van elkaar in opzet:
- Servergebaseerde replicatie (Host Based Replication – HBR). Replicatie van data wordt geïnitieerd door de server die de data verwerkt. De server zal zelf de eigen data repliceren naar een server op een secundaire locatie (uitwijk datacenter).
- Netwerkgebaseerde replicatie (Network Based Replication – NBR). Replicatie van data wordt geïnitieerd in het SAN. Data die via het SAN wordt opgeslagen, wordt in het SAN gerepliceerd naar het SAN op een secundaire locatie.
- Opslagclustergebaseerde replicatie (Array Based Replication – ABR). Replicatie van data wordt geïnitieerd op het opslagcluster (systeem waar grote hoeveelheid data wordt opgeslagen). Het cluster repliceert de opgeslagen data naar een cluster op een secundaire locatie.
In figuur 3 zijn de verschillende technologieën schematisch weergegeven.
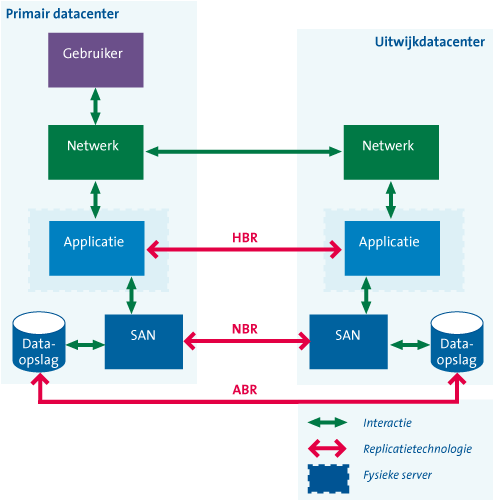
Figuur 3. Positie van de drie verschillende replicatietechnologieën (bron: KPMG).
Het is belangrijk om inzicht te hebben in de sterke en zwakke eigenschappen per technologie. In de volgende paragraaf worden deze sterke en zwakke eigenschappen per technologie beschreven.
SAN-datareplicatietechnologieën
In deze paragraaf worden de sterke en zwakke eigenschappen van de drie technologieën beschreven. De sterke en zwakke eigenschappen zijn beoordeeld aan de hand van relevante kwaliteitsattributen. De kwaliteitsattributen welke wij relevant achten voor de beoordeling zijn: beschikbaarheid, prestatie en onderhoudbaarheid. Verder worden de verschillende technologieën beoordeeld op volwassenheid, marktpenetratie en kosten.
Allereerst volgt een korte beschrijving van de relevante kwaliteitsattributen:
- Beschikbaarheid: de mate waarin technologie gebruikt kan worden en toegankelijk is voor gebruikers.
- Prestatie: de mate waarin technologie met de gewenste snelheid opgedragen operaties kan verwerken.
- Onderhoudbaarheid: de mate waarin technologie efficiënt en effectief onderhouden kan worden.
- Volwassenheid: de mate van volwassenheid van de technologie. Hierbij wordt voornamelijk gekeken naar de mate van ontwikkeling en standaardisatie van technologie.
- Marktpenetratie: de mate waarin de technologie wordt toegepast onder haar potentiële gebruikers.
- Kosten: de initiële en operationele kosten die een gebruiker maakt om de technologie te kunnen gebruiken.
Samenvattend ontstaat het in tabel 1 gegeven beeld van de verschillende replicatietechnologieën. In deze tabel worden de technologieën op basis van de kwaliteitsattributen met elkaar vergeleken. De iconen met een plus geven aan dat wij aspecten hebben aangetroffen, die leiden tot een positief resultaat voor de betreffende kwaliteitsattributen. De iconen met een kruis geven aan dat technologieën aandachtspunten hebben voor de betreffende kwaliteitsattributen. Hierna worden de resultaten in de tabel verder toegelicht per replicatietechnologie.
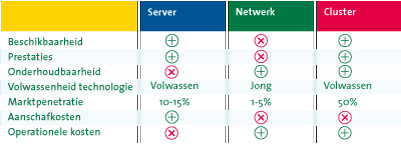
Tabel 1. Replicatietechnologieën beoordeeld op kwaliteitsattributen (bron: KPMG).
Servergebaseerde replicatie
Bij servergebaseerde replicatie ligt de verantwoordelijkheid van de replicatie bij de servers die de data verwerken. De verschillende servers zullen daarom ook worden uitgerust met software (en hardware) om data te kunnen repliceren. Belangrijk voordeel van deze gedistribueerde replicatie is dat bij falen van replicatie dit niet per definitie consequenties heeft voor de replicatiewerking op andere servers. Dit voordeel komt ten goede aan de beschikbaarheid van deze technologie.
Gezien het distributieve karakter van de replicatietechnologie levert dit tevens voordelen op ten aanzien van prestaties. De totale datareplicatieoperatie van alle bedrijfsdata wordt verdeeld over de verschillende servers. Dit zorgt ervoor dat tevens de replicatie-inspanning over de servers wordt verdeeld. Een interessant voordeel hiervan is dat deze gedistribueerde technologie ook tot schaalbaarheidsvoordelen leidt. Met andere woorden, de groei van data of van het aantal servers leidt niet direct tot prestatieproblemen van het netwerk of storage clusters.
Een knelpunt van gedistribueerde oplossingen ligt op het vlak van beheersing. Voor servergebaseerde replicatie is efficiënt beheer een uitdaging. De replicatie vindt per server plaats, en zal dus ook per server onderhouden moeten worden. Wanneer geen centrale beheertooling is ontwikkeld om de oplossingen per server aan te sturen, vormt dit een belangrijke uitdaging voor regulier beheer en onderhoud.
Volgens [Gart09] ligt de marktpenetratie van de technologie op 10-15%, waaruit geconcludeerd kan worden dat de technologie niet op grote schaal wordt gebruikt. Desondanks zijn de geboden oplossingen wel volwassen, wat de werking van de technologie robuust en betrouwbaar maakt.
Kostentechnisch is de aanschaf van beschikbare oplossingen relatief laag wanneer we deze vergelijken met de andere technologieën. De operationele kosten worden voor een belangrijk deel gevormd door de nodige beheerinspanningen. Deze zijn relatief hoog indien centrale beheertooling ontbreekt voor de oplossing. In dat geval zal onderhoud en beheer per server moeten worden uitgevoerd. Echter, er bestaan voldoende oplossingen waarbij beheertooling wordt geleverd om een geheel serverpark centraal te kunnen beheren. Gezien de gespreide aard van de technologie en de verschillen in beheertooling hebben wij de operationele kosten opgemerkt als aandachtspunt.
Netwerkgebaseerde replicatie
Netwerkgebaseerde replicatie wordt uitgevoerd in het SAN (tussen servers en storage clusters). Alle data die servers opslaan in het storage cluster worden in het SAN gerepliceerd naar verschillende storage clusters. Deze technologie steunt op replicatiefunctionaliteit in een centraal schakelpunt in het netwerk tussen servers en storage clusters, wat ervoor zorgt dat het niet beschikbaar zijn van de technologie leidt tot algehele uitval van datareplicatie. De uitdaging bij netwerkgebaseerde replicatie ligt bij redundante uitvoering van de technologie om dit risico te mitigeren.
Daarop voortbordurend kan gesteld worden dat het centrale karakter van deze technologie tevens prestatieknelpunten introduceert. Alle datareplicatie en daarmee de nodige verwerking van data verloopt via het centrale schakelpunt in het SAN. De hoeveelheid data die wordt opgeslagen door middel van een SAN, groeit jaarlijks met zo’n 20% of meer ([Kapl08]). Deze sterke groei van data impliceert dat het centrale schakelpunt steeds meer data zal moeten repliceren. Gezien het gecentraliseerde karakter kan dit tot prestatieproblemen leiden, wanneer aan de technologie meer data worden aangeboden dan deze kan verwerken (repliceren).
Centralisatie van technologie introduceert het nodige beheergemak. Doordat alle data worden gerepliceerd door een centraal schakelpunt in het SAN, kunnen deze ook centraal worden beheerd en onderhouden. Dit zorgt voor de nodige efficiëntie in het beheer van datareplicatie.
Volgens [Gart09] ligt de marktpenetratie van de technologie op 1-5%, waaruit geconcludeerd kan worden dat de technologie op zeer kleine schaal wordt toegepast. Een reden hiervoor is dat de technologie nog niet lang bestaat en daardoor ook nog niet is uitgekristalliseerd. Over het algemeen betekent dit dat de geboden oplossingen nog volop evolueren.
De aanschaf van netwerkgebaseerde oplossingen is relatief duur vergeleken met de andere twee technologieën. De operationele kosten zijn theoretisch laag, gezien de beheerinspanningen die gericht zijn op een centraal schakelpunt, dat beheerd en onderhouden wordt. Voor de geboden oplossingen bestaan echter licentiestructuren die gekoppeld zijn aan de hoeveelheid data die gerepliceerd worden. Dergelijke licentiestructuren kunnen de daadwerkelijke operationele kosten doen stijgen.
Opslagclustergebaseerde replicatie
Wanneer replicatie plaatsvindt in het opslagcluster worden data gerepliceerd door het opslagcluster zelf. Data worden gerepliceerd door zogenaamde opslagcontrollers in het cluster. Deze controllers sturen één of meer schijven aan in het cluster en zijn verantwoordelijk voor het aanleveren en opslaan van data op de betreffende schijven. Deze controllers kunnen uitgerust worden met replicatiemogelijkheden, wat resulteert in een replicatietechnologie die volledig is geïntegreerd in het opslagcluster. Gezien het feit dat een opslagcluster veelal is uitgerust met meerdere controllers, wordt daarmee de totale replicatieoperatie verdeeld over de verschillende controllers. Deze verdeling zorgt ervoor dat uitval van een controller niet direct leidt tot het compleet falen van alle datareplicatie, wat voordelig is voor de beschikbaarheid van dergelijke technologie.
Deze verdeling over controllers levert ook prestatievoordelen, gezien de situatie dat de datareplicatie-inspanning is verdeeld over het aantal aanwezige controllers in het opslagcluster. Daarbij kan opslagclustergebaseerde replicatie verlopen via een separaat netwerk tussen de primaire en redundante opslagclusters. Hiermee kan de reguliere datastroom tussen servers en opslagclusters worden gescheiden van het replicatieverkeer tussen de opslagclusters. Deze scheiding zorgt voor minder belasting van het SAN, waardoor de technologie meer data kan verwerken en daarmee meer ruimte heeft om op te schalen (in data en aantal aangesloten servers).
Opslagclustergebaseerde replicatie wordt veelal geboden als extra dienst bij het afgenomen opslagcluster. Hierdoor integreert de tooling voor datareplicatie veelal met de aanwezige tooling om het opslagcluster te kunnen beheren. Dit zorgt voor centralisering van tooling en daarmee tot mogelijkheden voor efficiënt onderhoud en beheer.
Volgens [Gart09] ligt de marktpenetratie van de technologie op 50%, waaruit geconcludeerd kan worden dat de technologie breed gebruikt wordt in de markt. Een reden hiervoor is dat de technologie al enige tijd wordt geboden en daarmee volwassen en uitgekristalliseerd is.
De aanschaf van opslagclustergebaseerde oplossingen is relatief duur in vergelijking tot de andere twee technologieën. De operationele kosten zijn theoretisch laag, gezien beheer en onderhoud uitgevoerd kunnen worden in de bestaande tooling van het opslagcluster. Dergelijke tooling waarmee centraal beheer kan worden uitgevoerd voor alle SAN-data maakt efficiënt beheer en onderhoud mogelijk.
Specifiek voor opslagclustergebaseerde replicatietechnologieën merken wij als belangrijk nadeel op dat toepassing kan leiden tot vendor lock-in. De oplossingen worden veelal geboden door de leveranciers van de opslagclusters zelf en bieden vaak ondersteuning voor een beperkt aantal opslagclusters. De geboden replicatieoplossingen beperken daardoor de keuzemogelijkheden voor andere opslagclusters waarmee data worden gerepliceerd.
Organisaties zullen voor deze oplossing kiezen wanneer ze een homogeen SAN-landschap hebben. De genoemde geïntegreerde oplossing van één leverancier kan ook als een voordeel worden gezien doordat er slechts met één leverancier zaken hoeft te worden gedaan voor de storage- en back-upoplossingen.
Infrastructurele vereisten voor replicatie
In het kader van de continuïteit van de bedrijfsprocessen is het veiligstellen van de data een belangrijk aspect. Het implementeren van DR-oplossingen gebaseerd op SAN-datareplicatie vereist de nodige aandacht voor de IT-infrastructuur, waar de technologie onderdeel van uitmaakt. Zo dient aandacht te worden besteed aan extra servercapaciteit. Indien de DR-oplossing data beschikbaar maakt op een externe locatie, dient de locatie te zijn ingericht met de nodige fysieke servers om beschikbare data te kunnen uitvoeren (en daarmee de ondersteunde bedrijfsprocessen te continueren). Verschillende oplossingen zijn hierbij mogelijk, zoals het inzetten van de testomgeving voor back-up, afspraken met leveranciers over het tijdig leveren van back-upapparatuur en het gebruik van virtualisatie voor het installeren van een nieuwe virtuele server.
Verder dient men aandacht te besteden aan de benodigde netwerkcapaciteit. Zo zal het netwerk gelegen tussen de primaire en de uitwijklocatie moeten voorzien in voldoende bandbreedte om de stroom aan replicatiedata te kunnen verwerken. Indien deze bandbreedte onvoldoende is, zal data niet tijdig worden gerepliceerd, waardoor verwachte/overeengekomen RPO niet wordt gehaald.
De uitdaging voor IT ligt niet uitsluitend op het initieel inrichten van bovengenoemde infrastructurele aandachtspunten. Binnen IT zal capaciteitsbeheer moeten worden ingericht om beheerders op structurele wijze de huidige capaciteit te laten spiegelen met de benodigde capaciteit, en hier de planning van beheer en onderhoud op af te stemmen. Dergelijk capaciteitsbeheer voorkomt dat intensivering van IT (bijvoorbeeld door verdere automatisering van bedrijfsprocessen) onopgemerkt leidt tot verslechtering van gestelde RTO/RPO-afspraken.
Naast capaciteitsbeheer is een DR-plan essentieel om voorbereid te zijn op mogelijke calamiteiten. Een dergelijk plan beschrijft preventieve, detectieve en correctieve maatregelen aan de hand van potentiële dreigingen en hun kans op ontstaan. De inrichting van SAN-datareplicatie is een maatregel om te voorkomen dat data verloren gaan (preventief) en te ondersteunen bij snelle beschikbaarheid van data (correctief). Het plan dient ook te beschrijven wat de werkprocedures zijn om bij een bepaalde calamiteit op een juiste manier te handelen. Zo zal bijvoorbeeld systeembeheer de nodige werkzaamheden moeten uitvoeren om ervoor te zorgen dat gerepliceerde data gebruikt kunnen worden op een uitwijklocatie (zoals: systemen activeren op de uitwijklocatie, SAN op uitwijklocatie primair opslagcluster maken, etc.). Dergelijke procedures dienen te worden beschreven in het plan en periodiek te worden getest om daarmee te evalueren of overeengekomen RTO/RPO haalbaar zijn.
Conclusie
Door de groeiende afhankelijkheid van bedrijfsprocessen van IT neemt het belang van data recovery toe. De traditionele vorm van back-ups op basis van back-uptapes voldoet vaak niet meer aan de eisen die de bedrijfsvoering stelt aan businesscontinuïteit, vanwege langdurige hersteltijden van data en veel dataverlies.
Het implementeren van de juiste maatregelen om data en applicaties (weer) beschikbaar te maken na calamiteiten (Disaster Recovery), kan langdurige stagnatie of blokkering van bedrijfsprocessen voorkomen. In het kader van Disaster Recovery is het veiligstellen van de data van groot belang.
In dit artikel hebben we een drietal technieken beschreven voor datareplicatie op basis van SAN-opslag. Het voordeel van datareplicatie op basis van een SAN is dat hiermee korte hersteltijden en zeer beperkt dataverlies mogelijk worden. De drie technieken voor datareplicatie op basis van SAN-opslag zijn:
- Servergebaseerde replicatie. Replicatie van data wordt geïnitieerd door de server die de data verwerkt. De server zal zelf de eigen data repliceren naar een server op een secundaire locatie (uitwijk datacenter).
- Netwerkgebaseerde replicatie. Replicatie van data wordt geïnitieerd in het SAN. Data die via het SAN wordrn opgeslagen, worden in het SAN gerepliceerd naar het SAN op een secundaire locatie.
- Opslagclustergebaseerde replicatie. Replicatie van data wordt geïnitieerd op het opslagcluster, waar data daadwerkelijk worden opgeslagen. Het cluster repliceert de opgeslagen data naar een cluster op een secundaire locatie.
Deze drie technologieën hebben hun specifieke voor- en nadelen. Belangrijk is dat organisaties de verschillende voor- en nadelen tegen elkaar afwegen in de eigen situatie. De keuze voor de juiste technologie(en) is afhankelijk van het ingerichte applicatielandschap en de IT-infrastructuur. Essentieel is dat er naast replicatietechnologie voldoende oog dient te zijn voor de dynamiek binnen IT-omgevingen. Wijzigingen en organische groei binnen IT-omgevingen leiden ertoe dat maatregelen niet meer aansluiten bij de gestelde continuïteitseisen. IT-organisaties zullen daarom de eigen processen voldoende moeten inrichten om geïmplementeerde maatregelen tijdig te testen, te evalueren en aan te scherpen om te kunnen blijven voldoen aan de continuïteitseisen van de organisatie.
Literatuur
[Gart09] Gartner research, Hype cycle for storage hardware technologies, 2009, G00168190, Gartner, 2009.
[Jone07] Richard Jones, Survival of the Fittest: Disaster Recovery Design for the Data Center, Burton Group, 2007.
[Kapl08] James M. Kaplan, Rishi Roy en Rajesh Srinivasaraghavan, Meeting the demand for data storage, McKinsey & Company, 2008.